







背景
除了ES作为日志查询外,Loki+Grafana也成为了日志查询的主流方式
主要源于它的查询语句简单易用,聚合函数方便直观,不用ES查询那么复杂的语法规则
Loki查询语法
基本的LogQL查询由两部分组成:
- log stream selector
- filter expression
他们都是由键值对构成,简单直观
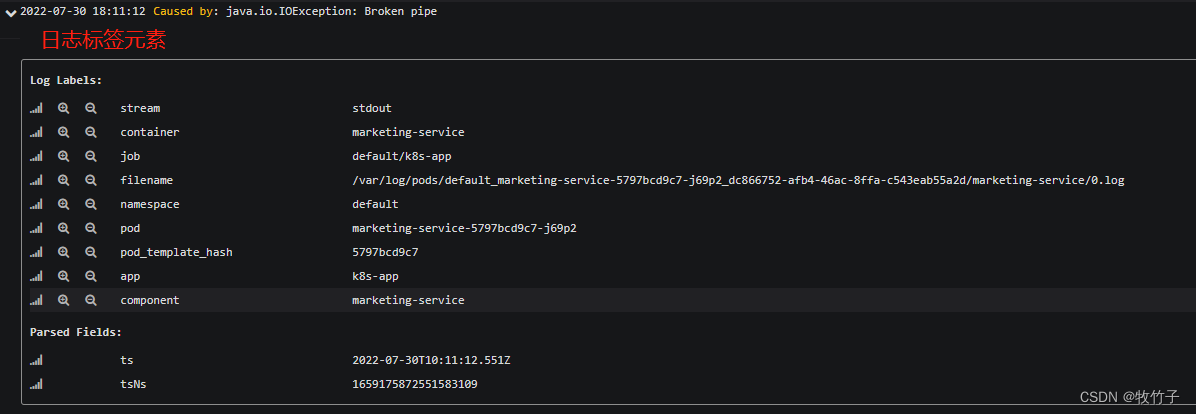
日志是由日期,服务系统名称,模块名称等等日志的标签元素组成,就像是表结构中的列名,用以区分每条日志的基本元素
Log stream selector日志流筛选
最基本的筛选就是基于日志标签元素进行,比如系统名是qxmart,微服务名是order-service的所有日志
并列条件之间使用逗号分隔
{app="qxmart",component="order-service"}
常用的筛选条件语句标签匹配运算符:
- = 完全相等
- != 不相等
- =~ 正则表达式匹配
- !~ 正则表达式不匹配
Filter expression过滤表达式
日志流选择器后,可以使用搜索表达式进一步过滤生成的日志集。这里的日志集合是满足{}语句的标签筛选后,对集合结果中的所有文本字符进行匹配筛选,就像chrome浏览器ctrl+F的功能,满足条件的才会列出来,不满足的则看不到
搜索表达式可以只是文本或正则表达式:
- |=日志行包含字符串
- !=日志行不包含字符串
- |~日志行匹配正则表达式
- !~日志行与正则表达式不匹配
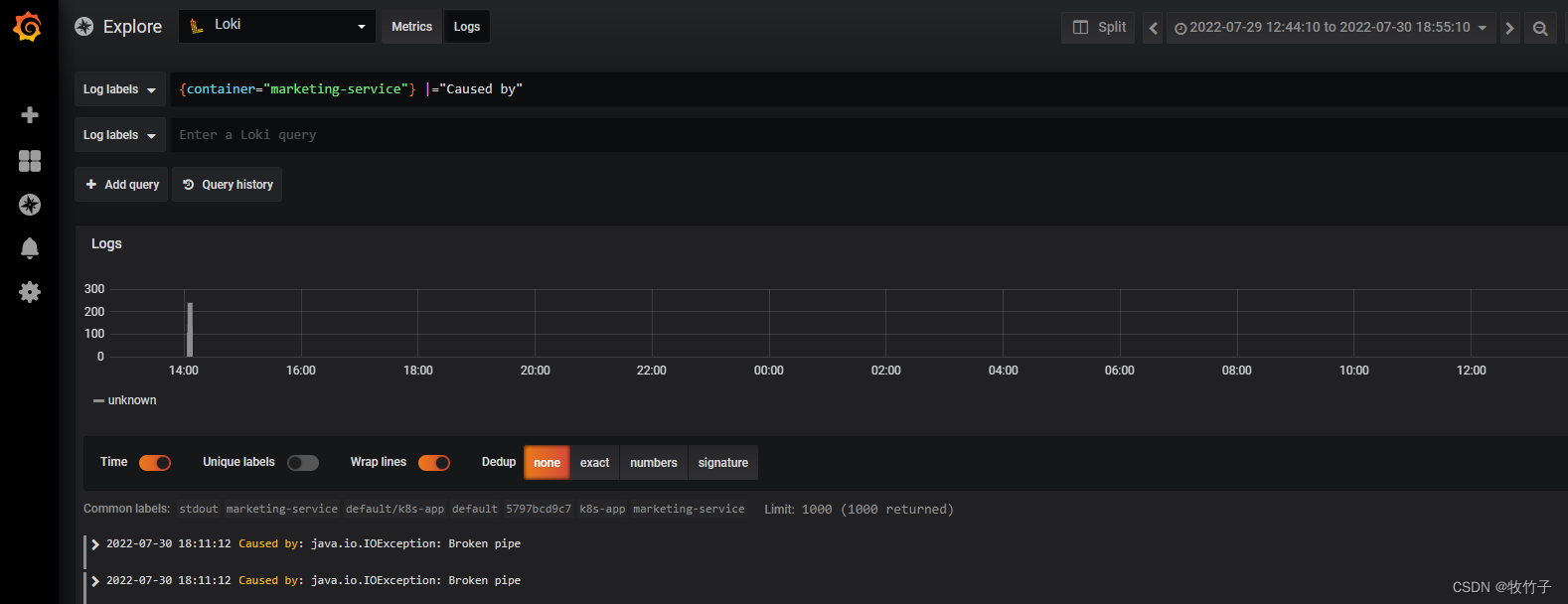
比如上面标签选择器的基础上,我们要求满足输出日志中只查询包含由Caused by的语句()
{component="order-service"} |="Caused by"
其他用例
{job=“mysql”} |= “error” //包含error的日志
{name=“kafka”} |~ “tsdb-ops.*io:2003” //匹配tsdb-ops.*io:2003文本的所有日志
{instance=~“kafka-[23]”,name=“kafka”} != kafka.server:type=ReplicaManager
基于HTTP查询
Grafana上的查询本身是基于Loki的http查询基础上做的,因此隐藏了查询参数,用户只用关注查询表达式即可,但是更多复杂的查询终究是要基于原生查询方式
Loki提供了HTTP接口,我们这里就不详解了,大家可以看:
https://github.com/grafana/loki/blob/master/docs/api.md
我们这里说下查询的接口如何使用:
第一步,获取当前Loki的元数据类型:
也就相当于表结构的列名
curl http://192.168.25.30:30972/api/prom/label
{
"values": ["alertmanager", "app", "component", "container_name", "controller_revision_hash", "deployment", "deploymentconfig", "docker_registry", "draft", "filename", "instance", "job", "logging_infra", "metrics_infra", "name", "namespace", "openshift_io_component", "pod_template_generation", "pod_template_hash", "project", "projectname", "prometheus", "provider", "release", "router", "servicename", "statefulset_kubernetes_io_pod_name", "stream", "tekton_dev_pipeline", "tekton_dev_pipelineRun", "tekton_dev_pipelineTask", "tekton_dev_task", "tekton_dev_taskRun", "type", "webconsole"]
}
第二步,获取某个元数据类型的值:
列名的常用值,它是基于列名做的索引,所以能够根据列名查询出所有的索引名称
curl http://192.168.25.30:30972/api/prom/label/namespace/values
{"values":["cicd","default","gitlab","grafanaserver","jenkins","jx-staging","kube-system","loki","mysql-exporter","new2","openshift-console","openshift-infra","openshift-logging","openshift-monitoring","openshift-node","openshift-sdn","openshift-web-console","tekton-pipelines","test111"]}
第三步,根据label进行查询,例如:
这里的lael即相当于列名具体参数查询,主要体现在query表达式
http://192.168.25.30:30972/api/prom/query?direction=BACKWARD&limit=1000®exp=&query={namespace="cicd"}&start=1567644457221000000&end=1567730857221000000&refId=A
这样一个完整的查询过程就完成了,只不过Grafana在我们添加完Loki服务地址后,会自动帮我们完成前两步的事情,随着我们在Label输入框输入查询表达式时,就相当于完成了query参数的构建,而日期范围通过日期选择器完成
参数解析:
- query: 一种查询语法详细见下面章节,{name=~“mysql.+”} or {namespace=“cicd”} |= "error"表示查询,
namespace为cicd的日志中,有error字样的信息。 - limit: 返回日志的数量,默认值是10000
- start:开始时间,Unix时间表示方法 默认为,一小时前时间
- end: 结束时间,默认为当前时间
- direction: forward 或者 backward, .指定limit时候有用,默认为 backward.
- regexp:对结果进行regex过滤
高级查询语句
范围向量
LogQL 与Prometheus 具有相同的范围向量概念,不同之处在于所选的样本范围包括每个日志条目的值1。可以在所选范围内应用聚合,以将其转换为实例向量。
注:对于此种查询,需要添加数据源,选择promethes,但是地址为loki的地址,并在最后添加/loki即可
当前支持的操作功能为:
- rate:计算每秒的条目数
- count_over_time:计算给定范围内每个日志流的条目。
//对fluent-bit作业在最近五分钟内的所有日志行进行计数。
count_over_time({job="fluent-bit"}[5m]) #获取fluent-bit作业在过去十秒内所有非超时错误的每秒速率。
rate({job="fluent-bit"} |= "error" != "timeout" [10s] #集合运算符
与PromQL一样,LogQL支持内置聚合运算符的一个子集,可用于聚合单个向量的元素,从而产生具有更少元素但具有集合值的新向量:
- sum:计算标签上的总和
- min:选择最少的标签
- max:选择标签上方的最大值
- avg:计算标签上的平均值
- stddev:计算标签上的总体标准差
- stdvar:计算标签上的总体标准方差
- count:计算向量中元素的数量
- bottomk:通过样本值选择最小的k个元素
- topk:通过样本值选择最大的k个元素
可以通过包含a without或 by子句,使用聚合运算符聚合所有标签值或一组不同的标签值:
#语法如下
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]
举例:
统计最高日志吞吐量按container排序前十的应用程序
topk(10,sum(rate({job="fluent-bit"}[5m])) by(container))
获取最近五分钟内的日志计数,按级别分组
sum(count_over_time({job="fluent-bit"}[5m])) by (level)















 4902
4902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









