






上篇文章中我们介绍了一种文本相似度计算的模型,今天我们来说说一种相同复杂场景下的字段处理方案。
数据字段的处理,使用SQL函数对要处理的字段进行加工。一般来说处理过程如下:
(1)确定各字段的处理规则;
(2)对要处理的字段进行分批;
(3)编写处理SQL,每一批写成一条处理SQL,采用以下格式:
DROP TABLE IF EXIST XX
CREATE TABLE XX ENGINE=YY AS SELECT * FROM ZZ
复杂场景下的字段处理流程和上述数据字段基本处理完全一致。实现的具体SQL中,总结出来一个高效的方法。关键还是来自于clickhouse提供了数组类型的支持,提供了lambda函数支持,即在函数中提供自lambda表达式的自定义处理过程。
例如下面这个例子展现的是将一个加密的JSON字段转换成解密后的HTML字段,具体操作如下图所示:

转换前的字段格式如下图:
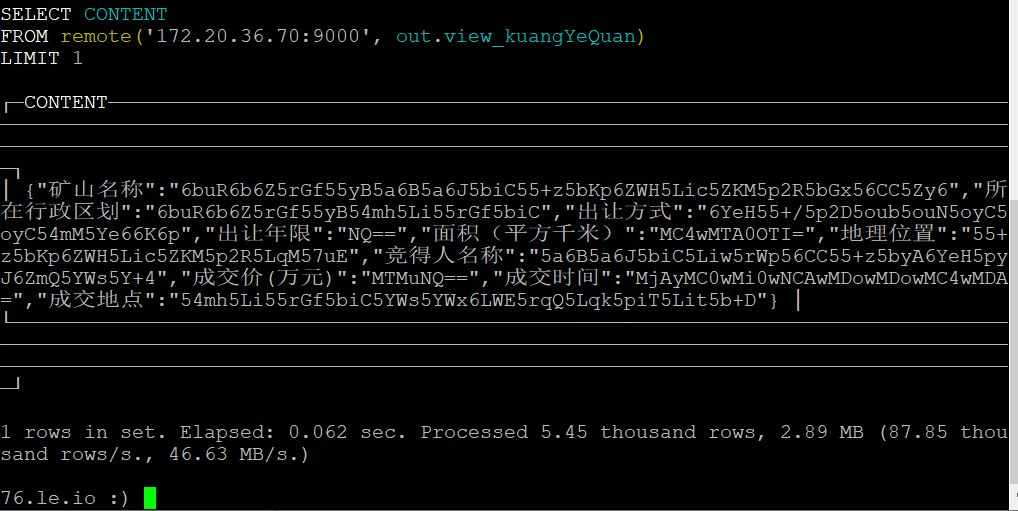
转换后的字段格式如下图:
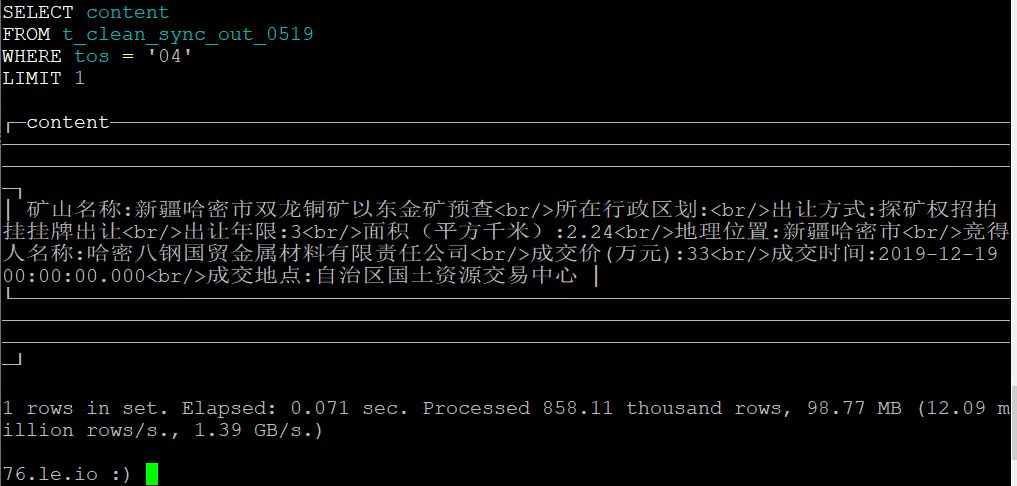
基于正则表达式从WEB页面数据中提取中标人
(1)用于测试的数据表,有两个字段,一个ID,一个CONTENT字段,CONTENT字段为从互联网抓取的公共资源中标成交公告内容。
(2)从CONTENT字段中提取中标人,仅考虑正文中出现“中标人:XXX”一种情况;
(3)对提取出来的中标人与法人库进行名称合规性验证,用于验证的法人库数据为69071251条,测试数据236243条。
基于正则表达式从WEB页面数据中提取中标人测试
(1)SQL方案
分为三步走:第一步,用正则表达式将疑似中标人名称的文本提取出来生成一个临时表;第二步用临时表与法人库表进行关联,取能关联上的,即正确的名称生成第二个临时表;第三步,通过第二个时临时表与原表的关联,合并提取出来正确的中标人信息,写入目标表。实现代码如下图所示:
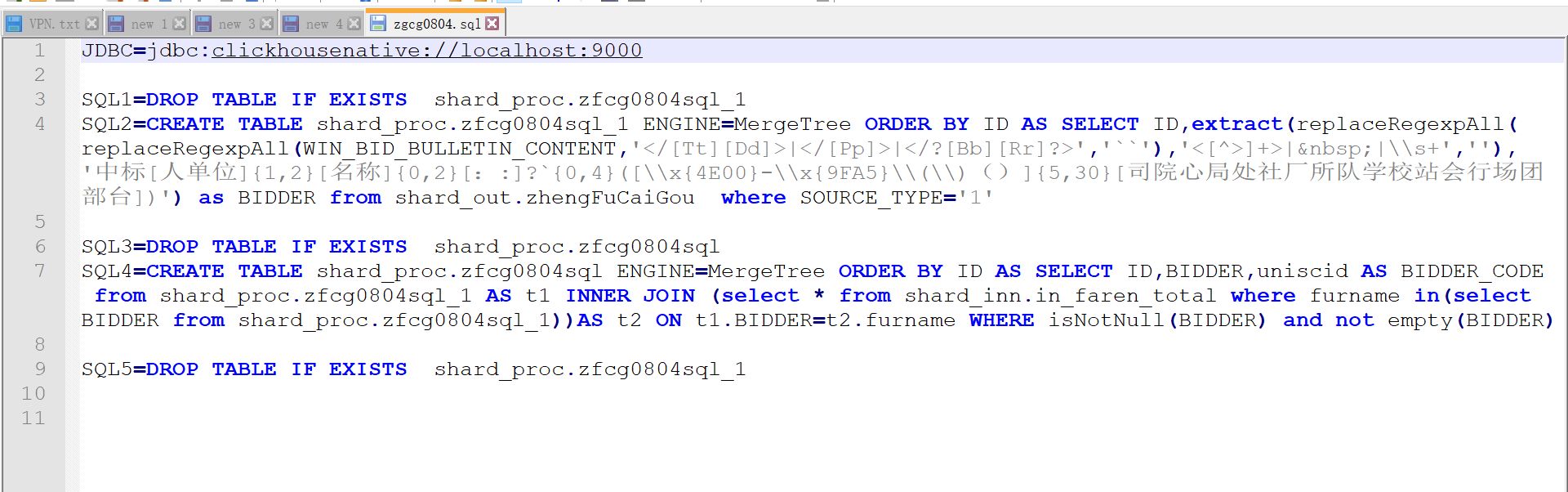
(2)JAVA编程方案
此问题中,ETL实现复杂度过度,所以选择JAVA编程方案。
JAVA程序设计逻辑:连接数据库批量取出数据,然后逐条用正则表达式提取中标人信息并用提取出来的中标人信息查询法人库进行正确性测试,对测试通过的数据写入目标数据表。
实现代码如下图所示:

基于正则表达式从WEB页面数据中提取中标人测试结果
(1)SQL批处理
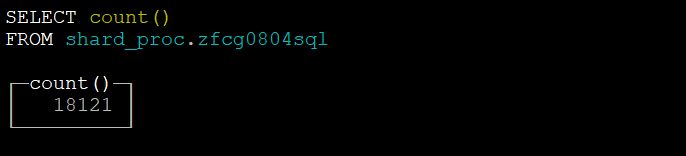
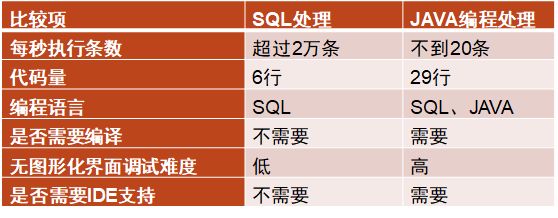
此方案运行时间为9.8秒,共提取出18121个中标人,共计算了236243条数据,满足该格式的正文提取完全,平均每秒处理数据超过2万条。
运行结果如下图所示:
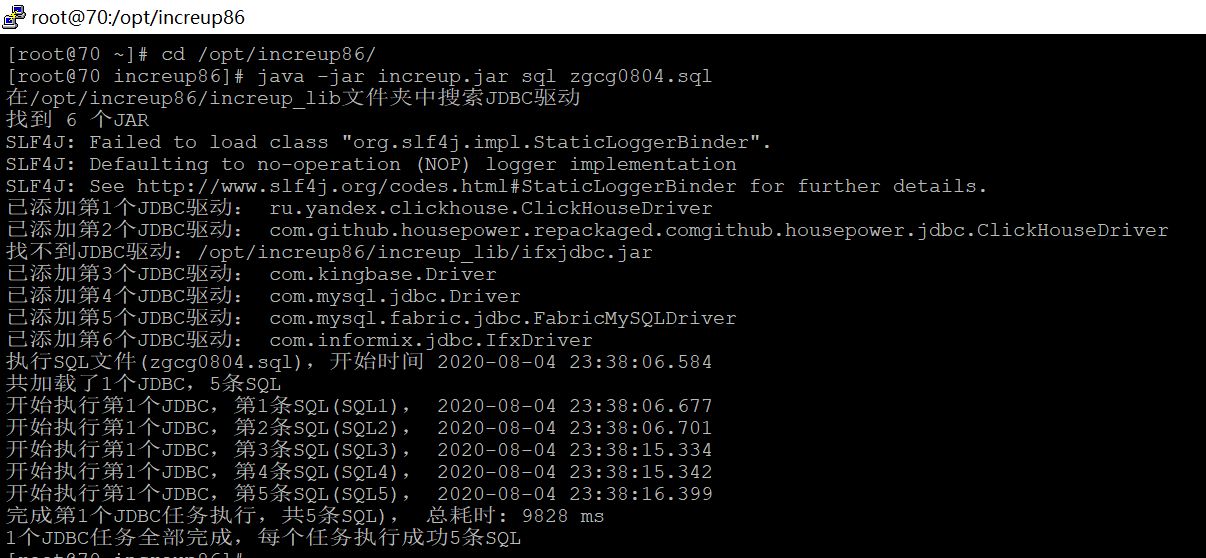
提取出招标人数量如下图所示:
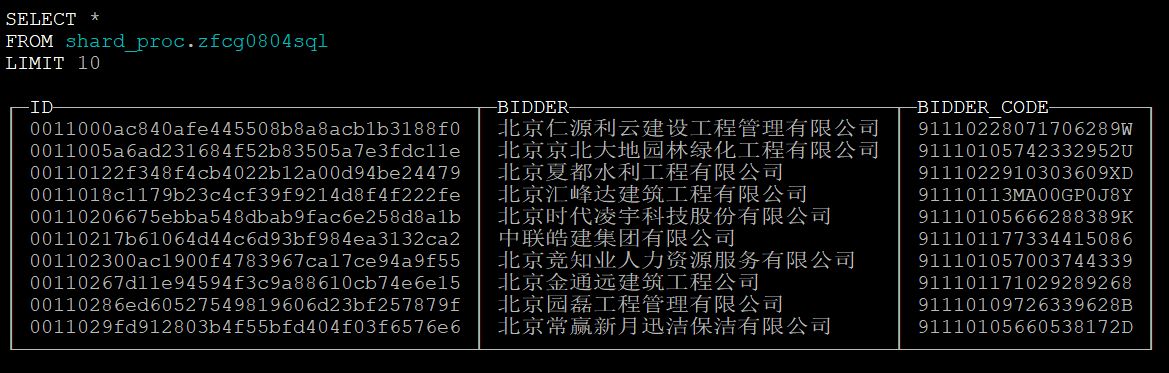
处理后数据表如下图所示:
(2)JAVA编程
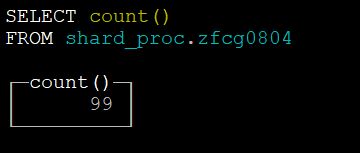
此方案52.8秒共执行了1000条数据,提取出99个招标人,平均每秒处理数据不到20条。
运行情况如下图所示:

提取出招标人数量如下图所示:
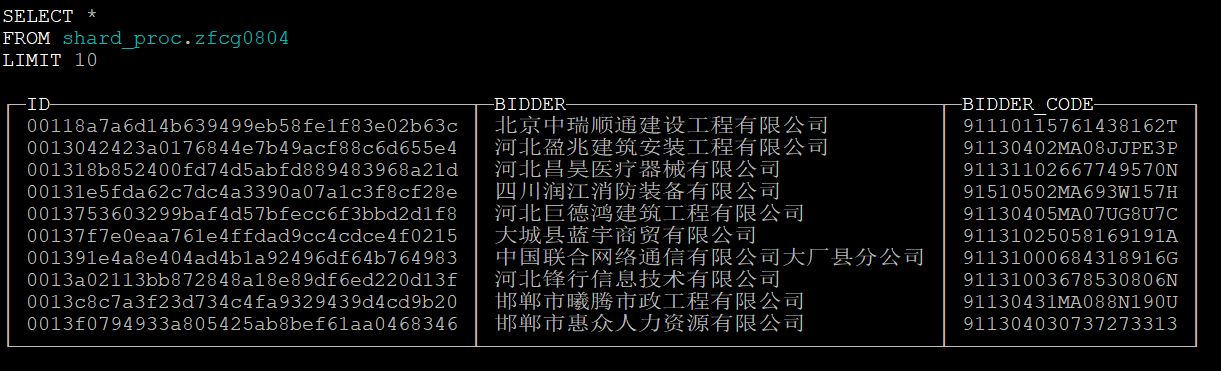
处理后数据表如下图所示:
(3)测评结果对比















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









