









继续学习侯捷老师的课程!
在前面的博客《C++ STL学习笔记(2) 容器结构与分类》中介绍了STL中常用到的容器以及他们的使用方法,在我们使用容器的时候,背后需要一个东西支持对内存的使用,这个东西就是分配器(Allocator)。容器一般都会有一个默认的分配器。
例如,以vector为例,可以看到它的定义:

他有一个默认的分配器std::allocator(位于#include <memory>),还有其他的分配器如下所示:

可以定义具有不同分配器的容器: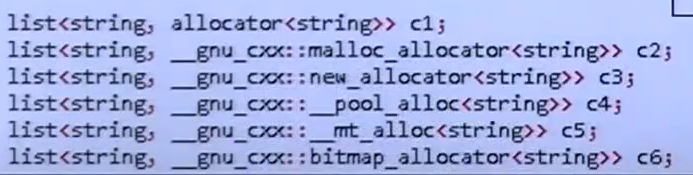
一般我们不会直接去使用分配器,而是选择使用容器,对于少量的额内存需求,我们会使用new,delete或者malloc, free来分配内存。
-----------------------------------------------------分割线-------------------------------------------------------------------------
OOP与GP的差别:
1. OOP企图将datas和methods关联在一起,类中定义了数据和方法,如下所示:

2. 而GP是将datas和methods分开。例如:

而迭代器相当于容器和算法之间的一个桥梁,算法通过迭代器,对容器中的数据进行特定的操作。
采用泛型编程(GP),Containers和Algorithm团队可以各自“闭门造车”,他们之间只需要以Iterator沟通即可。algorithm通过Iterator确定操作范围,并通过iterator获取容器中的元素。
例如,c++中的max()函数:
template<typename T>
T max(const T& a, const T& b)
{
return (a > b) ? a : b;
}算法团队只需要关注如何实现max()函数,至于a.b之间大小如何比较,则由container团队根据具体的对象实现。
链表list和vector的迭代器的区别:
list的迭代器不是连续的。而vector中的迭代器是连续的,所以可以对vector的迭代器进行+n的操作。所以vector可以使用全局的sort()函数进行排序,而list只能使用list类里面定义的sort方法进行排序。
C++中的另一个概念,特化
C++的模板函数,模板类允许我们定义的类或者函数的参数具有泛化的特性,与之相对,C++也允许我们定义特化的版本。
例如,定义一个泛化的结构体(这个例子是侯捷老师PPT上面的),也是标准库中的源代码
 可以定义它的两个特化的版本:
可以定义它的两个特化的版本:
1. 特化版本,当参数的类型是int的时候
2. 特化版本,当参数的类型是doublet的时候

对于上面的泛化特化的概念,可以举一个例子:
// ConsoleApplication1.cpp : 定义控制台应用程序的入口点。
#include "stdafx.h"
#include <iostream>
template<typename T> // 定义泛化的测试函数
void print_info(T x)
{
std::cout << "This is a generic version: " << x << std::endl;
}
template<> // 定义特化的版本
void print_info<int>(int x)
{
std::cout << "This is a specialization int version: " << x << std::endl;
}
template<> // 因为已经指定类型,所以不需要在template中声明类型 // 定义特化的版本
void print_info<double>(double x)
{
std::cout << "This is a specialization double version: " << x << std::endl;
}
int main()
{
print_info(5);
print_info(5.9);
print_info("delf");
print_info('f');
return 0;
}
特化可以分为全特化(full specialization) 和 偏特化,也称局部特化(partial specialization),同时,特化又可以分为两种情况
1. 参数个数的特化
例如: 定义一个泛化的类:
template<typename T, typename Alloc = alloc> // 泛化的类
class vector
{
...
};再定义一个偏特化的类:
template<typename Alloc> // 特化的版本
class vector<bool, Alloc> // 这里只对第一个类型进行特化,第二个类型还是泛化,所以称为偏特化
{
...
};
2.参数范围的特化,这里的范围指的是类型的范围
具体的意思如下面的程序所示:
1. 定义一个泛化的版本:
template<typename Iterator>
struct iterator_traits
{
...
};
2. 定义一个特化的版本:
template<typename Iterator>
struct iterator_traits
{
...
};
--------------------------------------------------------分割线------------------------------------------------------------


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









