







问题为hdu2196,运用的算法为动态规划中的树形DP,问题规模较大,枚举不适合,贪心算法又不能最优解,因此用动态规划中的树形DP。
问题描述
前段时间,一所学校买了第一台电脑(所以这台电脑的ID是1)。近年来,学校购买了N-1新电脑。每台新计算机都连接到较早解决的计算机之一。学校的管理人员担心网络功能缓慢,并想知道i-th计算机需要发送信号的最大距离Si(即电缆长度到最远的计算机)。您需要提供此信息。
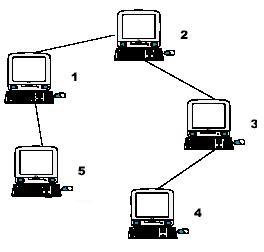
提示:示例输入与此图相对
应。从图表中,你可以看到计算机 4 离 1 最远,所以 S1 = 3。计算机 4 和 5 是离 2 最远的, 所以 S2 = 2 。计算机 5 是离 3 最远的一个, 所以 S3 = 3 。我们也得到 S4 = 4, S5 = 4 。
提示:示例输入与此图相对
应。从图表中,你可以看到计算机 4 离 1 最远,所以 S1 = 3。计算机 4 和 5 是离 2 最远的, 所以 S2 = 2 。计算机 5 是离 3 最远的一个, 所以 S3 = 3 。我们也得到 S4 = 4, S5 = 4 。
输入
输入文件包含多个测试案例。在每种情况下,第一行都有自然编号 N(N<=10000),然后是带有计算机描述的 (N-1) 行。i-th 线包含两个自然数字 - 计算机数量(连接到计算机的计算机数量和用于连接的电缆长度)。电缆总长度不超过 10×9。输入行中的数字由空间分隔。
输出
对于每个案例输出 N 行。i-th 行必须包含 i-th 计算机的 Si 号 (1<=i<=N)。
首先是对问题分析建立,对任意一点建立子树如图中的2为顶点的电脑,从2出发对他的子树进行DFS广度遍历,记录最大深度,求得L1为最远距离。为了求全部的最远距离需要返回每个节点的最大深度,实际上每个节点都计算了两个距离,即one和two第二长距离。例如2电脑中的距离为电脑5和电脑4。
void dfs1(int father) {
int one = 0, two = 0;
for (int i = 0; i <= tree[father].size(); i++) {
Node child = tree[father][i];
dfs1(child.id);
int cost = dp[child.id][0] + child.cost;
if (cost >= one) {
two = one;
one = cost;
}
if (cost < one && cost > two)
two = cost;
}
dp[father][0] = two;
dp[father][1] = two;
}当电脑的距离并不如图中所示,也就是分钟更多支线即3和3以上的时候,就需要对其进行另一种解答。将他分成两段,例如2上面还有6,7,8,9这种。将其看成(6,7,8,9)和(2,1,3,4,5)两端。求后一项的时候就要对分别的路径求最长距离L2。甚至是L2中的次长距离two。如果节点刚好在父节点6上最长子树的话,就是two+最长距离。如果不在最长子树上的话,就是one+最长距离。
void dfs2(int father) {
for (int i = 0; i < tree[father].size(); i++) {
Node child = tree[father][i];
if (dp[child.id][0] + child.cost == dp[father][0])
dp[child.id][2] = max(dp[father][2], dp[father][1]) + child.cost;
else
dp[child.id][2] = max(dp[father][2], dp[father][0]) + child.cost;
dfs2(child.id);
}
}综上,求对节点2最远距离就是Max{L1,L2}。用dfs1去实现求解,dfs2实现距离区别和计算。
状态设计:节点i的子树到i的最长距离dp[i][0]以及次长距离dp[i][1];如果是节点i往上还有的话就是最长距离dp[i][2],需要对是否在父节点最长距离上判断。
以下是全局代码:
#include<stdc++.h>
using namespace std;
const int N = 10100;
struct Node{
int id;
int cost;
};
vector<Node>tree[N];
int dp[N][3];
int n;
void init_read() {
for (int i = 1; i <= n; i++)
tree[i].clear();
memset(dp, 0, sizeof(dp));
for (int i = 2; i <= n; i++) {
int x, y;
scanf("%d%d", &x, &y);
Node tmp;
tmp.cost = y;
tmp.id = i;
tree[x].push_back(tmp);
}
}
void dfs1(int father) {
int one = 0, two = 0;
for (int i = 0; i <= tree[father].size(); i++) {
Node child = tree[father][i];
dfs1(child.id);
int cost = dp[child.id][0] + child.cost;
if (cost >= one) {
two = one;
one = cost;
}
if (cost < one && cost > two)
two = cost;
}
dp[father][0] = two;
dp[father][1] = two;
}
void dfs2(int father) {
for (int i = 0; i < tree[father].size(); i++) {
Node child = tree[father][i];
if (dp[child.id][0] + child.cost == dp[father][0])
dp[child.id][2] = max(dp[father][2], dp[father][1]) + child.cost;
else
dp[child.id][2] = max(dp[father][2], dp[father][0]) + child.cost;
dfs2(child.id);
}
}
int main() {
while (~scanf("%d", &n)) {
init_read();
dfs1(1);
dp[1][2] = 0;
dfs2(1);
for (int i = 1; i <= n; i++)
printf("%d\n", max(dp[i][0], dp[i][2]));
}
return 0;
}因为是对每个节点单独做一次深度遍历,所以总复杂度是O(n^2),但由于提莫规模复杂度过大,复杂度只能是O(nlog2n)。dfs1和dfs2都是O(n)。
数媒201wpy















 501
501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









