







 本文介绍了一个工作需求解决方案:通过开发Chrome插件定时刷新页面来维持登录状态,避免每天手动复制cookie。文章详细阐述了插件的开发过程,包括项目目录结构、manifest.json、hello.html和content.js的配置,以及如何将插件安装到Chrome中进行测试。
本文介绍了一个工作需求解决方案:通过开发Chrome插件定时刷新页面来维持登录状态,避免每天手动复制cookie。文章详细阐述了插件的开发过程,包括项目目录结构、manifest.json、hello.html和content.js的配置,以及如何将插件安装到Chrome中进行测试。
最近工作上有一个需求:每天爬取某个网站登录之后的页面信息.但是网站有一定的反爬机制,无法使用python模拟用户名登录,每次都是页面登录后复制cookie到代码中模拟登录信息进行数据爬取.
这么做的缺点就是每天进行数据抓取前,必须先打开浏览器登录–F12打开控制台–找到请求的cookie-- 复制并粘贴到代码中.
如果浏览器能保持用户登录状态,那么就不用每天换cookie,直接运行爬虫代码就好了!
1. 准备工具
1 :一台不关机的电脑(我的是阿里云),用于保持用户的登录状态
2 :开发一个chrome插件,定时刷新指定页面,保证session有效性
2. 项目目录结构
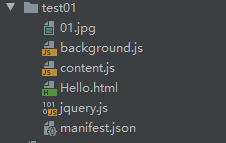
分析:
01.jpg => 理论上是显示在插件上的图标,但是不知道为什么我这么配置没有显示出来
manifest.json => 任何插件都必须要有这个文件,用来描述插件的元数据,插件的配置信息。
hello.html => 用于显示点击插件后的内容
content.js => 用于写js脚本 文件名不重要 主要是看配置在哪里
3.manifest.json
{
"name": "Hello Extensions",
"description": "Hello world Extension",
"version": "1.0",
"manifest_version": 2,
"background": {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9180
9180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









