






一、awk结构
awk -F '分割符' 'BEGIN{可选} /执行条件/{主体} END{可选}' filepath
注:多个文件时,读取从左到右,读完第一个再读取第二个
执行条件(pattern)可以是如下:
1:/正则表达式/:使用通配符的扩展集;
2:关系表达式: 可以是字符串或数字的比较,如$2>$1选择第二个字段比第一个字段长的行;
3:模式匹配表达式:~ 匹配; ~!不配置。
1、程序结构
BEGIN 块(初始化变量、关键字、可选)
BEGIN {awk-commands}
在BEGIN块被在程序启动时执行,且只执行一次。这是一个很好的初始化变量的地方。 BEGIN是AWK关键字,因此它必须是大写,可选的。
Body块
/pattern/ {awk-commands}
主体块适用于AWK的每个输入行命令。默认情况下AWK执行每一行命令,但可以通过提供的模式限制。请注意,没有主体块的关键字,必选。
END 块
END {awk-commands}
END块被在程序结束时执行,END是AWK关键字,因此它必须是大写。请注意,此块也是可选的。
示例
让创建一个包含序列号的学生,名字,科目并标记成绩,文件的名称为:marks.txt。
1) Amit Physics 80
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
现在用AWK脚本显示包含头文件的内容。
awk 'BEGIN{printf "Xuhao \tName\tKemu\tMarks\n"} {print}' marks.txt
当执行上面的代码时,会产生以下结果
Xuhao Name Kemu Marks
1) Amit Physics 80
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
在程序启动时AWK从BEGIN块,打印头部文字。然后,在主体块时,它从一个文件读取一行,并执行打印标准输出流的内容,使用AWK的printf命令。这个过程不断重复,直到文件被耗尽。
2、流程读取
AWK从输入流(文件,管道,或标准输入)读取一行,并将其存储在存储器(内存)中。
执行
所有的AWK命令依次提交输入。默认情况下AWK执行命令每一行,但我们可以通过提供的模式限制。
重复
重复这个过程,直到该文件被处理完成。
二、使用事例
awk -F '|' '$2>3 {print $1}' data.cvs //打印指定字段 {print $1} 序号1开始
指定分隔符 -F '|' (可多个分隔符)
awk -F '|' '$2>3 {print $1}'
awk -F 'ms' '{print $1}' //可使用字符串分割(不可多个字符串)
awk -F"[@ /t]" '{print $2,$3}' test //以@,空格,Tab键分割test文件的每一行,并输出第二、第三列。(不可多字符串)
//只展示匹配的行
$ awk '$4 ~/Technology/' //只第4个字段匹配的行 (不匹配 ~!)
$ awk '$1 ~/^root/' test //将显示test文件第一列中以root开头的行。
//调用外部shell
ls -l |awk '$1~/^d/{system("du -s "$9)}' //筛选出当前目录下的左右文件夹并显示大小。
//过滤出两个文件中相同行
awk -F'[/,]' 'NR==FNR{a[$1]=$1}NR>FNR{if ($2 in a) print $0}' b a >c //推荐,先将记录放在数组中!
//求平均值/求和
awk '{sum+=$1} END {print "Average = ", sum/NR}'
//删除特定文件外的所有其它文件
rm -rf `ls -lrt|awk '{if(match($0,".bes.cm.")) print $9}' |awk '{if( !(match($0,"bes.cm.base.meta.object-") || match($0,"bes.cm.base.meta.sdk-") || match($0,".bes.cm.base.sdk-") )) print $0}'`
* / % || && > >= == !=
三、awk内置函数(split/substr/length)和 复合表达式
1、split 初始化和类型强制
awk的内建函数split允许你把一个字符串分隔为单词并存储在数组中。你可以自己定义域分隔符或者使用现在FS(域分隔符)的值。
格式:
split (string, array, field separator)
split (string, array) -->如果第三个参数没有提供,awk就默认使用当前FS值。
例子
#t="12:34:56"
#echo $t | awk '{split($0,a,":");print a[1],a[2],a[3]}'
12 34 56
统计一月份工资
cat saryly.txt
vivi 2013-01-18 400
Tom 2013-01-20 300
zjz 2013-01-28 500
zjz 2013-01-29 500
zjz 2013-02-28 500
John 2013-01-28 300
John 2013-01-29 500
John 2013-02-28 500
John 2013-01-30 100
awk '{split($2,a,"-");if(a[2]==01){b[$1]+=$3}} END{for(i in b)print i,b[i]}' saryly.txt | sort -nrk2 |column -t
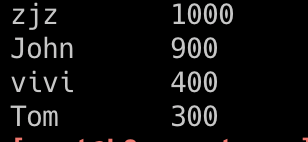
统计人名出现的次数
cat saryly.txt
vivi 400
Tom 300
zjz 500
zjz 500
zjz 500
John 300
John 500
John 500
John 100
cat saryly.txt | awk '{name[$1]++} END{for(i in name) print i,name[i]}' | column -t |sort -rnk2
John 4
zjz 3
vivi 1
Tom 1
#echo $t
12:34:56
#echo $t | awk '{split($0,a,":" ); for (i=1; i<=3; i++) print a[i]}'
12
34
56
2、substr 截取字符串
格式:
substr(s,p) 返回字符串s中从p开始的后缀部分
substr(s,p,n) 返回字符串s中从p开始长度为n的后缀部分

#echo "1 2 3 张小明 zaijian" | awk '{print substr($5,3,3)}'
iji
#echo "1 2 3 张小明 zaijian" | awk '{print substr($5,3)}'
ijian
3、length 字符串长度
length函数返回没有参数的字符串的长度。length函数返回整个记录中的字符数。
#echo "123zjz多少遍" | awk '{print length}'
9
如何使用 awk 复合表达式
https://blog.csdn.net/Listen2You/article/details/73864630
cat netstat.txt | awk /LISTEN/
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN
tcp 1 1 0.0.0.0:80 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN
tcp 0 0 :::22 :::* LISTEN
awk使用&&复合表达式
awk '$1 =="tcp" && $2 > 0' netstat.txt
tcp 1 1 0.0.0.0:80 0.0.0.0:* LISTEN
# awk 'NR==1 || $1 =="tcp" && $2 > 0' netstat.txt
oecv-Q Send-Q Local-Address Foreign-Address State
tcp 1 1 0.0.0.0:80 0.0.0.0:* LISTEN
awk实现用户活跃时间段统计
zcat com.log20160529.gz | grep ‘dianping_reply’ | awk '{split($4,array,"[");if(array[2]>="29/May/2016:00:00:26" && array[2]<="29/May/2016:00:01:14"){print $0}}’
shell命令处理两个文件中的相同部分
行中部分列对应相同。file1.txt的第二列与file2.txt的第一列对应相等。表格的第三列为待输出内容
如果使用grep遇到了内存耗尽的问题,可尝试这个方法:
awk 'NR==FNR{a[$1]}NR>FNR && ($1 in a){print $1}' a.txt b.txt > match.txt
!!注意:如果a文件太大也可能存在内存耗尽的问题,这个时候尝试把文件a,b的位置互换。
awk 'NR==FNR{a[$1]}NR>FNR && ($1 in a){print $1}' b.txt a.txt > match.txt
https://blog.csdn.net/hzhj2007/article/details/106713238/
| 字段 | 意义 |
| NR | 已经读出的记录数,就是行号,从1开始 |
| FNR | 各文件分别计数的行号 |
| NR==FNR | 表示读第一个文件时的条件分支。 因为行数相等 |
| NR>FNR | 表示读第二个文件时的条件分支 |
| a | 存储数据的字典型变量,所以字段值应该保持唯一,否则会被覆盖; |
| $0 | 当前行的所有内容 |
| $1 | 当前行的第一列 |
| a[$1]=$0 | 以第一列作为key值,存储当前行的内容$0 |
| next | 忽略之后的语句,进行下一行的匹配 |
范围查找磁盘空间
$ df -h |awk -F '[ %]+' '{if(NR!=1 && $5 >= 65) print}'
/dev/sda3 47G 32G 16G 67% /
10.1.1.2:/mnt/data/nfs/public 66T 65T 1.3T 99% /mnt/nfs
打印时间范围的日志
awk '/^# Time: 130912/ {slow=($NF>"10:09:00" && $NF<"10:11:00")}slow' slow.log
awk 'BEGIN{RS="# Time: 130912"}$1>"10:09:00"&&$1<"10:11:00"{print RS,$0}'
用awk数组去除重复域 awk ‘!a[$1]++’
指定某一列,当再次出现相同数值时,舍弃。
# cat test.txt
1 2 3
1 2 2
2 2 2
3 4 4
3 4 5
2 2 2
4 4 4
5 5 5
6 6 6
7 7 7
8 8 8
1 4 3
# awk '!a[$1]++' test.txt
1 2 3
2 2 2
3 4 4
4 4 4
5 5 5
6 6 6
7 7 7
8 8 8
# awk '!a[$2]++' test.txt
1 2 3
3 4 4
5 5 5
6 6 6
7 7 7
8 8 8
https://www.yiibai.com/awk 易百awk教程
















 299
299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











