






一、定义
JStorm是一个分布式实时计算引擎,是一套基于流水线的消息处理机制。
用户按照指定的接口实现一个任务,然后将这个任务递交给JStorm系统,Jstorm将这个任务跑起来,并且按7 * 24小时运行起来,一旦中间一个worker 发生意外故障, 调度器立即分配一个新的worker替换这个失效的worker。
二、应用场景
- 日志分析
- 管道系统, 将一个数据从一个系统传输到另外一个系统;
- 消息转化器, 将接受到的消息按照某种格式进行转化,存储到另外一个系统如消息中间件;
- 统计分析器, 从日志或消息中,提炼出某个字段,然后做count或sum计算,最后将统计值存入外部存储器。中间处理过程可能更复杂。
1、流(InputStream)
是一个不间断的连续的tuple,在JStorm里,通过nextTuple方法将数据流往下发射流出。
2、Spout/Bolt
JStorm将每个stream的唯一stream源,抽象为一个spout,即原始元组的源头。然后通过此源头将数据封装为tuple发射给一个或多个Bolt。
所以Bolt就是JStorm将数据的处理过程抽象为一个个节点,各bolt节点间互相接收和发射数据。
我们可以认为spout就是一个一个的水龙头,并且每个水龙头里流出的水是不同的,我们想拿到哪种水就拧开哪个水龙头,然后使用管道将水龙头的水导向到一个水处理器(bolt),水处理器处理后再使用管道导向另一个处理器或者存入容器中。
3、Topology
Topology即拓扑(拓扑结构是有向无环的),拓扑是Jstorm中最高层次的一个抽象概念,它可以被提交到Jstorm集群执行,一个拓扑就是一个数据流转换图,图中每个节点是一个spout或者bolt。
4、Tuple
JStorm将流中数据抽象为tuple,一个tuple就是一个值列表,list中的每个value都有一个name,并且每个value的数据都是可序列化类型。
拓扑的每个节点spout/bolt都要说明它所发射出的元组的字段的name,其他节点只需要订阅该name就可以接收处理。
5、Worker/Task
都是JStorm中任务的执行单元
一个worker表示一个进程,一个task表示一个线程, 一个worker可以运行多个task
四、简单使用
//创建topology的生成器
TestBuilder builder = new TestBuilder();
//设置topology的所有配置信息
Config conf = new Config();
//表示整个topology将使用2个worker
conf.put(Config.TOPOLOGY_WORKERS, 2);
//设置topolog模式为分布式,这样topology就可以放到JStorm集群上运行
conf.put(Config.STORM_CLUSTER_MODE, "distributed");
创建Spout,名称为testSpout,执行类为TestSpout
builder.setSpout("testSpout", new TestSpout());
//创建Bolt,名称为testBolt,执行类为TestBolt,并发线程数为5,并且此5个线程接收testSpout输出的数据流
builder.setBolt("testBolt", new testBolt(), 5).shuffleGrouping("testSpout");
//集群,提交topology
StormSubmitter.submitTopology("testTopology", conf, builder.createTopology());
//本地,提交topology
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
注意:将jstorm项目放到集群后,每个Bolt会被集群中的服务器随机取出执行,因此Bolt相互之间无法公用一个实例。如果某一个Bolt缓存一个数据集,其它Bolt需要使用这个缓存里的数据集,不能通过取全局实例来获取,可以让缓存的数据集喷数据给其他Bolt。
五、Spout类方法介绍

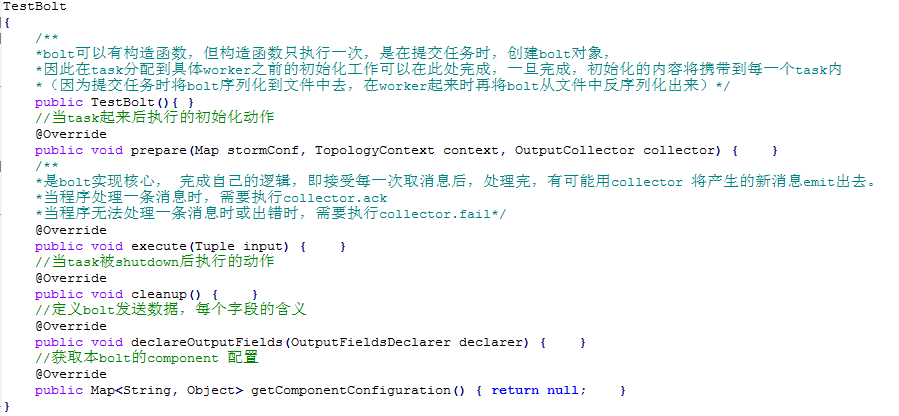
六、Bolt类方法介绍
七、JStorm优点
- 开发非常迅速, 接口简单,容易上手,只要遵守Topology,Spout, Bolt的编程规范即可开发出一个扩展性极好的应用,底层rpc,worker之间冗余,数据分流之类的动作完全不用考虑。
- 扩展性极好, 当一级处理单元速度,直接配置一下并发数,即可线性扩展性能
- 健壮, 当worker失效或机器出现故障时, 自动分配新的worker替换失效worker
- 数据准确性, 可以采用Acker机制,保证数据不丢失。 如果对精度有更多一步要求,采用事务机制,保证数据准确。
1、JStorm比Storm更稳定,主要在内存的处理上,storm经常出现内存不够的情况。其次,JStorm新上线的任务不会冲击老的任务,新调度从cpu,memory,disk,net 四个角度对任务进行分配,已经分配好的新任务,无需去抢占老任务的cpu,memory,disk和net
2、JStorm比Storm调度更强大
(1)彻底解决了storm 任务分配不均衡问题
(2)从4个维度进行任务分配:CPU、Memory、Disk、Net
(3)可以随时更多的申请cpu、内存、disk
(4)可以强制某个component的task 运行在不同的节点上
(5)可以强制topology运行在单独一个节点上
(6)可以自定义任务分配,提前预约任务分配到哪台机器上,哪个端口,多少个cpu slot,多少内存,是否申请磁盘
(7)可以预约上一次成功运行时的任务分配,上次task分配了什么资源,这次还是使用这些资源
3、JStorm比Storm性能更好
后续了解后再补充















 490
490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









