







(1). 考虑利用如下带有跳表指针的倒排记录表
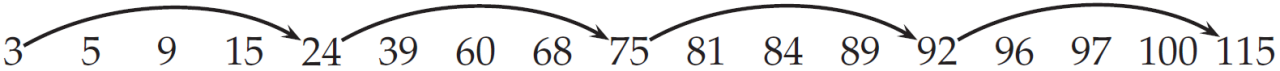
和两个中间结果表(如下所示,不存在跳表指针)分别进行合并操作。
3 5 9 96 99 100 101
25 60 120 150
采用教材《Introduction to Information Retrieval》第37页Figure 2.10中所描述的基于跳表指针(skip pointers)的倒排记录表(postings lists)合并算法,请问:
a.跳表指针实际跳转的次数分别是多少(也就是说,指针p1的下一步将跳到skip(p1))?
b.当两个表进行合并时,倒排记录之间的比较次数分别是多少?
c.如果不使用跳表指针,那么倒排记录之间的比较次数分别是多少?
a.跳表指针实际跳转的次数分别是多少(也就是说,指针p1的下一步将跳到skip(p1))?
跳表指针的跳转算法为:如果当前p1节点拥有跳表指针,当p1.val小于p2.val时不断向后跳转。(具体比较过程可以见第2题,或者看代码实现)
1、和3 5 9 96 99 100 101进行合并操作:
答:2次,<24, 75>, <75, 92>
比较到24与96时,24拥有skip指针且75 < 96,因此第1次跳转;
75拥有skip指针且92 < 96,因此第2次跳转;
92拥有skip指针但是115 > 96,结束跳转。
2、和25 60 120 150进行合并操作:
答:3次,< 3, 24>, <75, 92>, <92, 115>
比较到3与25时,3拥有skip指针且24 < 25,因此第1次跳转;
24拥有skip指针且75 > 25,结束跳转。
比较到75与120时,75拥有skip指针且92 < 120,因此第2次跳转;
92拥有skip指针且115 < 120,因此第2次跳转;
115无skip指针,结束跳转。
b.当两个表进行合并时,倒排记录之间的比较次数分别是多少?
当p1.val = p2.val时,加入答案列表,并且p1p2同时后移;当p1.val < p2.val时,如果p1无skip指针,则向后移,否则根据第1题的跳表指针算法向后移动p1指针;反之同理。(具体过程可以看代码实现)
1、和3 5 9 96 99 100 101进行合并操作:
答:13次,比较顺序如下:<p1.val, p2.val>
[‘< 3, 3>’, ‘<5, 5>’, ‘<9, 9>’, ‘<15, 96>’, ‘<24, 96>’, ‘<75, 96>’, ‘<92, 96>’, ‘<115, 96>’, ‘<96, 96>’, ‘<97, 99>’, ‘<100, 99>’, ‘<100, 100>’, ‘<115, 101>’]
2、和25 60 120 150进行合并操作:
答:10次,比较顺序如下:<p1.val, p2.val>
[‘< 3, 25>’, ‘<24, 25>’, ‘<75, 25>’, ‘<39, 25>’, ‘<39, 60>’, ‘<60, 60>’, ‘<68, 120>’, ‘<75, 120>’, ‘<92, 120>’, ‘<115, 120>’]
c.如果不使用跳表指针,那么倒排记录之间的比较次数分别是多少?
1、和3 5 9 96 99 100 101进行合并操作:
答:18次,比较顺序如下:<p1.val, p2.val>
[‘< 3, 3>’, ‘<5, 5>’, ‘<9, 9>’, ‘<15, 96>’, ‘<24, 96>’, ‘<39, 96>’, ‘<60, 96>’, ‘<68, 96>’, ‘<75, 96>’, ‘<81, 96>’, ‘<84, 96>’, ‘<89, 96>’, ‘<92, 96>’, ‘<96, 96>’, ‘<97, 99>’, ‘<100, 99>’, ‘<100, 100>’, ‘<115, 101>’]
2、和25 60 120 150进行合并操作:
答:18次,比较顺序如下:<p1.val, p2.val>
[‘< 3, 25>’, ‘<5, 25>’, ‘<9, 25>’, ‘<15, 25>’, ‘<24, 25>’, ‘<39, 25>’, ‘<39, 60>’, ‘<60, 60>’, ‘<68, 120>’, ‘<75, 120>’, ‘<81, 120>’, ‘<84, 120>’, ‘<89, 120>’, ‘<92, 120>’, ‘<96, 120>’, ‘<97, 120>’, ‘<100, 120>’, ‘<115, 120>’]
(2). 下面给出的是一个位置索引的一部分,格式为:
<position1, position2, …>; doc2: <position1, position2, …>; …
angels: 2: <36,174,252,651>; 4: <12,22,102,432>; 7: <17>;
fools: 2: <1,17,74,222>; 4: <8,78,108,458>; 7: < 3,13,23,193>;
fear: 2: <87,704,722,901>; 4: <13,43,113,433>; 7: <18,328,528>;
in: 2: < 3,37,76,444,851>; 4: <10,20,110,470,500>; 7: <5,15,25,195>;
rush: 2: <2,66,194,321,702>; 4: <9,69,149,429,569>; 7: <4,14,404>;
to: 2: <47,86,234,999>; 4: <14,24,774,944>; 7: <199,319,599,709>;
tread: 2: <57,94,333>; 4: <15,35,155>; 7: <20,320>;
where: 2: <67,124,393,1001>; 4: <11,41,101,421,431>; 7: <16,36,736>;
请问哪些文档和以下的查询匹配?其中引号内的每个表达式都是一个短语查询。
a.“angels fear”
b.“angels fear to tread”
c.“angels fear to tread”AND“fools rush in”
a. “angels fear”
- 符合查询的文档:
文档4中,angles - 12 fear - 13或angles - 432 fear - 433
文档7中,angles - 17 fear - 18
b. “angels fear to tread”
- 符合查询的文档:文档4中,angles - 12 fear - 13 to - 14 tread - 15
c. “angels fear to tread”AND“fools rush in”
-
“fools rush in”符合的文档:
文档2中,fools - 1 rush - 2 in - 3
文档4中,fools - 8 rush - 9 in - 10
文档7中,fools - 3 rush - 4 in - 5或fools - 13 rush - 14 in - 15 -
与第二组结果取AND,因此最终结果为文档4
(3). 阅读教材《Introduction to Information Retrieval》第37页Figure 2.10中所描述的基于跳表指针(skip pointers)的倒排记录表(postings lists)合并算法。要求在题(1)的例子上验证算法的正确性。
代码截图和详细的文字说明:
首先定义一个数据结构:
链表节点Node:
class Node:
def __init__(self, val):
self.val = val
self.next = None
self.skip = None
值得注意的是,添加了一个skip指针。如果该节点可以跳转,则skip指针指向下一个节点,否则为None
定义一个含跳表指针的链表:
其中包括了三个方法:
- 根据list添加节点
- 添加单节点
- 添加跳表指针
前两个方法为常见的链表算法。
class linkedListWithSkips:
def __init__(self):
self.head = None
self.length = 0
def addNodes(self, list):
# 将list中的元素添加到链表中
for i in list:
self.addNode(i)
def addNode(self, val):
# 添加一个节点
if self.head == None:
self.head = Node(val)
self.length += 1
else:
curr = self.head
while curr.next != None:
curr = curr.next
curr.next = Node(val)
self.length += 1
第三个方法实现如下:
首先根据链表长度计算出skip指针的跳转长度为interval = sqrt(length)
然后从第一个节点开始,每隔interval个节点指向下一个跳转节点。
def addSkips(self):
# interval为间隔,每个间隔之后添加一个skip指针
# interval的大小根据长度开根号决定
interval = math.floor(math.sqrt(self.length))
# 每隔interval个节点,添加一个skip指针
cur = self.head
curr = self.head
while curr.next != None:
for i in range(interval):
if curr.next != None:
curr = curr.next
else:
break
# 如果cur后存在interval个节点,则添加skip指针
if i == interval - 1:
cur.skip = curr
cur = curr
合并算法:(含跳表指针)
def intersectWithSkips(p1, p2):
ans = []
while p1 != None and p2 != None:
# 如果val相同,则加入答案,指针后移
if p1.val == p2.val:
ans.append(p1.val)
p1 = p1.next
p2 = p2.next
# val较小的指针,如果存在skip指针,则不断向后跳直到val较大为止
elif p1.val < p2.val:
# 存在skip指针,则不断向后比较
if p1.skip and p1.skip.val <= p2.val:
while p1.skip and p1.skip.val <= p2.val:
p1 = p1.skip
else:
p1 = p1.next
# 同上
elif p1.val > p2.val:
if p2.skip and p2.skip.val <= p1.val:
while p2.skip and p2.skip.val <= p1.val:
p2 = p2.skip
else:
p2 = p2.next
print('ans:', ans)
(不含跳表指针)
def intersectWithoutSkips(p1, p2):
ans = []
while p1 != None and p2 != None:
# 如果val相同,则加入答案,指针后移
if p1.val == p2.val:
ans.append(p1.val)
p1 = p1.next
p2 = p2.next
# val较小的指针,如果存在skip指针,则不断向后跳直到val较大为止
elif p1.val < p2.val:
p1 = p1.next
elif p1.val > p2.val:
p2 = p2.next
print('ans:', ans)
统计次数:
def intersectWithoutSkips_stat(p1, p2):
ans = []
comparecount, compare_array = 0, []
while p1 != None and p2 != None:
comparecount += 1
compare_array.append('<' + str(p1.val) + ', ' + str(p2.val) + '>')
# 如果val相同,则加入答案,指针后移
if p1.val == p2.val:
ans.append(p1.val)
p1 = p1.next
p2 = p2.next
# val较小的指针,如果存在skip指针,则不断向后跳直到val较大为止
elif p1.val < p2.val:
p1 = p1.next
elif p1.val > p2.val:
p2 = p2.next
print('comparecount:', comparecount)
print('compare_array:', compare_array)
def intersectWithSkips_stat(p1, p2):
ans = []
skipcount, comparecount = 0, 0
skip_array, compare_array = [], []
while p1 != None and p2 != None:
# 如果val相同,则加入答案,指针后移
if p1.val == p2.val:
comparecount += 1
compare_array.append('<' + str(p1.val) + ', ' + str(p2.val) + '>')
ans.append(p1.val)
p1 = p1.next
p2 = p2.next
# val较小的指针,如果存在skip指针,则不断向后跳直到val较大为止
elif p1.val < p2.val:
comparecount += 1
compare_array.append('<' + str(p1.val) + ', ' + str(p2.val) + '>')
while p1.skip:
comparecount += 1
compare_array.append('<' + str(p1.skip.val) + ', ' + str(p2.val) + '>')
if p1.skip.val <= p2.val:
skipcount += 1
skip_array.append( '<' + str(p1.val) + ', ' + str(p1.skip.val) + '>')
p1 = p1.skip
else:
break
p1 = p1.next
elif p1.val > p2.val:
comparecount += 1
compare_array.append('<' + str(p1.val) + ', ' + str(p2.val) + '>')
while p2.skip:
comparecount += 1
compare_array.append('<' + str(p1.val) + ', ' + str(p2.skip.val) + '>')
if p2.skip.val <= p1.val:
skipcount += 1
skip_array.append('<' + str(p2.val) + ', ' + str(p2.skip.val) + '>')
p2 = p2.skip
else:
break
p2 = p2.next
print('comparecount:', comparecount)
print('compare_array:', compare_array)
print('skipcount:', skipcount)
print('skip_array:', skip_array)
运行结果截图和详细的文字说明(1)
带有跳表指针的倒排记录表
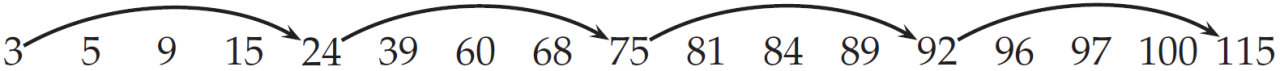
和3 5 9 96 99 100 101的合并操作
定义两个链表,并为list1加入skip指针,list2不加skip指针
list1 = linkedListWithSkips()
list1.addNodes([3, 5, 9, 15, 24, 39, 60, 68, 75,
81, 84, 89, 92, 96, 97, 100, 115])
list1.addSkips()
list2 = linkedListWithSkips()
list2.addNodes([3, 5, 9, 96, 99, 100, 101])
调用函数,计算合并结果并输出统计结果

运行结果截图和详细的文字说明(2):
带有跳表指针的倒排记录表
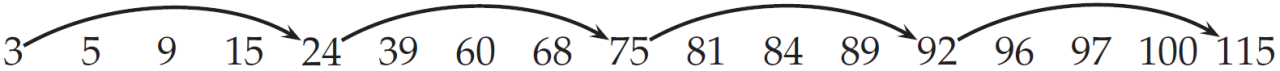
和25 60 120 150的合并操作
定义list3链表,不加入skip指针
list3 = linkedListWithSkips()
list3.addNodes([25, 60, 120, 150])
调用函数,计算合并结果并输出统计结果

(4). 阅读教材《Introduction to Information Retrieval》第42页Figure 2.12中所描述的邻近搜索(proximity search)中的两个倒排记录表(postings lists)的合并算法
并用Java语言或其他常用语言实现该算法,并按要求做适当改进。要求使用附件“HW2.txt”中的60个文档(每行表示一个document,按空格切词,文档中的单词全部转换为小写)建立positional index,两个词项之间的间距(注:相邻的两个词项的间距为1)的形式包括以下三种情形(x是一个正整数):“-x”、“+x”和“x”,
其中,“-x”表示第一个词项在第二个词项的左侧且间隔在x之内,“+x”表示第一个词项在第二个词项的右侧且间隔在x之内,“x”表示第一个词项与第二个词项的间隔(左侧和右侧均可)在x之内。
要求在以下例子上验证算法的正确性:(ranking, filtering, -4), (ranking, filtering, -5), (ranking, filtering, -6), (ranking, filtering, -7), (heterogeneous, learning, +2), (recommendation, bias, 2)。
代码截图和详细的文字说明:
- 读取文本并根据正则表达式对文本进行切割
# 打开文件
f = open('HW2.txt')
# 读取文章,并删除每行结尾的换行符
doc = pd.Series(f.read().splitlines())
# print(doc)
# 转换为小写,并使用正则表达式进行切割
doc = doc.apply(lambda x: re.split('[^a-zA-Z-]', x.lower()))
# 删除空串
for llist in doc:
while '' in llist:
llist.remove('')
print(doc)
结果:

- 根据分解的词条,构建如下的数据结构:
外层hashtable是一个哈希表:key是term词项,value是一个哈希表
value的哈希表中,key是doc_index文档序号,value是一个list(包含term出现的位置)

hashtable = {}
for doc_index, llist in enumerate(doc):
for term_index, term in enumerate(llist):
# 词项出现过
if term in hashtable:
# 词项在doc_index中出现过
if doc_index+1 in hashtable[term]:
hashtable[term][doc_index+1].append(term_index+1)
# 词项在doc_index中第一次出现
else:
hashtable[term][doc_index+1] = [term_index+1]
# 词项第一次出现
else:
hashtable[term] = {doc_index+1: [term_index+1]}
for term in hashtable:
print(term)
for doc_index in hashtable[term]:
print('\t', doc_index, ': ', hashtable[term][doc_index])
结果:

- 编写含位置信息的倒排记录表合并算法def positionalIntersect(list1, list2, k)
有三个参数:list1对应第一个词项,list2对应第二个词项,k是一个’+k/-k/k’的字符串
输出为三元组列表<文档ID, 词项在p1中的位置, 词项在p2中的位置>
首先比较得出词项一和词项二共同出现的docID,方法类似AND方法。
while p_docID1 < len(list1) and p_docID2 < len(list2):
# 首先查找两个列表共同的DocID
docID1, docID2 = [*list1][p_docID1], [*list2][p_docID2]
if docID1 == docID2:
pass
p_docID1 += 1
p_docID2 += 1
elif docID1 < docID2:
p_docID1 += 1
else:
p_docID2 += 1
最后利用二重循环比较两个term_index列表,根据根据参数k的输入形式,判定取值范围。
举例:输入为+k,则当pos1在区间[pos2, pos2 + k]内,则为符合条件的查询
输入为-k,则当pos1在区间[pos2 - k, pos2]内,则为符合条件的查询
输入为k,则当pos1在区间[pos2 - k, pos2 + k]内,则为符合条件的查询
if k[0] == '+':
ranges = [0, int(k[1])]
elif k[0] == '-':
ranges = [-int(k[1]), 0]
else:
ranges = [-int(k), int(k)]
if l1[p_pos1] in range(l2[p_pos2]+ranges[0], l2[p_pos2]+ranges[1]+1):
l.append(l2[p_pos2])
具体处理方式见以下完整代码:
def positionalIntersect(list1, list2, k):
ans = []
ranges = []
if k[0] == '+':
ranges = [0, int(k[1])]
elif k[0] == '-':
ranges = [-int(k[1]), 0]
else:
ranges = [-int(k), int(k)]
p_docID1, p_docID2 = 0, 0
while p_docID1 < len(list1) and p_docID2 < len(list2):
# 首先查找两个列表共同的DocID
docID1, docID2 = [*list1][p_docID1], [*list2][p_docID2]
if docID1 == docID2:
l = []
l1, l2 = list1[docID1], list2[docID2]
p_pos1, p_pos2 = 0, 0
# 二重循环遍历term出现的位置并比较
while p_pos1 < len(l1):
while p_pos2 < len(l2):
# 如果pos1 在符合条件的范围内,则加入临时答案列表l
if l1[p_pos1] in range(l2[p_pos2]+ranges[0], l2[p_pos2]+ranges[1]+1):
l.append(l2[p_pos2])
p_pos2 += 1
# 格式化临时答案列表
# 答案为三元组<文档ID, 词项在p1中的位置, 词项在p2中的位置>
for pos2 in l:
ans.append([docID1, l1[p_pos1], pos2])
p_pos1 += 1
p_docID1 += 1
p_docID2 += 1
elif docID1 < docID2:
p_docID1 += 1
else:
p_docID2 += 1
return ans
例子1 (ranking, filtering, -4)上的运行结果截图和详细的文字说明:
str1, str2, k = 'ranking', 'filtering', '-4'
print('hashtable[\'', str1, '\']: ', hashtable[str1])
print('hashtable[\'', str2, '\']: ', hashtable[str2])
positionalIntersect(hashtable[str1], hashtable[str2], k)

27号文档中,ranking位置为4,filtering位置为8;
57号文档中,ranking位置为7,filtering位置为11
例子2 (ranking, filtering, -5)上的运行结果截图和详细的文字说明:
str1, str2, k = 'ranking', 'filtering', '-5'
print('hashtable[\'', str1, '\']: ', hashtable[str1])
print('hashtable[\'', str2, '\']: ', hashtable[str2])
positionalIntersect(hashtable[str1], hashtable[str2], k)

12号文档中,ranking位置为5,filtering位置为10;
27号文档中,ranking位置为4,filtering位置为8;
57号文档中,ranking位置为7,filtering位置为11
例子3 (ranking, filtering, -6)上的运行结果截图和详细的文字说明:
str1, str2, k = 'ranking', 'filtering', '-6'
print('hashtable[\'', str1, '\']: ', hashtable[str1])
print('hashtable[\'', str2, '\']: ', hashtable[str2])
positionalIntersect(hashtable[str1], hashtable[str2], k)
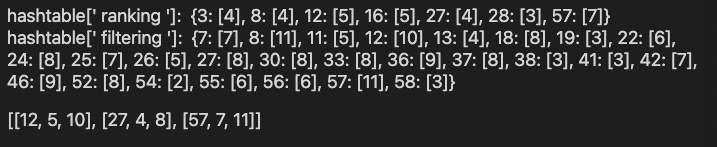
12号文档中,ranking位置为5,filtering位置为10;
27号文档中,ranking位置为4,filtering位置为8;
57号文档中,ranking位置为7,filtering位置为11
例子4 (ranking, filtering, -7)上的运行结果截图和详细的文字说明:
str1, str2, k = 'ranking', 'filtering', '-7'
print('hashtable[\'', str1, '\']: ', hashtable[str1])
print('hashtable[\'', str2, '\']: ', hashtable[str2])
positionalIntersect(hashtable[str1], hashtable[str2], k)

8号文档中,ranking位置为4,filtering位置为11;
12号文档中,ranking位置为5,filtering位置为10;
27号文档中,ranking位置为4,filtering位置为8;
57号文档中,ranking位置为7,filtering位置为11
例子5 (heterogeneous, learning, +2)上的运行结果截图和详细的文字说明:
str1, str2, k = 'heterogeneous', 'learning', '+2'
print('hashtable[\'', str1, '\']: ', hashtable[str1])
print('hashtable[\'', str2, '\']: ', hashtable[str2])
positionalIntersect(hashtable[str1], hashtable[str2], k)

7号文档中,heterogeneous位置为4,learning位置为2;
30号文档中,heterogeneous位置为5,learning位置为3;
33号文档中,heterogeneous位置为5,learning位置为3;
36号文档中,heterogeneous位置为6,learning位置为4;
56号文档中,heterogeneous位置为4,learning位置为2;
例子6 (recommendation, bias, 2)上的运行结果截图和详细的文字说明:
str1, str2, k = 'recommendation', 'bias', '2'
print('hashtable[\'', str1, '\']: ', hashtable[str1])
print('hashtable[\'', str2, '\']: ', hashtable[str2])
positionalIntersect(hashtable[str1], hashtable[str2], k)

49号文档中,recommendation位置为5,bias位置为7;
50号文档中,recommendation位置为5,bias位置为3;
(5). 阅读教材《Introduction to Information Retrieval》第59页Figure 3.5中所描述的基于动态规划(dynamic programming)来计算两个字符串的编辑距离(edit distance)的算法,并用Java语言或其他常用语言实现该算法。要求计算以下15组单词的编辑距离:
(business, buisness)
(committee, commitee)
(conscious, concious)
(definitely, definately)
(fluorescent, florescent)
(forty, fourty)
(government, goverment)
(idiosyncrasy, idiosyncracy)
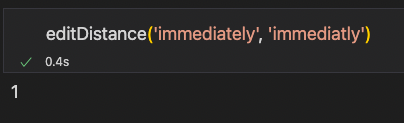
(immediately, immediatly)
(millennium, millenium)
(noticeable, noticable)
(tendency, tendancy)
(truly, truely)
(weird, wierd)
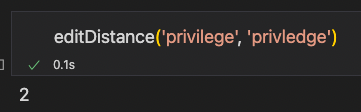
(privilege, privledge)
代码截图和详细的文字说明:
算法思想:动态规划
dp[i][j] 代表s1到i位置转换成s2到j位置需要最少步数
所以,当s1[i] == s2[j],dp[i][j] = dp[i-1][j-1];
当s1[i] != s2[j],dp[i][j] = min(dp[i-1][j-1], dp[i-1][j], dp[i][j-1]) + 1
其中,dp[i-1][j-1] 表示替换操作,dp[i-1][j] 表示删除操作,dp[i][j-1] 表示插入操作。
注意,针对第一行,第一列要单独考虑,引入空行如下图所示:
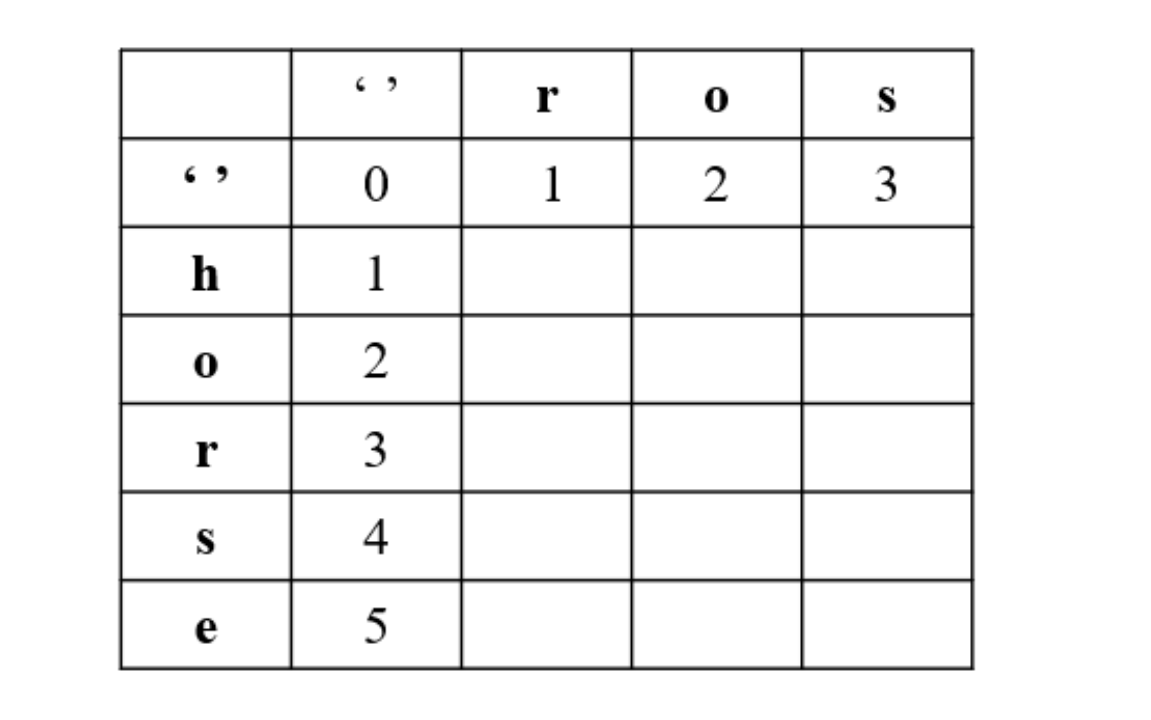
第一行,是s1为空变成 word2 最少步数,就是插入操作
第一列,是s2为空,需要的最少步数,就是删除操作
实现代码如下所示:
def editDistance(s1, s2):
n, m = len(s1), len(s2)
# 创建dp数组 size = n * m
dp = [[0] * (m + 1) for _ in range(n + 1)]
# 边界状态初始化
for i in range(n + 1):
dp[i][0] = i
for j in range(m + 1):
dp[0][j] = j
# 计算所有 DP 值
for i in range(1, n + 1):
for j in range(1, m + 1):
# 如果字符相同,则不需要操作 temp = 0
temp = 0 if s1[i - 1] == s2[j - 1] else 1
dp[i][j] = min(dp[i - 1][j - 1] + temp,
dp[i - 1][j] + 1,
dp[i][j - 1] + 1)
return dp[n][m]
计算得到的15组单词的编辑距离如下:
(business, buisness):2

(committee, commitee):1

(conscious, concious):1

(definitely, definately):1
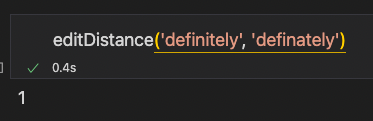
(fluorescent, florescent):1
(forty, fourty):1

(government, goverment):1

(idiosyncrasy, idiosyncracy):1

(immediately, immediatly):1
(millennium, millenium):1
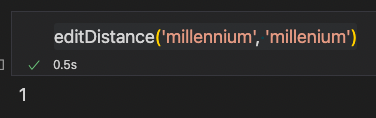
(noticeable, noticable):1

(tendency, tendancy):1
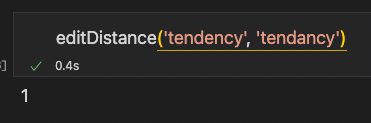
(truly, truely):1
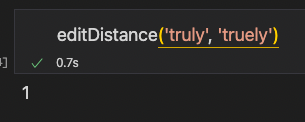
(weird, wierd):1
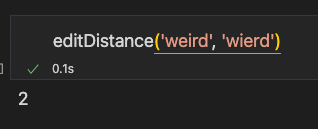
(privilege, privledge):2
附件 HW2.txt
Adaptive Pairwise Preference Learning for Collaborative Recommendation with Implicit Feedbacks
HGMF: Hierarchical Group Matrix Factorization for Collaborative Recommendation
Adaptive Bayesian Personalized Ranking for Heterogeneous Implicit Feedbacks
Compressed Knowledge Transfer via Factorization Machine for Heterogeneous Collaborative Recommendation
A Survey of Transfer Learning for Collaborative Recommendation with Auxiliary Data
Mixed Factorization for Collaborative Recommendation with Heterogeneous Explicit Feedbacks
Transfer Learning for Heterogeneous One-Class Collaborative Filtering
Group Bayesian Personalized Ranking with Rich Interactions for One-Class Collaborative Filtering
Transfer Learning for Semi-Supervised Collaborative Recommendation
Transfer Learning for Behavior Prediction
TOCCF: Time-Aware One-Class Collaborative Filtering
RBPR: Role-based Bayesian Personalized Ranking for Heterogeneous One-Class Collaborative Filtering
Hybrid One-Class Collaborative Filtering for Job Recommendation
Mixed Similarity Learning for Recommendation with Implicit Feedback
Collaborative Recommendation with Multiclass Preference Context
Transfer Learning for Behavior Ranking
Transfer Learning from APP Domain to News Domain for Dual Cold-Start Recommendation
k-CoFi: Modeling k-Granularity Preference Context in Collaborative Filtering
CoFi-points: Collaborative Filtering via Pointwise Preference Learning over Item-Sets
Personalized Recommendation with Implicit Feedback via Learning Pairwise Preferences over Item-sets
BIS: Bidirectional Item Similarity for Next-Item Recommendation
RLT: Residual-Loop Training in Collaborative Filtering for Combining Factorization and Global-Local Neighborhood
MF-DMPC: Matrix Factorization with Dual Multiclass Preference Context for Rating Prediction
Transfer to Rank for Heterogeneous One-Class Collaborative Filtering
Neighborhood-Enhanced Transfer Learning for One-Class Collaborative Filtering
Next-Item Recommendation via Collaborative Filtering with Bidirectional Item Similarity
Asymmetric Bayesian Personalized Ranking for One-Class Collaborative Filtering
Context-aware Collaborative Ranking
Transfer to Rank for Top-N Recommendation
Dual Similarity Learning for Heterogeneous One-Class Collaborative Filtering
Sequence-Aware Factored Mixed Similarity Model for Next-Item Recommendation
PAT: Preference-Aware Transfer Learning for Recommendation with Heterogeneous Feedback
Adaptive Transfer Learning for Heterogeneous One-Class Collaborative Filtering
A General Knowledge Distillation Framework for Counterfactual Recommendation via Uniform Data
FISSA: Fusing Item Similarity Models with Self-Attention Networks for Sequential Recommendation
Asymmetric Pairwise Preference Learning for Heterogeneous One-Class Collaborative Filtering
k-Reciprocal Nearest Neighbors Algorithm for One-Class Collaborative Filtering
CoFiGAN: Collaborative Filtering by Generative and Discriminative Training for One-Class Recommendation
Conditional Restricted Boltzmann Machine for Item Recommendation
Matrix Factorization with Heterogeneous Multiclass Preference Context
CoFi-points: Collaborative Filtering via Pointwise Preference Learning on User/Item-Set
A Survey on Heterogeneous One-Class Collaborative Filtering
Holistic Transfer to Rank for Top-N Recommendation
FedRec: Federated Recommendation with Explicit Feedback
Factored Heterogeneous Similarity Model for Recommendation with Implicit Feedback
FCMF: Federated Collective Matrix Factorization for Heterogeneous Collaborative Filtering
Sequence-Aware Similarity Learning for Next-Item Recommendation
FR-FMSS: Federated Recommendation via Fake Marks and Secret Sharing
Transfer Learning in Collaborative Recommendation for Bias Reduction
Mitigating Confounding Bias in Recommendation via Information Bottleneck
FedRec++: Lossless Federated Recommendation with Explicit Feedback
VAE++: Variational AutoEncoder for Heterogeneous One-Class Collaborative Filtering
TransRec++: Translation-based Sequential Recommendation with Heterogeneous Feedback
Collaborative filtering with implicit feedback via learning pairwise preferences over user-groups and item-sets
Interaction-Rich Transfer Learning for Collaborative Filtering with Heterogeneous User Feedback
Transfer Learning in Heterogeneous Collaborative Filtering Domains
GBPR: Group Preference based Bayesian Personalized Ranking for One-Class Collaborative Filtering
CoFiSet: Collaborative Filtering via Learning Pairwise Preferences over Item-sets
Modeling Item Category for Effective Recommendation
Position-Aware Context Attention for Session-Based Recommendation
















 1979
1979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











