







 本文介绍如何使用Canal从MySQL实时抽取数据至数据仓库。包括配置MySQL、搭建Canal服务、编写客户端、处理数据及Canal高可用配置。
本文介绍如何使用Canal从MySQL实时抽取数据至数据仓库。包括配置MySQL、搭建Canal服务、编写客户端、处理数据及Canal高可用配置。
数据抽取是 ETL 流程的第一步。我们会将数据从 RDBMS 或日志服务器等外部系统抽取至数据仓库,进行清洗、转换、聚合等操作。在现代网站技术栈中,MySQL 是最常见的数据库管理系统,我们会从多个不同的 MySQL 实例中抽取数据,存入一个中心节点,或直接进入 Hive。市面上已有多种成熟的、基于 SQL 查询的抽取软件,如著名的开源项目 Apache Sqoop,然而这些工具并不支持实时的数据抽取。MySQL Binlog 则是一种实时的数据流,用于主从节点之间的数据复制,我们可以利用它来进行数据抽取。借助阿里巴巴开源的 Canal 项目,我们能够非常便捷地将 MySQL 中的数据抽取到任意目标存储中。
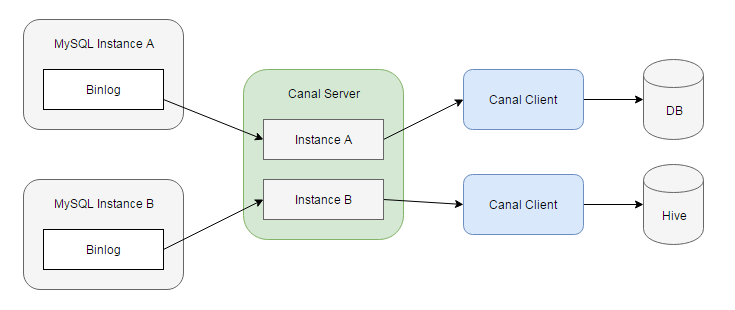
Canal 的组成部分
简单来说,Canal 会将自己伪装成 MySQL 从节点(Slave),并从主节点(Master)获取 Binlog,解析和贮存后供下游消费端使用。Canal 包含两个组成部分:服务端和客户端。服务端负责连接至不同的 MySQL 实例,并为每个实例维护一个事件消息队列;客户端则可以订阅这些队列中的数据变更事件,处理并存储到数据仓库中。下面我们来看如何快速搭建起一个 Canal 服务。
配置 MySQL 主节点
MySQL 默认没有开启 Binlog,因此我们需要对 my.cnf 文件做以下修改:
server-id = 1
log_bin = /path/to/mysql-bin.log
binlog_format = ROW
注意 binlog_format 必须设置为 ROW, 因为在 STATEMENT 或 MIXED 模式下, Binlog 只会记录和传输 SQL 语句(以减少日志大小),而不包含具体数据,我们也就无法保存了。
从节点通过一个专门的账号连接主节点,这个账号需要拥有全局的 REPLICATION 权限。我们可以使用 GRANT 命令创建这样的账号:
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT
ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal';
启动 Canal 服务端
从 GitHub 项目发布页中下载 Canal 服务端代码(链接),配置文件在 conf 文件夹下,有以下目录结构:
canal.deployer/conf/canal.properties
canal.deployer/conf/instanceA/instance.properties
canal.deployer/conf/instanceB/instance.properties
conf/canal.properties 是主配置文件,如其中的 canal.port 用以指定服务端监听的端口。instanceA/instance.properties 则是各个实例的配置文件,主要的配置项有:
# slaveId 不能与 my.cnf 中的 server-id 项重复
canal.instance.mysql.slaveId = 1234
canal.instance.master.address = 127.0.0.1:3306
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
canal.instance.connectionCharset = UTF-8
# 订阅实例中所有的数据库和表
canal.instance.filter.regex = .*\\..*
执行 sh bin/startup.sh 命令开启服务端,在日志文件 logs/example/example.log 中可以看到以下输出:
Loading properties file from class path resource [canal.properties]
Loading properties file from class path resource [example/instance.properties]
start CannalInstance for 1-example
[destination = example , address = /127.0.0.1:3306 , EventParser] prepare to find start position just show master status
编写 Canal 客户端
从服务端消费变更消息时,我们需要创建一个 Canal 客户端,指定需要订阅的数据库和表,并开启轮询。
首先,在项目中添加 com.alibaba.otter:canal.client 依赖项,构建 CanalConnector 实例:
CanalConnector connector = CanalConnectors.newSingleConnector(
new InetSocketAddress("127.0.0.1", 11111), "example", "", "");
connector.connect();
connector.subscribe(".*\\..*");
while (true) {
Message message = connector.getWithoutAck(100);
long batchId = message.getId();
if (batchId == -1 || message.getEntries().isEmpty()) {
Thread.sleep(3000);
} else {
printEntries(message.getEntries());
connector.ack(batchId);
}
}
这段代码和连接消息系统很相似。变更事件会批量发送过来,待处理完毕后我们可以 ACK 这一批次,从而避免消息丢失。
// printEntries
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
for (RowData rowData : rowChange.getRowDatasList()) {
if (rowChange.getEventType() == EventType.INSERT) {
printColumns(rowData.getAfterCollumnList());
}
}
每一个 Entry 代表一组具有相同变更类型的数据列表,如 INSERT 类型、UPDATE、DELETE 等。每一行数据我们都可以获取到各个字段的信息:
// printColumns
String line = columns.stream()
.map(column -> column.getName() + "=" + column.getValue())
.collect(Collectors.joining(","));
System.out.println(line);
完整代码可以在 GitHub 中找到(链接)。
加载至数据仓库
关系型数据库与批量更新
若数据仓库是基于关系型数据库的,我们可以直接使用 REPLACE 语句将数据变更写入目标表。其中需要注意的是写入性能,在更新较频繁的场景下,我们通常会缓存一段时间的数据,并批量更新至数据库,如:
REPLACE INTO `user` (`id`, `name`, `age`, `updated`) VALUES
(1, 'Jerry', 30, '2017-08-12 16:00:00'),
(2, 'Mary', 28, '2017-08-12 17:00:00'),
(3, 'Tom', 36, '2017-08-12 18:00:00');
另一种方式是将数据变更写入按分隔符分割的文本文件,并用 LOAD DATA 语句载入数据库。这些文件也可以用在需要写入 Hive 的场景中。不管使用哪一种方法,请一定注意要对字符串类型的字段进行转义,避免导入时出错。
基于 Hive 的数据仓库
Hive 表保存在 HDFS 上,该文件系统不支持修改,因此我们需要一些额外工作来写入数据变更。常用的方式包括:JOIN、Hive 事务、或改用 HBase。
数据可以归类成基础数据和增量数据。如昨日的 user 表是基础数据,今日变更的行是增量数据。通过 FULL OUTER JOIN,我们可以将基础和增量数据合并成一张最新的数据表,并作为明天的基础数据:
SELECT
COALESCE(b.`id`, a.`id`) AS `id`
,COALESCE(b.`name`, a.`name`) AS `name`
,COALESCE(b.`age`, a.`age`) AS `age`
,COALESCE(b.`updated`, a.`updated`) AS `updated`
FROM dw_stage.`user` a
FULL OUTER JOIN (
-- 增量数据会包含重复数据,因此需要选择最新的那一条
SELECT `id`, `name`, `age`, `updated`
FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY `id` ORDER BY `updated` DESC) AS `n`
FROM dw_stage.`user_delta`
) b
WHERE `n` = 1
) b
ON a.`id` = b.`id`;
Hive 0.13 引入了事务和 ACID 表,0.14 开始支持 INSERT、UPDATE、DELETE 语句,Hive 2.0.0 则又新增了 Streaming Mutation API,用以通过编程的方式批量更新 Hive 表中的记录。目前,ACID 表必须使用 ORC 文件格式进行存储,且须按主键进行分桶(Bucket)。Hive 会将变更记录保存在增量文件中,当 OrcInputFormat 读取数据时会自动定位到最新的那条记录。官方案例可以在这个链接中查看。
最后,我们可以使用 HBase 来实现表数据的更新,它是一种 KV 存储系统,同样基于 HDFS。HBase 的数据可以直接为 MapReduce 脚本使用,且 Hive 中可以创建外部映射表指向 HBase。更多信息请查看官方网站。
初始化数据
数据抽取通常是按需进行的,在新增一张表时,数据源中可能已经有大量原始记录了。常见的做法是手工将这批数据全量导入至目标表中,但我们也可以复用 Canal 这套机制来实现历史数据的抽取。
首先,我们在数据源库中创建一张辅助表:
CREATE TABLE `retl_buffer` (
id BIGINT AUTO_INCREMENT PRIMARY KEY
,table_name VARCHAR(255)
,pk_value VARCHAR(255)
);
当需要全量抽取 user 表时,我们执行以下语句,将所有 user.id 写入辅助表中:
INSERT INTO `retl_buffer` (`table_name`, `pk_value`)
SELECT 'user', `id` FROM `user`;
Canal 客户端在处理到 retl_buffer 表的数据变更时,可以从中解析出表名和主键的值,直接反查数据源,将数据写入目标表:
if ("retl_buffer".equals(entry.getHeader().getTableName())) {
String tableName = rowData.getAfterColumns(1).getValue();
String pkValue = rowData.getAfterColumns(2).getValue();
System.out.println("SELECT * FROM " + tableName + " WHERE id = " + pkValue);
}
这一方法在阿里巴巴的另一个开源软件 Otter 中使用。
Canal 高可用
- Canal 服务端中的实例可以配置一个备用 MySQL,从而能够在双 Master 场景下自动选择正在工作的数据源。注意两台主库都需要打开
log_slave_updates选项。Canal 会使用自己的心跳机制(定期更新辅助表的记录)来检测主库的存活。 - Canal 自身也有 HA 配置,配合 Zookeeper,我们可以开启多个 Canal 服务端,当某台服务器宕机时,客户端可以从 ZK 中获取新的服务端地址,继续进行消费。更多信息可以参考 Canal AdminGuide。
参考资料
- https://github.com/alibaba/canal/wiki
- https://github.com/alibaba/otter/wiki
- https://www.phdata.io/4-strategies-for-updating-hive-tables/
- https://hortonworks.com/blog/four-step-strategy-incremental-updates-hive/
- https://cwiki.apache.org/confluence/display/Hive/Hive+Transactions

















 3773
3773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









