







回顾一下PLA(PerceptronLearning Algorithm)是线性分类器,每次发现一个错误分类的样本,就对超平面进行更新。

上一课主要证明了PLA算法在数据为线性可分的情况下,是能够终止,找到最终能够准确分类数据的超平面的。
在证明中是用到了理想的超平面Wf,实际上它是未知的,如果已知的话我们也就不用花力气去计算PLA了。还有一个问题是我们的训练数据D是否是线性可分的也无从得知。也就是说,在实际应用中,我们并不知道PLA算法是否真的能够终止,只是在理论上证明了只要数据线性可分是会终止的。
那么,在实际应用中应该怎么办呢?在数据是否线性可分未知的情况下,难道让PLA一直不停地跑下去吗?这就是这节课要解决的问题。改变一下之前的PLA,我们不知道是否能够找到一个完美的超平面,那么我们可以找一个犯错误最少的超平面。
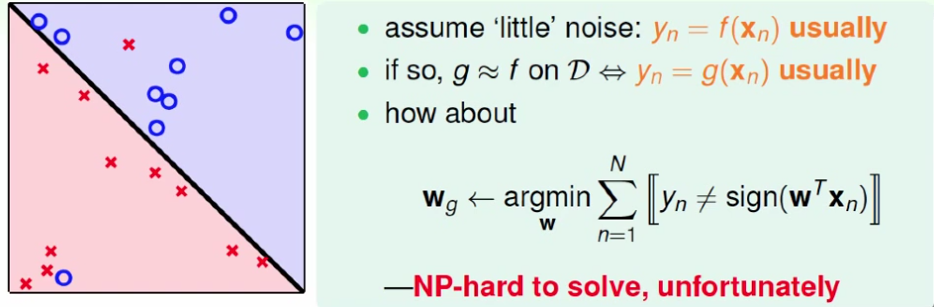
如上图所示,我们的目标现在是找到一个犯错误最少的超平面来近似最完美的超平面,可是这是一个NP-hard问题,即无法求解的问题。因此,用pocket algrithm,可以理解为贪心算法,每次把最好的放在口袋里。用比较随机的方式找新的线,每次比较新的线与口袋里的(老的)线,哪个的效果更好,如果新的更好,才把口袋里的换成新的。如下:

现在我们每次不是找到一个错误的数据点就更新,而是随机找到错误的点,在新得到的超平面的分类误差比旧的好的时候,就用新的超平面更新旧的,否则保持不变,进行下一次迭代。最后的迭代次数(iterations)是认为设定的。达到规定的迭代次数后,所得到的超平面就是我们要找的最近似的超平面啦。
这里有个小问题,假设数据D是一个线性可分的数据集(但是实际上我们事先并不知道),那么用普通的PLA和pocket算法,那么两者相比,pocket会比PLA慢,但是两者得到的结果是一样的。为什么呢?
原因有两点:
(1)pocket算法每次要把当前最好的超平面存储下来
(2)pocket算法每次要计算新找到的超平面对所有的数据点的分类结果,与原来的进行比较。
这两点使得pocket算法会更慢。
现在我们每次不是找到一个错误的数据点就更新,而是
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









