






一、什么是Hadoop:
随着移动设备的广泛使用和互联网的快速发展,数据的增量和存量快速增加,硬件发展跟不上数据发展,单机很多时候已经无法处理 TB、PB 级别的数据。如果一头牛拉不动货物,那么选择找几头牛一起拉货物比培育一头更强壮的牛更加容易。同理,对于单机无法解决的问题,综合利用多个普通机器的做法比打造一台超级计算机的做法可行性更高。这就是 Hadoop 的设计思想。Hadoop由Apache软件基金会开发,是一个开源的、可靠的、可扩展的、用于分布式计算的分布式系统基础框架。Hadoop允许用户使用简单的编程模型在计算机集群中对大规模数据集进行分布式处理。Hadoop旨在从单一的机器扩展到成千上万的机器,将集群部署在多台机器中,每台机器提供本地存储和计算服务。每台机器上有一个或多个节点,Hadoor存储的数据将备份在多个节点中以提升集群的可用性,当一个节点宕机时,其他节点依然可以提供数据备份和计算服务。
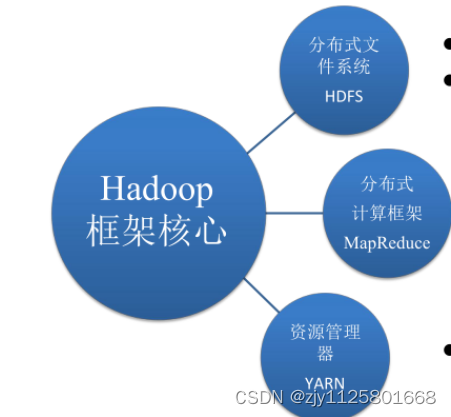
Hadoop框架核心的设计是 Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)和分布式计算框架MapReduce。HDFS是可扩展、高容错、高性能的分布式文件系统,负责数据的分布式存储和备份,文件写入后只能读取,不能修改。MapReduce是分布式计算框架,包含Map(映射)和Reduce(归约)两个阶段。
二、了解 Hadoop 的发展历史
Hadoop是由 Apache 软件基金会的Lucence项目创始人道格·卡廷创建的,Lucence 是一个应用广泛的文本搜索系统库。Hadoop起源于开源的网络搜索引擎utch,Nutch本身也是Lucence 项目的一部分
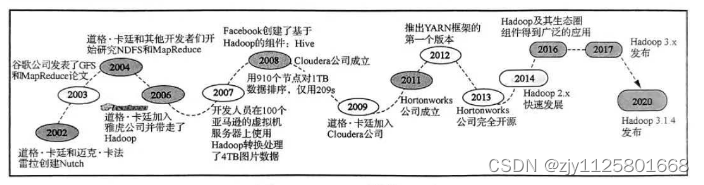
Nutch项目开始于2002年,当时互联网第一轮泡沫刚刚结束,道格·卡廷和迈克·卡法雷拉(MikeCafarella)认为网络搜索引擎由一家互联网公司垄断十分可怕,信息的入口将被该公司掌握,因此决定开发一个可以代替当时主流搜索产品的开源搜索引擎,并将该项目命名为 Nutch。Nutch 致力于提供开源搜索引擎所需的全部工具集。但后来,两位开发者发现这一架构的灵活性不足,只能支持几亿条数据的抓取、索引和搜索,不足以解决数十亿网页的搜索问题。
2003年,谷歌公司发表的 The Google File System 论文描述了谷歌公司产品的架构 GFS(Google File System,谷歌文件系统)。Nutch的开发者们发现 GFS架构能够满足网页抓取和搜索过程中生成的超大文件存储需求,更重要的是,GFS能够节省系统管理所使用的大量时间。于是在 2004年,Nutch的开发者们借鉴谷歌公司新技术开始进行开源版本的实现,即 Nutch 分布式文件系统(Nutch Distributed File System,NDFS)。不同的是,谷歌公司使用的是 C++语言,而 Nutch的开发者们使用的是 Java 语言。
2004年,歌公司发表了论文MapReduce:SimplifiedDataProcessingonLargeClusters,向全世界介绍了MapReduce 框架。Nutch 的开发者们发现谷歌公司的 MapReduce框架可以解决大规模数据的处理问题,因此Nutch的开发者们基于歌公司发表的
MapReduce:Simplified Data Processi
ng on Large Clusters 论文模们了谷歌公司的 MapRedce框架的设计思路,使用Java设计并实现了一套新的MapReduce并行处即软件系统,在Nutch上开发了一个可工作的 MapReduce 框架。
2006年,道格·卡廷加入雅虎公司,并将NDFS和MapReduce框架移出了Nutch,命名为 Hadoop,该名称源于道格·卡廷儿子的一只玩具象。雅虎公司为Hadoop 项目组织了一个专门的团队,并提供了资源,致力将Hadoop发展为可以处理海数据的分布式框架道格·卡廷加入雅虎公司后,Hadoop项目得到了迅速发展。Hadoop集规模从一开始的几十台机器发展至上千台机器,中间进行了很多工程性质的工作。此外,雅虎公司系步将公司的广告系统的数据挖掘相关工作也迁移至Hadoop上,进一步促进了Hadoop 系统的发展。
2007年,开发人员在100个亚马逊公司的虚拟机服务器上使用Hadoop转换处理了4TB
的图片数据,加深了人们对 Hadoop 的印象。2008年,一位谷歌公司的工程师发现要将当时的Hadoop 放至任意一个集群中运行是一件很困难的事情,因此与几个好朋友成立了一家专注于商业化Hadoop的公司 Cloudera。同年,Facebook 团队发现大多数分析人员编写MapReduce 程序难度较大,而对SOL语句更加熟悉,因此 Facebook团队在 Hadoop的基础上开发了一个数据仓库工具 Hive,专门将SOL语句转换为 Hadoop 的 MapReduce 程序。2008年1月,Hadoop已经成为Apache软件基金会的顶级项目之一2008年4月,Hadoop打破世界纪录,成为当时最快的TB级数据排序系统。在一个有910个节点的集群中,Hadoop在209s内完成了对1TB数据的排序,刷新了前一年的纪录
297s。2009年,道格·卡廷加人Cloudera公司,致力于Hadoop软件的多用途技术开发。2011年,雅虎公司将Hadoop项目独立并成立了一个子公司Hortonworks,专门提供Hadoop 相关的服务。
2012年,Hortonworks 公司推出了与原框架有很大不同的YARN 框架的第一个版本从此对 Hadoop 的研究又迈进一个新的层面。
2013年,大型IT公司,如 EMC、Microsoft 、Intel、Teradata、Cisco 等都明显增加了 Hadoop
方面的投人,Hortonworks公司宣传要100%开源软件,Hadoop2.0转型基本上无可阻挡。2014年,Hadoop 2.x的更新速度非常快,从Hadoop2.3.0至Hadoop2.6.0,极大地完善了 YARN 框架和整个集群的功能。很多 Hadoop 的研发公司如 Cloudera、Hortonworks 等都与其他企业合作,共同开发 Hadoop的新功能。
2016年,Hadoop及其生态圈组件(如Hive、HBase、Spark等)在各行各业落地并且得到广泛的应用,YARN 框架也在持续发展以支持更多的应用。
2017年,Hadoop3.0.0开始计划发布,并于2017年12月发布3.0.0的GA(GeneraAvailability,正式发布)版本,该版本修复了6242个问题,Hadoop 3.x正式开始使用。从 Hadoop 3.x系列版本发布开始,Hadoop版本还在不断地优化、更新。2020年8月3日3.x系列 Hadoop发布了第2个GA版本Hadoop 3.1.4,意味着Hadoop的API(ApplicationProgram Imnterface,应用程序接口)稳定性和质量均有了保障。
三、了解 Hadoop 的特点
Hadoop 是一个能够让用户轻松搭建和使用的分布式计算平台,用户可以在Hadoop上
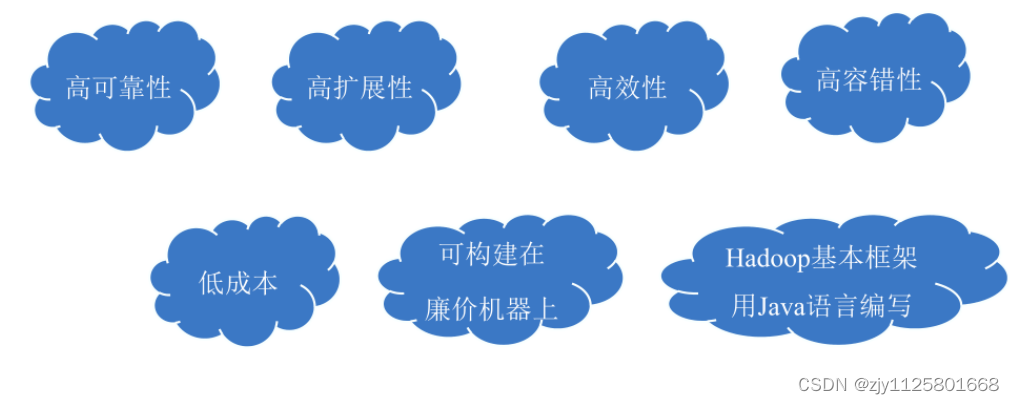
开发和运行处理海量数据的应用程序。Hadoop的主要特点如下。(1)高可靠性。数据存储有多个备份,集群部署在不同机器上,可以防止一个节点名机造成集群损坏。当数据处理请求失败时,Hadoop将自动重新部署计算任务。Hadoop框架中有备份机制和检验模式,可以对出现问题的部分进行修复,也可以通过设置快照的方式在集群出现问题时回到之前的一个时间点。
(2)高扩展性。Hadoop是在可用的计算机集群间分配数据并完成计算任务的。为集群添加新的节点并不复杂,因此集群可以很容易地进行节点的扩展,以扩大集群。
(3)高效性。Hadoop可以在节点之间动态地移动数据,在数据所在节点进行并行处理并保证各个节点的动态平衡,因此处理速度非常快。
(4)高容错性。HDFS 在存储文件时将在多台机器或多个节点上存储文件的备份副本当读取该文件出错或某一个节点宕机时,系统会调用其他节点上的备份文件,保证程序顺利运行。如果启动存储的任务失败,那么Hadoop 将重新运行该任务或启用其他任务来完成失败的任务中没有完成的部分。
(5)低成本。Hadoop 是开源的,即不需要支付任何费用即可下载并安装使用,节省了软件购买的成本。
(6)可构建在廉价机器上。Hadoop不要求机器的配置达到极高的水准,大部分普通商用服务器即可满足要求,通过提供多个副本和容错机制提高集群的可靠性。
(7)Hadoop基本框架用Java语言编写。Hadoop是一个用Java语言开发的框架,因此运行在 Linux 系统上是非常理想的。Hadoop上的应用程序也可以使用其他语言编写,















 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









