







回顾构建倒排索引的主要步骤
- 收集待建索引的文档
- 对这些文档中的文本进行词条化
- 对第二步产生的词条进行语言学处理,得到词项
- 根据词项对所有文档建立索引
所谓词条化(tokenization):将原始的字符流转换成一个个词条(token)的过程
文档分析及编码转换
生成字符序列
语言识别,编码方式识别,文件格式等处理,生成字符序列
文档单位的选择
合理的选择“索引粒度”:
- 如果索引粒度太小,那么由于词项散步在多个细粒度文档中,我们就很可能错过那些重要的段落,也就是说此时正确率高而召回率低
- 如果索引粒度太大,我们就很可能找到很多不相关的匹配结果,即正确率低而召回率高
词项集合的确定
词条化
定义好文档单位后,词条化是将给定的字符序列拆分成一系列子序列的过程,其中每个子序列称为一个词条(token)
实际检索中分词:
- 查询和文档切分采用一致的分词系统
- 保证分词速度
- 一般原则,没把握的情况下细粒度优先,保证召回率
- 多粒度并存
去除停用词
某些情况下,一些常见词在文档和用户需求进行匹配时价值并不大,需要彻底从词汇表中去除。这些词称为停用词(stop word)
常用生成停用词表的方法:
将词项按照文档集频率(collection frequency,每个词项在文档集中出现的频率)从高到低排列,然后手工选择那些语义内容与文档主题关系不大的高频词作为停用词。停用词表中的每个词将在索引过程中被忽略
在信息检索系统不断发展的历程中,有从大停用词表(200~300个词)到小停用词表(7~12个词)最后到不用停用词的趋势。Web搜索引擎通常都不用停用词表
词项归一化
词条归一化(token normalization)就是将看起来不完全一致的多次词条归纳称一个等价类,以便在它们之间进行匹配的过程
最常规的做法是隐式地建立等价类
- 重音及变音符号问题 解决方法:通过在词条归一化时去掉变音符号
- 大小写转换问题 解决方法:将所有的字母转换成小写
- 英语中的其他问题
- 其他语言的问题
词干还原和词形归并
词干还原和词形归并的目的都是为了减少词的屈折变化形式,并且有时会将派生词转化为基本形式。比如:
am, are, is => be
然而,词干还原和词形归并这两个术语所代表的意义是不同的。词干还原指的是一个很粗略的去除单词两端词缀的启发式过程,并且希望大部分时间它能达到这个正确目的,这个过程也常常包括去除派生词缀。而词形归并通常指利用词汇表和词形分析来去除屈折词缀,从而返回词的原形或词典中的词的过程,返回的结果称为词元(lemma)。假定给定词条saw,词干还原过程可能返回仅s,而词形归并过程将返回see或saw,当然具体返回哪个词取决于在当前上下文中saw到底是动词还是名词。这两个过程的区别还在于:词干还原在一般情况下会将多个派生相关词合并在一起,而词形归并通常只将同一词元的不同屈折形式进行合并。词干还原和词形归并往往通过在索引过程中增加插件程序的方式来实现,这类插件程序有很多,其中既有商业软件也有开源软件
基于跳表的倒排记录表快速合并算法
skip list:时间复杂度O(m + n)的基本合并算法的优化
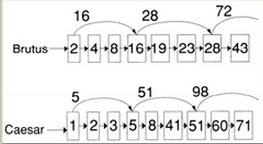
放置跳表指针的位置:
这里存在一个指针个数和比较次数之间的折中问题。跳表指针越多意味着跳跃的步长越短,那么在合并过程中跳跃的可能性也更大,但同时这也意味着需要更多的指针比较次数和更多的存储空间。跳表指针越少意味着更少的指针比较次数,但同时也意味着更长的跳跃步长,也就是说意味着更少的跳跃机会。放置跳表指针位置的一个简单的启发式策略是:在每个根号p处均匀放置跳表指针,其中p是倒排记录表的长度。
含位置信息的倒排记录表及短语查询
对长度N和M的有序数组,一般来说,在做归并的时候,其时间复杂度为O(M+N)。在理想情况下(如M和N都很大时),O(M+N)应该是一个很小的复杂度。但搜索引擎的情况往往并不是这样,很多时候都会遇到一个很小的有序数组(比如,由其他很多条件计算而来)和一个很大的有序数组之间的AND运算。在这种情况下,O(M+N)的时间可能比O(M * logN)的时间要大
二元词索引
处理短语查询的一个办法就是将文档中每个接续词对看成一个短语。例如文本Friends,Romans,Countrymen会产生如下的二元接续词(biword):
firends romans
romans countrymen
索引构建时,将每对词看成一个词项放到词典中
查询 stanford university palo alto分成如下的布尔查询:“standford university” AND “university palo” AND “palo alto”
扩展的双词(Extended Biword)
对待索引文档进行词性标注,将词项进行组块,每个组块包含名词(N)和冠词/介词(X),称具有NX*N形式的词项序列为扩展双词
位置信息索引
在位置信息索引中,对每个词项,以如下方式存储倒排记录:
文档ID: <位置1,位置2,...>为了处理短语查询,仍然需要访问每个词项的倒排记录表。像以往一样,这里的倒排记录表合并操作仍然可以采用最小文档频率优先的策略,从而可以限制后续合并的候选文档的数目。具体的合并过程同样可以采用前面提到的各种技术来实现,但是这里不只是简单地判断两个词项是否出现在同一文档中,而且还需要检查它们的出现位置关系与查询当中是否保持一致。这就需要计算出词之间的偏移距离















 2002
2002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









