






流程图
下图显示了当您通过Hystrix向服务依赖项发出请求时会发生什么情况:

下面详细地解释这个流程:
1、构造一个HystrixCommand或HystrixObservableCommand对象
第一步是构造一个HystrixCommand或HystrixObservableCommand对象,以表示您对依赖项的请求。向构造函数传递发出请求时所需的任何参数。
如果依赖希望返回单个响应,则构造一个HystrixCommand对象。例如:
HystrixCommand command = new HystrixCommand(arg1, arg2);如果依赖希望返回发出响应的可观察对象,则构造一个HystrixObservableCommand对象。例如:
HystrixObservableCommand command = new HystrixObservableCommand(arg1, arg2);2、Execute the Command
您可以使用以下四种方法之一来执行该命令(前两种方法仅适用于简单的HystrixCommand对象,不适用于HystrixObservableCommand):
execute() —块,然后返回从依赖项接收到的单个响应(或在出现错误时抛出异常)
queue() —返回可以从依赖项获取单个响应的Future
observe() —订阅表示来自依赖项的响应的可观察对象(Observable ),并返回复制源可观察对象(source Observable)的可观察对象
toObservable() — 返回一个可观察的,当您订阅它时,它将执行Hystrix命令并发出响应
K value = command.execute();
Future<K> fValue = command.queue();
Observable<K> ohValue = command.observe(); //hot observable
Observable<K> ocValue = command.toObservable(); //cold observable同步调用execute()调用queue().get()。queue()依次调用observable (). toblock (). tofuture()。也就是说,最终每个HystrixCommand都由一个可观察的实现支持,即使是那些打算返回单个简单值的命令。
3.是否缓存了响应?
如果为该命令启用了请求缓存,并且该请求的响应在缓存中可用,则该缓存的响应将立即以可观察的形式返回。
4. 电路打开了吗?
当您执行该命令时,Hystrix将与断路器一起检查电路是否打开。
如果电路是打开的(或“跳闸”),Hystrix将不执行该命令,而是将流路由到(8)获得回退。
如果电路是关闭的,则流继续(5)检查是否有能力运行该命令。
5. 线程池/队列/信号量是否已满?
如果与该命令相关的线程池和队列(或信号量,如果不在线程中运行)已满,那么Hystrix将不执行该命令,而是立即将流路由到(8)以获取回退
6. HystrixObservableCommand.construct() or HystrixCommand.run()
在这里,Hystrix通过为此目的编写的方法调用对依赖项的请求,方法如下:
HystrixCommand.run() —返回单个响应或抛出异常
HystrixObservableCommand.construct() — 返回发出响应或发送onError通知的可观察对象
如果run()或construct()方法超过了命令的超时值,线程将抛出TimeoutException(如果命令本身不在自己的线程中运行,则另一个计时器线程将抛出TimeoutException)。在这种情况下,Hystrix将响应路由到8。获取回退,如果该方法没有取消/中断,则它将丢弃最终返回值run()或construct()方法。
请注意,没有办法强制潜在线程停止工作——Hystrix在JVM上能做的最好的事情就是抛出一个InterruptedException异常。如果 Hystrix包装的工作不尊重InterruptedExceptions,那么Hystrix线程池中的线程将继续它的工作,尽管客户机已经收到一个TimeoutException异常。这种行为会使Hystrix线程池饱和,尽管负载被“正确地释放”。大多数Java HTTP客户端库不解释InterruptedExceptions。因此,请确保正确配置HTTP客户机上的连接和读写超时。
如果该命令没有抛出任何异常并返回响应,那么Hystrix在执行一些日志记录和指标报告之后将返回此响应。在run()的情况下,Hystrix返回一个可观察的对象,该对象发出单个响应,然后发出onCompleted通知;对于construct(), Hystrix返回与construct()返回的相同的Observable。
7. Calculate Circuit Health
Hystrix向断路器报告成功、失败、拒绝和超时,断路器维护一组计算统计信息的滚动计数器。
它使用这些统计数据来确定电路应该在什么时候“跳闸”,在这一点上,它将短路任何后续的请求,直到恢复周期结束,在此期间,它在第一次检查某些健康检查之后再次关闭电路。
8. Get the Fallback
Hystrix试图恢复你的回滚命令执行失败时:当一个异常的构造()或()运行(6),当命令电路短路,因为打开(4),当命令的线程池和队列或信号能力(5),或者当命令已超过其超时长度。
编写回退,以便在不依赖任何网络的情况下,从内存缓存或通过其他静态逻辑提供通用响应。如果必须在回退中使用网络调用,则应该通过另一个HystrixCommand或HystrixObservableCommand来实现。
对于HystrixCommand,要提供回退逻辑,需要实现HystrixCommand. getfallback(),它返回一个回退值。
在HystrixObservableCommand的情况下,要提供回退逻辑,需要实现HystrixObservableCommand. resumewithfallback(),它返回一个或多个可回退值。
如果回退方法返回一个响应,那么Hystrix将把这个响应返回给调用者。对于HystrixCommand.getFallback(),它将返回一个发出方法返回值的Observable。对于HystrixObservableCommand.resumeWithFallback(),它将返回与方法返回的Observable相同的值。
如果您没有为您的Hystrix命令实现一个回退方法,或者回退本身抛出一个异常,那么Hystrix仍然返回一个可观察的异常,但是这个异常不会发出任何内容,并立即以onError通知结束。正是通过这个onError通知,导致命令失败的异常才被传输回调用者。(实现可能失败的回退实现是一种糟糕的实践。您应该实现回退,这样它就不会执行任何可能失败的逻辑。
失败或不存在回退的结果将根据您调用Hystrix命令的方式而有所不同:
- execute()——抛出异常
- queue() -成功返回一个Future,但是如果调用该Future的get()方法,该Future将抛出一个异常
- observe() -返回一个Observable,当您订阅它时,它将通过调用订阅者的onError方法立即终止
- toObservable()——返回一个Observable,当您订阅它时,它将通过调用订阅者的onError方法来终止
9. Return the Successful Response
如果Hystrix命令成功,它将以可观察的形式向调用者返回一个或多个响应。根据您在上面步骤2中调用命令的方式,这个可观察的对象可能在返回给您之前被转换:
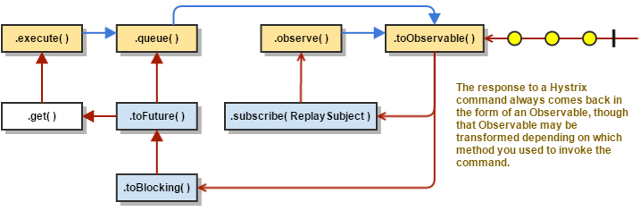
- execute()—以与.queue()相同的方式获取Future,然后对该Future调用get()以获取可观察对象发出的单个值
- queue() -将观察到的对象转换为BlockingObservable,以便将其转换为Future,然后返回该Future
- observer()—立即订阅被观察对象,并开始执行该命令的流;返回一个可观察到的,当您订阅它时,它将回放排放和通知
- toObservable() -返回未改变的Observable;您必须订阅它,以便实际开始执行该命令的流
断路器
下图显示了HystrixCommand或HystrixObservableCommand如何与hystrixcircuit断路器交互,以及它的逻辑和决策流程,包括计数器在断路器中的行为。

电路开闭的精确方式如下:
- 假设通过一个电路的音量达到某个阈值(HystrixCommandProperties.circuitBreakerRequestVolumeThreshold())…
- 假设错误百分比超过阈值错误百分比(hystrixcommandproperties .circuit breakererrorthreshold oldpercentage())…
- 然后断路器从闭合过渡到打开。
- 当它是开着的,它短路了所有对断路器的要求。
- 经过一段时间后(hystrixcommandproperties .circuit breakersleepwindowin毫秒()),下一个请求被允许通过(这是半打开状态)。如果请求失败,断路器在休眠窗口期间返回到打开状态。如果请求成功,断路器转换为闭合,逻辑在1。一遍又一遍。
隔离
Hystrix使用bulkhead模式将依赖项彼此隔离,并限制对其中任何一个的并发访问。
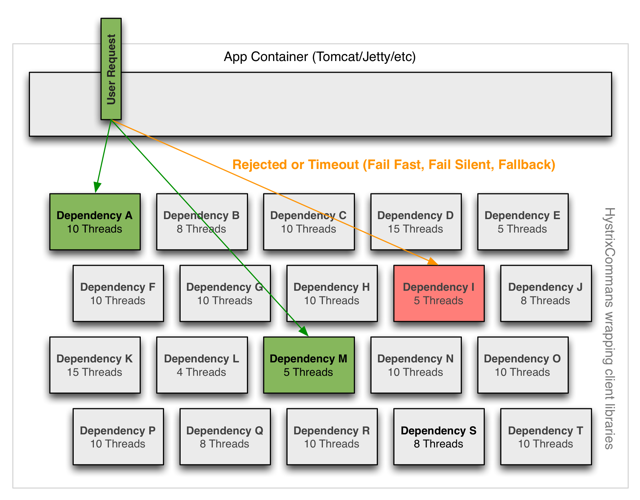
线程和线程池
客户机(库、网络调用等)在不同的线程上执行。这将它们与调用线程(Tomcat线程池)隔离开来,以便调用者可以“离开”耗时过长的依赖项调用。
Hystrix使用单独的、每个依赖项的线程池作为约束任何给定依赖项的一种方式,因此底层执行的延迟将只会使该池中的可用线程饱和。

您可以在不使用线程池的情况下防止失败,但是这要求受信任的客户机非常快地失败(网络连接/读取超时和重试配置),并且始终表现良好。
Netflix在设计Hystrix时,选择使用线程和线程池来实现隔离,原因有很多,包括:
- 许多应用程序对许多不同团队开发的许多不同服务执行数十个(有时甚至超过100个)不同的后端服务调用。
- 每个服务都提供自己的客户端库。
- 客户端库一直在变化。
- 客户端库逻辑可以更改以添加新的网络调用。
- 客户端库可以包含重试、数据解析、缓存(内存中或跨网络)等逻辑,以及其他此类行为。
- 客户端库往往是“黑盒”——对用户不透明的实现细节、网络访问模式、配置默认值等。
- 在几次实际生产中断中,确定是“噢,发生了一些更改,应该调整属性”或“客户端库更改了其行为”。
- 即使客户机本身没有更改,服务本身也会更改,这会影响性能特征,从而导致客户机配置无效。
- 传递依赖项可以引入其他不期望的、可能没有正确配置的客户端库。
- 大多数网络访问是同步执行的。
- 失败和延迟也可能发生在客户端代码中,而不仅仅是在网络调用中。

线程池的好处
通过线程在它们自己的线程池中进行隔离的好处是:
- 应用程序完全受失控客户端库的保护。给定依赖项库的池可以填满,而不会影响应用程序的其余部分。
- 应用程序可以以低得多的风险接受新的客户端库。如果出现问题,则将其隔离到库中,不会影响其他所有内容。
- 当失败的客户机再次恢复健康时,线程池将清空,应用程序将立即恢复健康的性能,而不是在整个Tomcat容器不堪重负时进行长时间的恢复。
- 如果客户端库配置错误,线程池的健康状况将很快证明这一点(通过增加错误、延迟、超时、拒绝等等),您可以在不影响应用程序功能的情况下处理它(通常是通过动态属性实时处理)。
- 如果客户服务更改性能特征(经常发生足以成为问题)进而导致需要调整属性(增加/减少超时,改变重试,等等)又可以通过线程池指标(错误、延迟、超时、拒绝),可以处理而不影响其他客户,请求,或用户。
- 除了隔离的好处之外,拥有专用的线程池还提供了内置的并发性,可以利用并发性在同步客户端库之上构建异步facade(类似于Netflix API如何在Hystrix命令之上构建响应性的、完全异步的Java API)。
简而言之,线程池提供的隔离允许客户端库和子系统性能特征的不断变化和动态组合被优雅地处理,而不会导致停机。
注意:尽管单独的线程提供了隔离,但是您的底层客户端代码也应该有超时和/或响应线程中断,这样它就不会无限期地阻塞和饱和Hystrix线程池。
线程池的缺点
线程池的主要缺点是增加了计算开销。每个命令的执行都涉及到在单独的线程上运行命令所涉及的队列、调度和上下文切换。
Netflix在设计这个系统时,决定接受这种开销的成本,以换取它所提供的好处,并认为它足够小,不会对成本或性能产生重大影响。
线程的成本
Hystrix测量子线程上执行构造()或run()方法时的延迟,以及父线程上的端到端总时间。通过这种方式,您可以看到Hystrix开销的成本(线程、指标、日志记录、断路器等)。
Netflix API每天使用线程隔离处理100多亿次Hystrix命令执行。每个API实例有40多个线程池,每个线程池中有5-20个线程(大多数被设置为10个)。
下图表示在单个API实例上以每秒60个请求的速度执行一个HystrixCommand(每个服务器每秒执行大约350个线程):

在中值(或更低)处,拥有单独的线程没有成本。
在第90个百分位上,使用一个单独的线程需要花费3ms。
在第99百分位上,使用一个单独的线程需要花费9ms。但是请注意,成本的增加远远小于单独线程(网络请求)执行时间的增加,后者从2跳到28,而成本从0跳到9。
对于像这样的电路,这种90%以上的开销被认为是可以接受的,因为Netflix的大多数用例都实现了弹性。
电路,包装非常低延迟请求(比如那些主要是内存中的缓存)的开销可以过高,在这些情况下你可以使用另一种方法,比如tryable信号量,虽然他们不允许超时,提供大部分的弹性福利没有开销。然而,总的来说,开销非常小,以至于Netflix在实践中通常更喜欢单独线程的隔离优势,而不是这种技术。
信号量
您可以使用信号量(或计数器)来限制对任何给定依赖项的并发调用的数量,而不是使用线程池/队列大小。这允许Hystrix在不使用线程池的情况下释放负载,但不允许超时和退出。如果您信任客户机,并且只希望减少负载,那么可以使用这种方法。
HystrixCommand和HystrixObservableCommand在两个地方支持信号量:
- 回退:当Hystrix检索回退时,它总是在调用Tomcat线程上这样做。
- 执行:如果您设置属性execute .isolation。然后Hystrix将使用信号量而不是线程来限制调用该命令的并发父线程的数量。
您可以通过定义可以执行多少并发线程的动态属性来配置这两种信号量的使用。您应该使用与调整线程池大小时类似的计算来确定它们的大小(以亚毫秒为单位返回的内存调用在信号量仅为1或2的情况下可以执行5000rps以上的性能,但默认值是10)。
注意:如果依赖项与信号量隔离,然后成为潜伏的,那么父线程将一直被阻塞,直到底层网络调用超时。
一旦达到限制,信号量拒绝将开始,但是填充信号量的线程不能离开。
请求崩溃
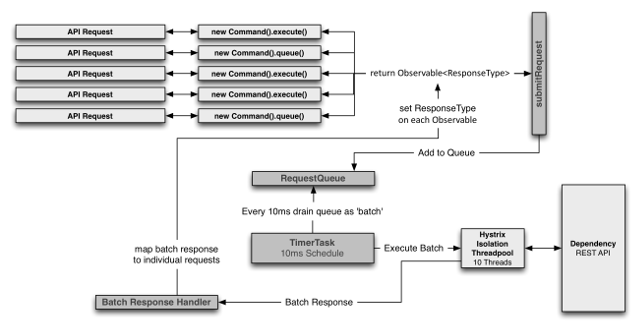
您可以使用一个请求折叠器(hystrix折叠器是抽象父命令)来前置一个HystrixCommand,使用该命令可以将多个请求折叠成一个后端依赖项调用。
下图显示了两种情况下的线程和网络连接数量:首先没有请求崩溃,然后请求崩溃(假设所有连接在短时间窗口内都是“并发”的,在本例中是10ms)。

为什么使用请求崩溃?
使用请求崩溃来减少执行HystrixCommand并发执行所需的线程和网络连接数量。请求崩溃以一种自动化的方式来实现这一点,它不会强迫代码库的所有开发人员协调请求的手动批处理。
全局上下文(跨所有Tomcat线程)
理想的崩溃类型是在全局应用程序级别上完成的,这样来自任何Tomcat线程上的任何用户的请求都可以一起崩溃。
例如,如果您将HystrixCommand配置为支持将请求批处理给检索电影评级的依赖项的任何用户,那么当同一JVM中的任何用户线程发出这样的请求时,Hystrix将把它的请求和其他请求一起添加到同一个崩溃的网络调用中。
请注意,折叠器将向折叠的网络调用传递单个HystrixRequestContext对象,因此下游系统必须处理这种情况,以使其成为有效的选项。
用户请求上下文(单个Tomcat线程)
如果您将HystrixCommand配置为只处理单个用户的批处理请求,那么Hystrix可以从单个Tomcat线程(请求)中折叠请求。
例如,如果用户希望为300个视频对象加载书签,而不是执行300个网络调用,Hystrix可以将它们合并为一个。
对象建模和代码复杂性
有时,当您创建一个对象模型,该模型对对象的使用者具有逻辑意义时,这与对象的生产者对资源的有效利用并不匹配。
例如,给定一个包含300个视频对象的列表,遍历它们并在每个对象上调用getSomeAttribute()显然是一个对象模型,但是如果天真地实现,可能会导致300个网络调用在毫秒内完成(并且很可能会使资源饱和)。
有一些手动的方法可以处理这个问题,比如在允许用户调用getSomeAttribute()之前,要求他们声明他们想要为哪些视频对象获取属性,以便它们都可以被预先获取。
939/5000
或者,您可以分割对象模型,以便用户必须从一个位置获得视频列表,然后从其他位置请求该视频列表的属性。
这些方法会导致笨拙的api和对象模型与心智模型和使用模式不匹配。当多个开发人员处理一个代码库时,它们还可能导致简单的错误和效率低下,因为对一个用例进行的优化可能会被另一个用例的实现和通过代码的新路径所破坏。
通过将折叠逻辑下推到Hystrix层,无论您如何创建对象模型,调用的顺序如何,或者不同的开发人员是否知道正在进行或甚至需要进行优化,都不重要。
getSomeAttribute()方法可以放在最适合它的任何位置,并以适合使用模式的任何方式进行调用,而折叠器将自动将调用批处理到时间窗口中。
请求崩溃的代价是什么?
启用请求崩溃的代价是在实际命令执行之前延迟增加。最大成本是批处理窗口的大小。
如果您的命令执行时间中值为5ms,并且批处理窗口为10ms,那么在最坏的情况下,执行时间可能变为15ms。通常情况下,请求不会在打开时被提交到窗口,因此中间的惩罚是窗口时间的一半,在本例中是5ms。
判断这个代价是否值得,取决于执行的命令。高延迟命令不会因为额外的少量平均延迟而受到很大影响。此外,给定命令的并发量是关键:如果需要批处理的请求很少超过1或2个,那么就没有必要为此付出代价。事实上,在单线程顺序迭代中,崩溃将是一个主要的性能瓶颈,因为每个迭代将等待10ms批处理窗口时间。
但是,如果一个特定的命令被大量并发地使用,并且可以批量处理数十个甚至数百个调用,那么当Hystrix减少所需的线程数量和到依赖项的网络连接数量时,增加的吞吐量通常会大大降低成本。
崩溃流
请求缓存
HystrixCommand和HystrixObservableCommand实现可以定义一个缓存键,然后使用该键以并发感知的方式在请求上下文中去欺骗调用。
下面是一个涉及HTTP请求生命周期和在该请求中执行工作的两个线程的示例流:

请求缓存的好处是:
不同的代码路径可以执行Hystrix命令,而不必担心重复的工作。
这在许多开发人员实现不同功能的大型代码库中特别有用。
例如,代码中的多个路径都需要获取用户的Account对象,每个路径都可以像这样请求它
Account account = new UserGetAccount(accountId).execute();
//or
Observable<Account> accountObservable = new UserGetAccount(accountId).observe();Hystrix RequestCache将只执行一次底层run()方法,而且执行HystrixCommand的两个线程将接收相同的数据,尽管它们实例化了不同的实例。
数据检索在整个请求中是一致的。
与每次执行命令时可能返回不同的值(或回退)不同,将缓存第一个响应,并为同一请求中的所有后续调用返回第一个响应。
消除重复的线程执行。
由于请求缓存位于构造()或run()方法调用之前,Hystrix可以在导致线程执行之前对调用进行反欺骗
如果Hystrix没有实现请求缓存功能,那么每个命令都需要在构造或run方法中自己实现它,该方法将在线程排队并执行之后放置它。















 179
179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









