






- CASE_SENSITIVE参数的作用
1、定义
大小写敏感设置下,模式名、对象名、表名、字段名,默认小写会转为大写,除非双引号括起来表示小写,对于查询条件中是区分大小写字符的,查询结果也是区分大小写字符的。而大小写不敏感设置下,模式名、对象名、表名、字段名大小写会自动区分,不用单独加双引号表示小写,查询添加中不区分大小写字符,查询结果也不区分大小写字符。此参数是一个只读参数,只有初始化实例时才能指定。
- 数据库参数设置查看
- 通过select case_sensitive()查看。

为1表示大小写敏感,为0表示大小写不敏感。
- 通过SELECT SF_GET_CASE_SENSITIVE_FLAG()查看

- 通过dm.ini配置文件确定

- 数据操作区别
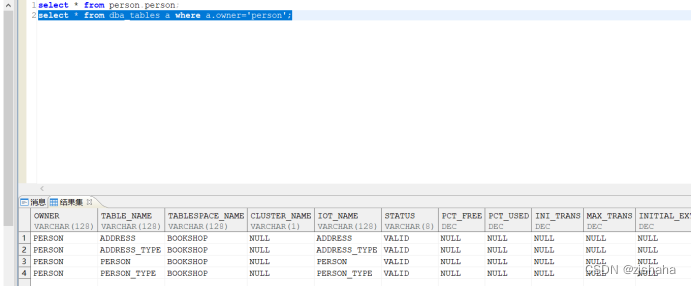
- 对于大小写敏感的数据库,查询数据字典表中数据都需要用大写。例如:

而如果把表名修改为小写是查询不到数据的:

- 对于大小写名字不敏感的库,使用大写写都能差查到,例如:、
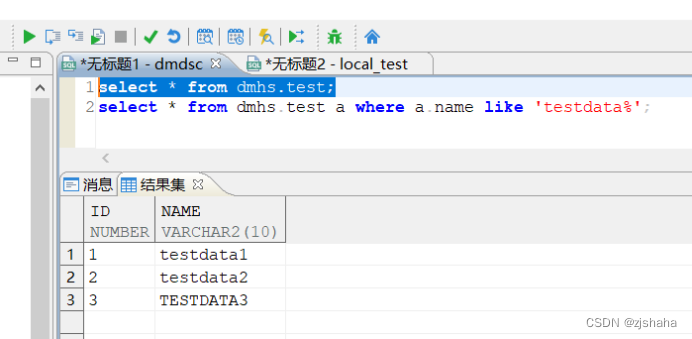
- 测试表中插入不同大小写数据测试
对于大小写敏感的库,查询出来的结果是区分大小写的。
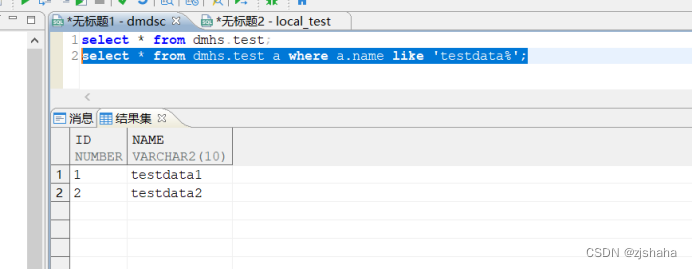
对于大小不敏感的库,查询出来的结果是不分大小写的

- CHARSET,LENGTH_IN_CHAR
- 参数解释
LENGTH_IN_CHAR是初始化数据库时一个参数,数据库创建后不能修改,需要建库的时候考虑好,此参数决定了数据库中的VARCHAR类型对象的长度是否以字符为单位。取值为1或者Y则设置为以字符为单位,将存储长度值按照理论字符长度进行放大。取值为0或者N则所有 VARCHAR 类型对象的长度以字节为单位不管如何定义,实际能插入的字符串占用总字节长度仍然不能超过 8188的上限。
CHARSET 字符集选项。 取值:0代表GB18030,1代表UTF-8,2代表韩文字符集 EUC-KR。默认为 0。
- 查询参数
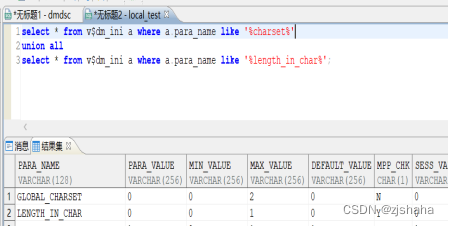
1)、charset查询
select sf_get_unicode_flag();
select unicode();
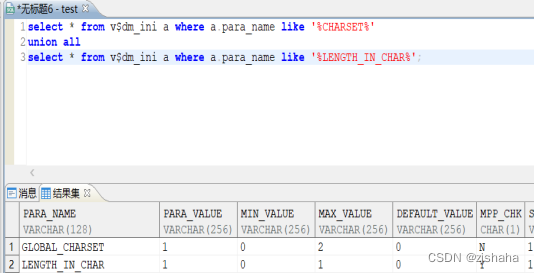
select * from v$dm_ini a where a.para_name like '%charset%';
- 、length_in_char查询
select sf_get_length_in_char();
select * from v$dm_ini a where a.para_name like '%length_in_char%';
- 常见的四种组合
1).CHARSET=0,LENGTH_IN_CHAR=0
这是初始化数据库时的默认配置,字符集为gb18030,varchar长度以字节为单位,汉字一般需要占用两个字节
2).CHARSET=1,LENGTH_IN_CHAR=0
字符集为UTF-8,varchar长度以字节为单位,汉字一般占据三个字节
3).CHARSET=0,LENGTH_IN_CHAR=1
字符集为GB18030,在length_in_char=1的情况下,varchar按字符来计数,varchar的实际可存储字节数会按2倍的比例放大,例如定义varchar(10),那么就可以存储10 * 2 = 20个字节的数据
4).CHARSET=1,LENGTH_IN_CHAR=1
字符集为UTF-8,varchar长度以字符为单位,varchar的实际存储字节数会按4倍的比例放大,例如定义varchar(10),那么就可以存储10 * 4 = 40个字节的数据
- CHARSET,LENGTH_IN_CHAR案例测试
create table test(c1 varchar(10));
- UNICODE_FLAG=0,LENGTH_IN_CHAR=0
插入10个英文,正常
insert into test(c1) values('ABCDEFGHIJ');

插入11个英文,错误
insert into test(c1) values('ABCDEFGHIJA');

插入5个中文,正常
insert into test(c1) values('测试一下测');

插入6个中文,错误
insert into test(c1) values('测试一下测试');

2、UNICODE_FLAG=0,LENGTH_IN_CHAR=1
--插入10个英文,正常
insert into test(c1) values('ABCDEFGHIJ');
--插入11个英文,正常
insert into test(c1) values('ABCDEFGHIJA');
--插入20个英文,正常
insert into test(c1) values('ABCDEFGHIJABCDEFGHIJ');
--插入21个英文,错误
insert into test(c1) values('ABCDEFGHIJABCDEFGHIJA');
--插入10个中文,正常
insert into test(c1) values('测试一下测试一下测试');
--插入11个中文,错误
insert into test(c1) values('测试一下测试一下测试一');
--插入10个中文1个英文,错误
insert into test(c1) values('测试一下测试一下测试A');
3、UNICODE_FLAG=1,LENGTH_IN_CHAR=0
--插入10个英文,正常
insert into test(c1) values('ABCDEFGHIJ');
--插入11个英文,错误
insert into test(c1) values('ABCDEFGHIJA');
--插入5个中文,正常
insert into test(c1) values('测试一');
--插入5个中文1个英文,正常
insert into test(c1) values('测试一A');
--插入6个中文,错误
insert into test(c1) values('测试一下');
--插入5个中文2个英文,错误
insert into test(c1) values('测试一AB');
- UNICODE_FLAG=1,LENGTH_IN_CHAR=1
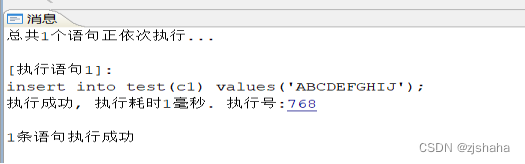
--插入10个英文,正常
insert into test(c1) values('ABCDEFGHIJ');
--插入20个英文,正常
insert into test(c1) values('ABCDEFGHIJABCDEFGHIJ');

--插入40个英文,正常
insert into test(c1) values('ABCDEFGHIJABCDEFGHIJABCDEFGHIJABCDEFGHIJ');

--插入41个英文,错误
insert into test(c1) values('ABCDEFGHIJABCDEFGHIJABCDEFGHIJABCDEFGHIJA');

--插入10个中文,正常,中文占3个字节
insert into test(c1) values('测试一下测试一下测试');

--插入13个中文,正常
insert into test(c1) values('测试一下测试一下测试一下测');

--插入14个中文,错误
insert into test(c1) values('测试一下测试一下测试一下测试');

--插入13个中文1个英文,正常
insert into test(c1) values('测试一下测试一下测试一下测A');

--插入13个中文2个英文,错误
insert into test(c1) values('测试一下测试一下测试一下测AB');
















 907
907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











