






操作数据库通常需要你亲自动手处理SQL语句。在Django中,有很多这样的麻烦需要你小心使用Django的对象关系映射(ORM)的功能,以及如何通过Django的模型封装数据库中的表。从本质上讲,一个模型是一个Python对象,描述数据模型/表。而不是直接操作SQL访问数据库表,所有你需要做的就是操纵相应的Python对象。在这一章,我们将介绍如何设置一个数据库和Rango所需的模型。
Rango的需求
首先,我们看看Rango的数据需求。下面的列表提供了Rango数据需求的关键信息。
- Rango是一个基本的网页目录——网站含有其他网站的链接。
- 有许多不同的网页的类别,每个类别容纳许多链接。我们假设在第二章,这是一个一对多的关系。请参阅下面的实体关系图。
- 一个类别有一个名称,访问次数,和不同的喜好。
- 一个页面是指一类,有标题,URL和许多views。

Figure 1: The Entity Relationship Diagram of Rango’s two main entities.
创建你的数据库
在你创建任何models之前,需要设置数据库配置。在Django1.7中,当你创建一个工程,Django会自动创建一个目录叫DATABASES,位于你的setting.py文件中。具体内容如下:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
} 正如你所看到默认的引擎是SQLite3的编译器后端。这为我们提供了轻量级的python数据库访问,SQLite,这是伟大的发展宗旨。我们需要设置其他唯一的值是NAME键/值对,设置为DATABASE_PATH。对于其他数据库引擎,其他键如USER、PASSWORD、HOST和PORT也可以添加到字典。
注释
虽然本教程使用SQLite引擎是很好,当它来部署应用程序时可能也许不是最好的选择。相反,它可能是更好的使用更健壮的和可扩展的数据库引擎。Django自带开箱支持其他几个流行的数据库引擎,如PostgreSQL 和 MySQL。查看数据库引擎的官方Django文档了解更多细节。你也可以看看在SQLite网站上的优秀文章,解释了你应该和你不应该考虑使用轻量级SQLite引擎。
在setting.py中进行数据库配置,你可以为Rango应用程序创建两个初始化数据模型。
在rango/models.py中,我们定义两个类,两个都必须继承django.db.models.Model。两个Python类将定义模型代表类别和页面。定义Category和Page模型如下:
class Category(models.Model):
name = models.CharField(max_length=128, unique=True)
def __unicode__(self): #For Python 2, use __str__ on Python 3
return self.name
class Page(models.Model):
category = models.ForeignKey(Category)
title = models.CharField(max_length=128)
url = models.URLField()
views = models.IntegerField(default=0)
def __unicode__(self): #For Python 2, use __str__ on Python 3
return self.title 当你定义一个模型,您需要指定属性及其相关类型的列表以及任何可选参数。Django提供了大量的内置字段。下面列出一些最常用的。
CharField,用于存储字符数据(strings)。指定max_length提供最大数量的字符字段可以存储。
URLField,和CharField一样,但是是用来存储URLs资源。你也可以指定max_length参数。
IntegerField,用来存储整数。
DateField,用来存储Python的datetime.date。
可以查看 Django文档模型字段来查看完整列表。
在每一个字段,你可以指定
unique属性。如果设置为
True,只有一个实例的一个特定的领域的值可能存在在整个数据库模型。例如,看看我们上面定义的
Category模型。字段
name被设置为唯一的,因此每个类别名称必须是唯一的。
如果你想使用一个特定的域作为一个附加的数据库的键,这非常有用。你也可以为每个字段指定附加属性,如如指定一个默认值(
default='value'),一个字段的值是否可以
NULL(null=True)或没有。
在Django中还提供了简单的机制,使我们能够涉及的模型/数据库表一起。这些机制都封装在三个字段类型,下面列出。
ForeignKey,一个字段类型允许我们创建一对多关系;
OneToOneField,一个字段类型允许我们定义严格一对一关系;
ManyToManyField,一个字段类型允许我们定义多对多关系。
从上面我们的模型示例,在模型
Page中的字段
category是一个
ForeignKey。允许我们在模型/表
category中创建一对多关系,
它被指定作为参数传递给字段的构造。你应该意识到Django会自动为你在涉及到一个模型中的每个表创建一个ID字段。因此你并不需要明确地为每个模型定义一个主键 - 它为你做!
注释
当创建一个Django模型,最好的实践就是确定你创建包含__unicode()方法-这个方法和__str__()方法相同。如果你这两个都不熟悉,认为它们是方法类似于Java类中的toString()方法。因此,__unicode__()方法用于提供一个unicode表示模型的实例。我们的category模型例如返回类别的名称在__unicode__()方法中-当你在本章后面开始使用Django管理接口时这将会非常方便。在你调试代码时在你的类中包含__unicode__()方法也是非常有用的。在category模型实例分配一个__unicode方法会返回<Category: Category object>。我们知道这是一个分类,但是是哪一个呢?包含__unicode__()会返回<Category: python>,python是一个给定的类别name。较前更好!
创建和迁移数据库
我们的模型已经定义了。我们现在可以让Django发挥它的魔力,在我们的数据库中创建表表示。在早期版本的Django使用以下命令执行:
$ python manage.py syncdb然而,Django的1.7提供了一个迁移工具安装和更新数据库以反映变化的模型。所以这个过程就变得有些复杂,但我们的想法是,如果你更改模型,您将能够更新数据库,而无需删除它。
配置数据库并创建超级用户
如果你还没有这样做的话,你首先需要初始数据库。这是通过迁移命令来完成。
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, contenttypes, auth, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying sessions.0001_initial... OK注释
在Django1.8版本中,我们需要先执行python manage.py makemigrations [databasename]然后执行python manage.py migrate
错误提示
Running migrations:
No migrations to apply.
Your models have changes that are not yet reflected in a migration, and so won’t be applied.
Run ‘manage.py makemigrations’ to make new migrations, and then re-run ‘manage.py migrate’ to apply them.
如果你记得在setting.py中有一系列INSTALLED_APPS,这个初始调用迁移,为相关应用程序创建表auth,admin。在你的项目基本目录下有一个db.sqlite可以被调用。
现在您需要创建一个超级用户管理数据库。运行以下命令。
$ python manage.py createsuperuser 在本教程后面超级用户帐户将被用于访问Django的管理界面。根据提示输入帐号的用户名、邮箱地址、密码。一旦完成,该脚本应该成功完成。
确保你把超级用户帐户的用户名和密码记住。
创建/更新模型/表
无论什么时候更改模型,那么你需要办理变更登记,通过makemigrations命令为修改应用程序。对于rango,我们需要执行以下命令:
$ python manage.py makemigrations rango
Migrations for 'rango':
0001_initial.py:
- Create model Category
- Create model Page 如果你查看rango/migration文件,你会看到一个Python脚本被创建,叫0001_initial.py''。查看这个SQL并执行数据迁移,你可以执行命令python manage.py sqlmigrate <app_name> <migration_no>。这个迁移号显示为上面的0001,所以我们可以执行命令,python manage.py sqlmigrate rango 0001-为rango创建执行的SQL语句。尝试一下。
现在应用这些迁移(本质上就是创建数据库表),执行以下命令:
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, rango, contenttypes, auth, sessions
Running migrations:
Applying rango.0001_initial... OK警告
当你添加到现有模型,你需要重复执行命令 python manage.py makemigrations ,然后执行python manage.py migrate
你可能也注意到,我们的category模型是目前所缺乏我们在Rango的要求定义的一些字段。我们会在后面更新过程中提醒你添加这些字段。
Django模型和Django Shell
在我们将注意力转向展示Django管理界面接口之前,值得注意的是,你可以对Django模型和Django Shell进行交互-用于调试是一个非常有用的帮助。我们将演示如何使用这种方法来创建Category的实例。
进入shell,我们需要从你的Django项目root目录下再次调用manage.py。运行以下命令:
$ python manage.py shell这将启动Python解释器和加载对你项目的设置的一个实例。然后,您可以与模型进行交互。下面的终端会话演示了此功能。看看行内注释,以了解每个命令的作用。
# Import the Category model from the Rango application
>>> from rango.models import Category
# Show all the current categories
>>> print Category.objects.all()
[] # Returns an empty list (no categories have been defined!)
# Create a new category object, and save it to the database.
>>> c = Category(name="Test")
>>> c.save()
# Now list all the category objects stored once more.
>>> print Category.objects.all()
[<Category: test>] # We now have a category called 'test' saved in the database!
# Quit the Django shell.
>>> quit() 在这个例子中,我们首先导入我们想要操作的模型。然后打印输出所有已存在的类别,其中没有因为我们的表是空的。在打印出所有类别之前,我们创建并保存一个类别。第二次print应该显示我们刚添加的Category。
注释
在上面提供的例子中,我们只是在一个非常基本的尝试在数据库中执行相关活动的Django shell。如果你还没有这样做的话,这是很好的时间来完成Django官方教程的一部分,详细了解与模型进行交互。查看官方Django文档的可用命令列表处理模型。
配置Admin接口
Django的突出特征之一是它提供了一个内置的,基于web的管理接口,使我们能够浏览和编辑数据存储在我们的模型中和相应的数据库表。在setting.py文件中,你会注意到其中一个预装应用程序你会注意到其中一个预装应用程序,在你的项目urls.py中有一个urlpattern与之相匹配的admin/。
启动开发服务器:
$ python manage.py runserver 访问url http://127.0.0.1:8000/admin/。你应该能够使用为超级用户创建的用户名和密码登录到Django管理界面。这个管理接口只包含网站相关的表,Groups和Users。所以我们需要从rango指示Django去包含模型。
需要以下操作,打开rango/admin.py文件并添加以下代码:
from django.contrib import admin
from rango.models import Category, Page
admin.site.register(Category)
admin.site.register(Page) 将在管理接口注册模型。如果还有其他模型,它将会简单调用admin.site.register()函数,作为参数传递模型。
所有这些做出变化,重新访问/刷新:http://127.0.0.1:8000/admin/。你现在应该可以看到分类和页面模型,就像在图2。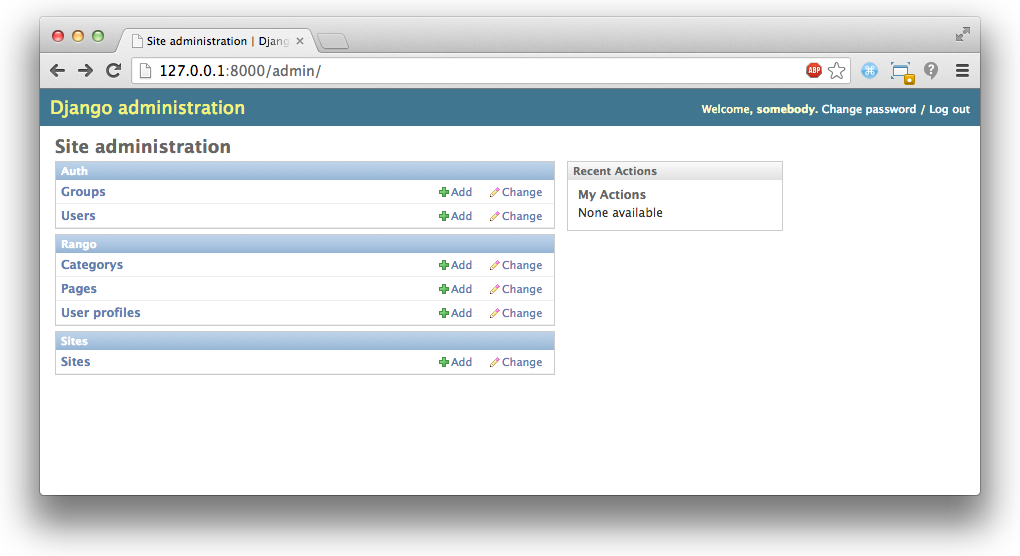
Figure 2: The Django admin interface. Note the Rango category, and the two models contained within.
尝试在Rango区域点击Category链接。从这里,你应该可以看到我们之前通过Django shell创建的test类。尝试删除类别,因为我们接下来将要使用population 脚本填充数据库。易于使用的接口。花费几分钟创建、修改和删除Categories和Pages。你也可以为你的项目添加一个可以登录Django管理界面的新用户通过添加一个用户到User在Auth应用程序中。
注释
注意在管理界面中的错字(是category不是categories)。这个问题可以通过添加嵌套Meta类到模型中定义的verbose_name_plural属性。查看模型的Django官方文档了解更多信息。注释
这案例的admin.py文件对于我们的Rango应用程序非常简单、功能可用的例子。有许多不同的功能,你可以在admin.py用于执行各种很酷的定制,如在管理界面改变模型的方式显示。在本文档中,我们将坚持基本的管理界面,如果你感兴趣的话,你可以查看Django官方文档管理接口相关的文档以了解更多的信息。
创建Population 脚本
测试数据输入到数据库往往是一个麻烦。许多开发人员会加入一些虚假的测试数据通过随机敲打键盘就像猴子试着写莎士比亚一样。如果你是在一个小开发团队,每个人都必须输入一些数据。而不是单独做到这一点,最好是写一个脚本,使每个人都有相似的数据,并且让每个人都有益的和适当的数据,而不是垃圾的测试数据。所以这是很好的做法,为您的数据库创造我们所谓的Population脚本。这个脚本给你用来自动填充数据库测试数据。
为Rango的数据库创建一个Population脚本,我们首先在Django项目的根目录创建一个新的Python模块(<workspace>/tango_with_django_project/)。创建一个populate_rango.py文件和添加如下代码。
import os
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'tango_with_django_project.settings')
import django
django.setup()
from rango.models import Category, Page
def populate():
python_cat = add_cat('Python')
add_page(cat=python_cat,
title="Official Python Tutorial",
url="http://docs.python.org/2/tutorial/")
add_page(cat=python_cat,
title="How to Think like a Computer Scientist",
url="http://www.greenteapress.com/thinkpython/")
add_page(cat=python_cat,
title="Learn Python in 10 Minutes",
url="http://www.korokithakis.net/tutorials/python/")
django_cat = add_cat("Django")
add_page(cat=django_cat,
title="Official Django Tutorial",
url="https://docs.djangoproject.com/en/1.5/intro/tutorial01/")
add_page(cat=django_cat,
title="Django Rocks",
url="http://www.djangorocks.com/")
add_page(cat=django_cat,
title="How to Tango with Django",
url="http://www.tangowithdjango.com/")
frame_cat = add_cat("Other Frameworks")
add_page(cat=frame_cat,
title="Bottle",
url="http://bottlepy.org/docs/dev/")
add_page(cat=frame_cat,
title="Flask",
url="http://flask.pocoo.org")
# Print out what we have added to the user.
for c in Category.objects.all():
for p in Page.objects.filter(category=c):
print "- {0} - {1}".format(str(c), str(p))
def add_page(cat, title, url, views=0):
p = Page.objects.get_or_create(category=cat, title=title)[0]
p.url=url
p.views=views
p.save()
return p
def add_cat(name):
c = Category.objects.get_or_create(name=name)[0]
return c
# Start execution here!
if __name__ == '__main__':
print "Starting Rango population script..."
populate() 虽然这看起来像很多代码,它是相对简单的。作为我们定义一系列函数在文件的前面,代码执行开始向底部-查找一行if __name__ == '__main__'。我们调用populate()函数。
警告
当导入Django的模型,请确保您已通过导入Django和设置环境变量
DJANGO_SETTINGS_MODULE在项目设置文件中。然后你可以调用django.setup()导入django设置。如果没有,会有一个异常抛出。这就是我们为什么在设置加载后导入Category和Page。
这个populate()函数负责调用add_cat()和cat_page()函数,他们负责分别创建新的类别和页面。populate()为我们密切关注类别引用作为我们创建的每一个Page模型实例和存储它们到我们的数据库中。最后,我们通过我们的Category和Page模型循环输出给用户的所有page实例及相应的类别。
注释
我们使用的便利性get_or_create()方法来创建模型实例。由于我们不希望创建同一条目的副本,我们就可以使用get_or_create(),以检查我们的条目是否存在在数据库中。如果它不存在,该方法创建它。
他可以为我们免去很多重复的代码-而不是做这种费力检查自己,我们可以利用这些代码为我们做正确的事。正如我们前面所提到的,如果它已经有了,为什么要重新发明轮子?
get_or_create()方法返回元组(object, created)。这第一个元素object是应用模型实例,如果没有在数据库目录中找到就调用get_or_create()方法创建一个。目录如果已经创建使用参数传递到该方法-就像上面实例中的Category、title、url和views。如果条目已经存在于数据库中,该方法只返回与此项对应的模型实例。created是一个boolean值;如果get_or_create()已经创建了一个模式实例则返回true。
在我们调用这方法结尾的[0]去检索get_or_create()方法返回object的一部分元组。像大多数其他编程语言的数据结构,Python元组使用从零开始的编号。
你可以查看官方Django文档了解更多get_or_create()方法的信息。
保存后,我们可以通过改变当前终端的工作目录到我们的Django项目的根并执行模块的命令运行该脚本$ python populate_rango.py。您应该看到类似如下所示的输出。
$ python populate_rango.py
Starting Rango population script...
- Python - Official Python Tutorial
- Python - How to Think like a Computer Scientist
- Python - Learn Python in 10 Minutes
- Django - Official Django Tutorial
- Django - Django Rocks
- Django - How to Tango with Django
- Other Frameworks - Bottle
- Other Frameworks - Flask 现在让我们验证填充脚本填充的数据库。重新启动Django开发服务器,导航到管理界面,查看你有一些新的分类和页面。看到的所有pages是否如图3所示?
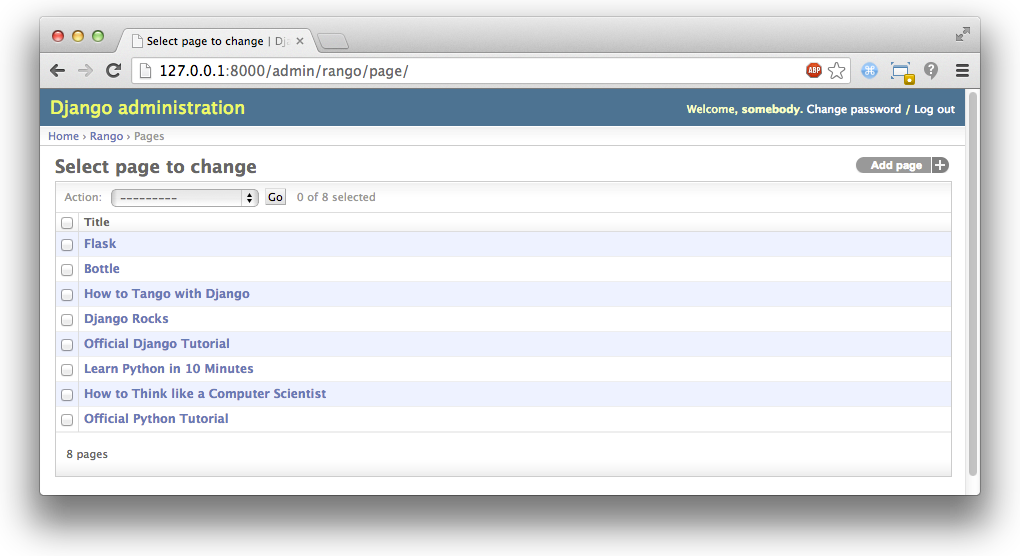
Figure 3: The Django admin interface, showing the Page table populated with sample data from our population script.
基本工作流程
现在我们已经介绍了处理Django的模型功能的核心原理,现在是一个很好的时间来总结参与制定的一切行动的进程。我们已经为你把核心任务分割成独立的部分。
配置你的数据库
在一个新的Django项目中,你应该首先告诉Django你打算使用的数据库(在setting.py中配置DATABASES)。您也可以注册在admin.py文件中的任何类型,使他们通过管理界面进行访问。
添加一个模型
工作流添加模型可以分为五个步骤。
- 在你Django应用程序的`models.py`文件中创建一个新的模型;
- 更新`admin.py`并注册你的新模型
- 执行迁移`$ python manage.py makemigrations`
- 应用更改`$ python manage.py migrate`。这将为您的新模型(s)在数据库中创建必要的基础结构。
- 为你的新模型创建/编辑填充脚本。
总是会有时候,你将不得不删除您的数据库。在这种情况下,您将不得不运行migrate命令,然后执行createsuperuser命令,其次是为每个应用程序执行sqlmigrate命令,然后你可以填充数据库。
练习
现在您已经完成了一章,尝试这些练习来巩固和实践你学到的。
- 更新分类模型包括额外的属性,
views和likes默认值为0
- 迁移应用程序/模型,然后迁移数据库
- 更新你的填充脚本使Python分类为128
views和64likes,Django分类拥有64views和32likes,其他框架的类别有32views和16likes。
- 如果你还没有这样做,承接Django官方教程的第二部分。这将有助于进一步巩固你在这儿学到,并了解更多有关自定义的管理界面。
- 定制管理界面,所以当你查看页面模型显示在类别列表,页面的名称和url。
提示
如果你需要一些帮助或灵感来完成这些练习,希望这些提示能够帮助你。
- 通过添加字段,
views和likes为IntegerFields来修改Category模型。
- 修改
populate.py脚本中的add_cat函数,去获取views和likes。一旦你得到了Category c,这是你可以更新c.views中的views数,likes也是一样。
- 定制管理界面,你需要编辑rango/admin.py和创建一个
PageAdmin类继承于admin.ModelAdmin。
- 在你新的PageAdmin类中,添加
list_display = ('title', 'category', 'url')。
- 最后,在Django管理界面注册
PageAdmin。你应该修改admin.site.register(Page)。在admin.py文件中改变为admin.site.register(Page, PageAdmin)。
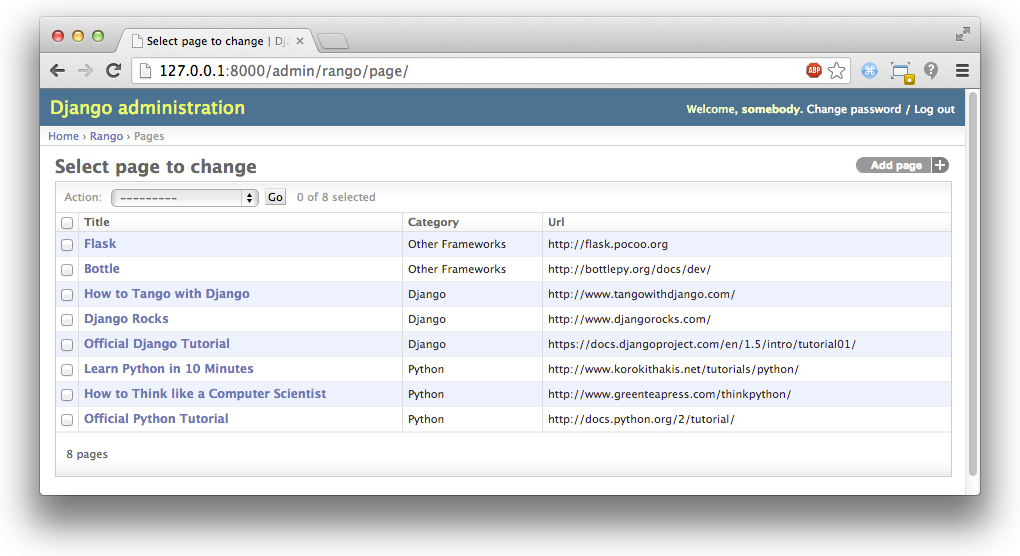
Figure 4: The updated admin interface page view, complete with columns for category and URL.















 1225
1225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









