







写在开头
刚刚入门Python,一切都是摸索阶段。把自己的问题记录下来避免之后再犯相同的错误。运气好或许还能帮助有缘人( ⊙o⊙ )
Python入门
Python的简单入门主要需要看两个文档:requests和bs4。链接如下:
requests
bs4
爬虫实例学习
在真正开始写自己的第一个爬虫的实例前,在网上看了其他许多大神的教程。这里是我第一个复制练习的例子:
大神教程
这是一个一周天气的信息的爬取。我使用的PyCharm编译器,这个IDE的优点就是可以帮助下载相应的包。
糗百笑话爬取
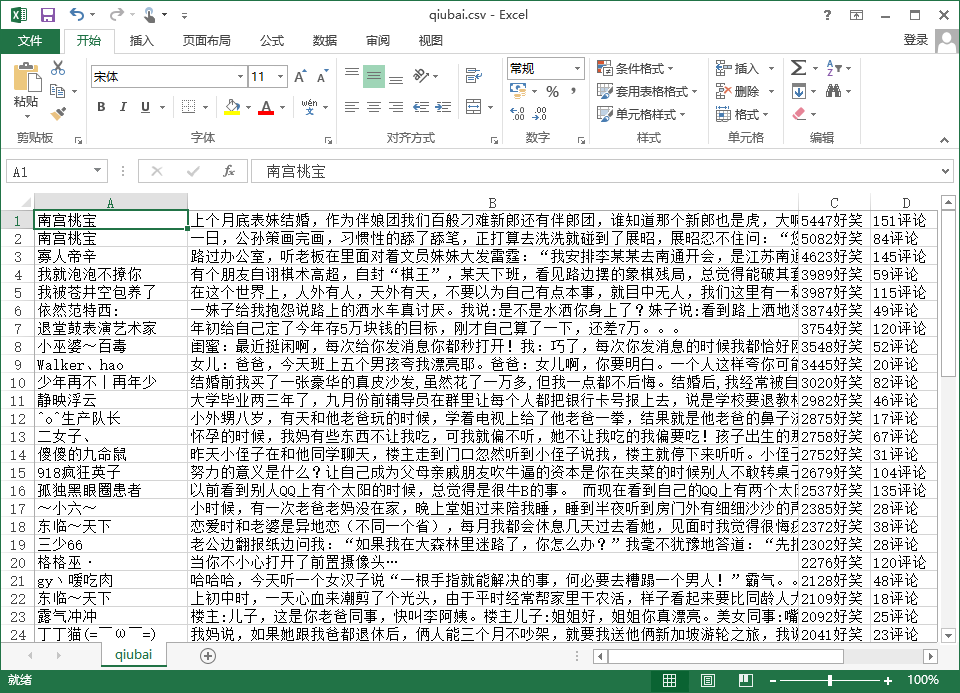
在复制大神的代码并运行成功后,我便开始在这个代码的基础上加以修改,运用于糗百网页。这里主要爬取了第一页的用户名、内容、点赞数和评论数。以下是代码,基本没有很大的改变。主要是bs4的运用。
- 需要引用的包
# coding : UFT-8
import requests
import csv
import random
import time
import socket
import http.client
import os
from bs4 import BeautifulSoup- 获取html页面内容代码
def get_info( url, data = None):
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.87 Safari/537.36'
}
timeout = random.choice(range(60,180))
while True :
try:
rep = requests.get(url, headers = header, timeout = timeout)
rep.encoding = 'utf-8'
break
except socket.timeout as e:
print('3:',e)
time.sleep(random.choice(range(8,15)))
except socket.error as e:
print('4:', e)
time.sleep(random.choice(range(20, 60)))
except http.client.BadStatusLine as e:
print('5:', e)
time.sleep(random.choice(range(30, 80)))
except http.client.IncompleteRead as e:
print('6:', e)
time.sleep(random.choice(range(5, 15)))
return rep.text这里主要就是参考第一个代码实例,基本没有变化。
- 获取html内容中需要的字段
def get_data(html ):
final = []
bs = BeautifulSoup(html, "html.parser")
body = bs.body
content_left = body.find(id = 'content-left') #找到该页总框
contents = content_left.find_all('div',class_ = 'article block untagged mb15')#找到所有内容框
for content in contents: #对每个故事进行遍历
temp = []
author = content.find('div',class_='author clearfix')#找到用户
user_name = content.find("h2").string#获取用户名
temp.append(user_name)#添加到list中
data = content.find(class_ = 'content')
story = data.find('span').get_text()#找到笑话内容
temp.append(story)#添加到list中
numbers = content.find_all('i', class_ = 'number')#查找评论和点赞数
good = numbers[0].string + '好笑'#获取点赞数
temp.append(good)
comment = numbers[1].string + '评论'#获取评论数
temp.append(comment)
final.append(temp)
return final这里主要是对bs4的运用。但是需要注意story这个数据,通过Chrome的F12可以看到这个部分有时候包含了<br>标签。这是因为有些用户使用了换行符。如果再使用.string将得不到结果。这里可以用get_text()获取整个内容。
写入CSV
主函数
这两个部分与实例代码一致,只是url不一样而已。















 1414
1414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









