










 本文聚焦JDK17,对比JDK8等旧版本,介绍了JDK17在文本块、空指针提示、record语法糖等方面的特性优化。同时,详细阐述了G1、Shenandoah、ZGC三种垃圾回收器的特点、优化内容和运行过程。此外,还提及了JDK17版本升级时的相关问题。
本文聚焦JDK17,对比JDK8等旧版本,介绍了JDK17在文本块、空指针提示、record语法糖等方面的特性优化。同时,详细阐述了G1、Shenandoah、ZGC三种垃圾回收器的特点、优化内容和运行过程。此外,还提及了JDK17版本升级时的相关问题。
JDK几个统计数据
JDK8在2020年使用占比84%, 2023年使用占比32%
JDK17在2022年使用占比0.37%, 2023年使用占比9.07%
JDK11+ 使用G1占比65%
从JDK8到JDK11, G1平均速度提升16%, 从JDK11到JDK17平均速度提升8.66%
JDK17相对于JDK8和JDK11, 所有垃圾回收器的性能都有很明显的提升
综合类
- 从JDK14开始删除CMS垃圾收集器
- 从JDK15开始禁用偏向锁
- 从JDK14开始, 启用ParallelScavenge和SerialOld GC的组合使用
文本块
public static void main(String[] args) {
/**
* 文本块
*/
String s = "hello" +
" - " +
"world";
System.out.println(s);
String s1 = """
hello
-
wold
""";
System.out.println(s1);
}
比如在java8中, 如果要拼接是很长的字符串或者html格式的文本, 一般情况下, 为了方便阅读都要换行处理, 但是换行后, 每个字符串都要使用"+“拼接.
在jdk17中, 只需要”“” xx “”" 3个引号引起来, 就可以直接换行了, 简单方便了许多.
空指针提示优化
public static void main(String[] args) {
/**
* 空指针提示优化
*/
testNpe();
}
private static void testNpe() {
Object a = null;
var flag = a.equals("1");
System.out.println(flag);
}
同样的一个的NPE异常, 打印出不同的错误栈信息.
这是java8的错误提示信息

这是java17的错误提示信息

从了jdk17, 再也不用为找不到哪个空而发愁了.
record语法糖
1. jdk8
先来看下jdk8的pojo的使用方式
定义pojo对象
public class User {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
'}';
}
}
定义好成员变量, 同时添加好对应的getter和setter方法, 以及可能需要的toString, equals等方法.
也有的直接使用lombok的@Getter, @Setter或者@Data等注解实现.
使用最原始的方式, 不依赖三方的插件, 只会让我们的代码上看着比较臃肿, 并且都是模板代码.
如果要使用lombok的话, 就必须要依赖三方插件, 关键是你一个人用, 无所谓了, 但是如果是在企业开发, 那就需要所有的小朋友都要安装和使用lombok插件了.
2. jdk17
我们在来看下jdk17如何优化这种问题的(不代表它是最优解, 也有一定的缺陷)
public record User2(String name){
static final int a = 1;
}
public static void main(String[] args) {
/**
* pojo
*/
User user = new User();
user.setName("1");
System.out.println(user.toString());
}
从user2的这个定义上来看, 是不是超级简介
- 把class标识换成record标识
- 类的成员变量直接放在了类似于定义方法的入参上
- 类中不在定义成员变量
- 类中可以定义静态变量
- 默认提供了全参数的构造方法
我们从它的字节码上看下它到底是什么逻辑
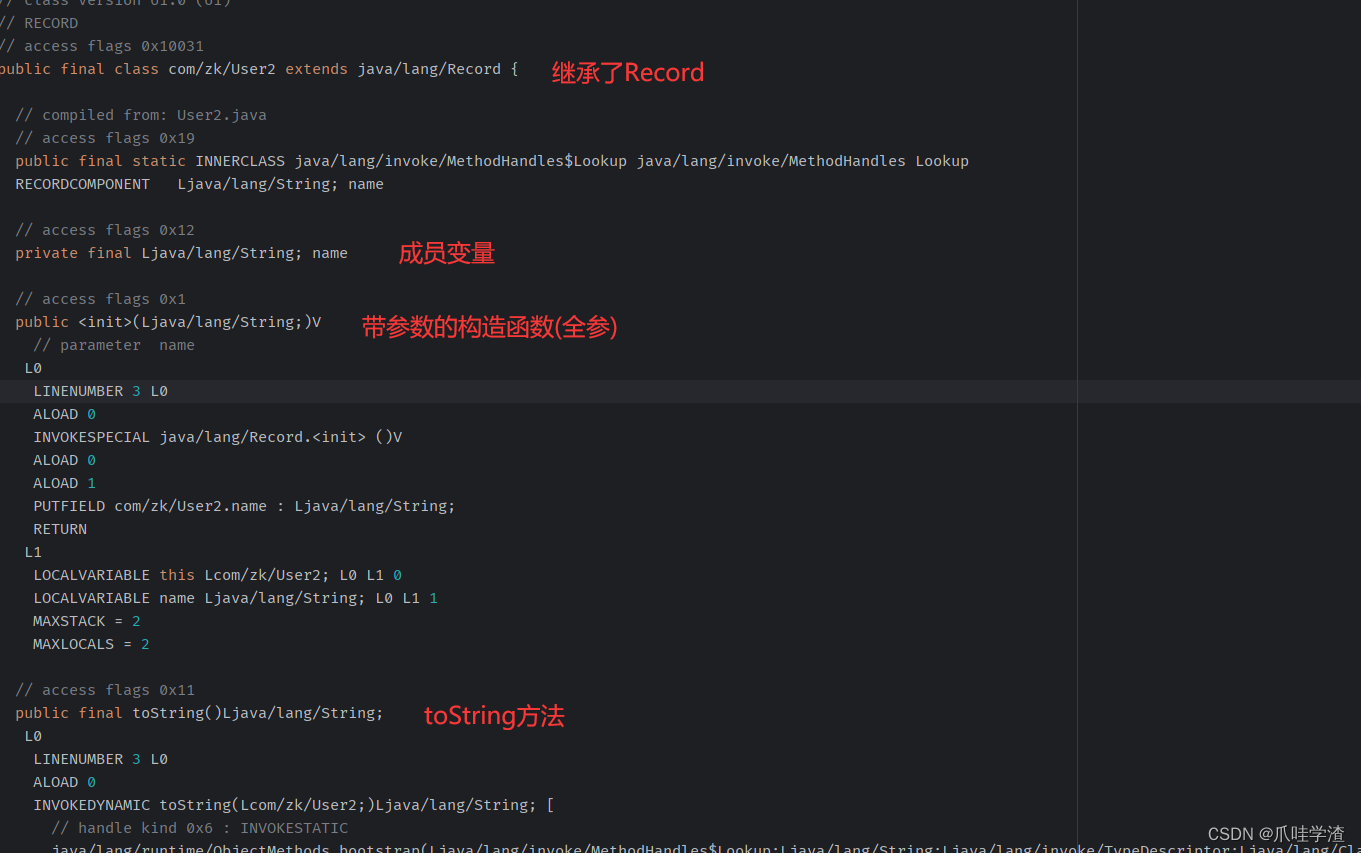
从上图的字节码中我们可以看到:
- 它是final类, 无法被继承
- 它继承了Record抽象类(一个抽象类, 提供了equals, hashCode, toString等抽象放啊), 也就是说record标识的类, 无法再继承其他类
- 提供了全参的构造方法, new对象的时候必须带有全参
- 不可以在类中自定义其他变量, 除非定义在类入参上
- 也没有setter方法, 并且官方也不推荐
从这些点我们也可以看到一个优势, 同时也有一些劣势, 它的场景也很明显, 大家自行斟酌了.
- 如何判断一个类是不是Record的实现呢
//老的方法
boolean assignableFrom = Record.class.isAssignableFrom(User2.class);
System.out.println(assignableFrom);
//新的方法
boolean record = User2.class.isRecord();
System.out.println(record);
switch优化
public enum SwitchTest {
ONE,
TWO,
THREE;
}
1. jdk8写法
private static void switchTest(SwitchTest switchTest) {
switch (switchTest) {
case ONE:
System.out.println(1);
break;
case TWO:
System.out.println(2);
break;
default:
System.out.println("default");
}
}
想必大家对这个已经很熟悉了, 这里面我们要写很多的break或者直接return的定义.
2. jdk17写法
private static void switchTest2(SwitchTest switchTest) {
switch (switchTest) {
case ONE -> System.out.println(1);
case TWO, THREE -> System.out.println("2 & 3");
default -> System.out.println("default");
}
}
是不是看着简洁了一下, 这个和其他语言有相似之处, 比如scala, python.
每个case后面以;结尾.
模式匹配instanceof优化
1. jdk8的写法
private static void instanceof1(Object a) {
if (a instanceof String) {
String lowerCase = ((String) a).toLowerCase();
System.out.println(lowerCase);
}
}
就算a是String对象, 在使用的时候我们也必须要先强转为String对象, 才可以后续的使用
2. jdk17
private static void instanceof1(Object a) {
if (a instanceof Integer v) {
double b = v.doubleValue();
}
}
在使用instanceof的时候, 直接定义了变量v, 那么v在后面的运算中, 就可以直接使用了, 不用再强转为Integer类型的变量了.
私有方法
在jdk8中我们已经熟练使用了接口中的default的使用了, 对于方法, 接口中也就只能定义default和普通的定义方法了, 但是如果我们使用了default, 需要很多的适配或者逻辑处理, 就只能再接口实现类中去实现, 如果是所有实现的功能逻辑, 可能我们还需要抽取一层service, 不是很方便, 但是在jdk17中就给我们提供了可以编写private方法的功能了, 可以便于我们在使用default方法的同时做一些公共的逻辑处理.
public interface UserService {
default String getName() {
return adapterName(1);
}
private String adapterName(int a) {
String name;
switch (a) {
case 1 -> name = "1";
case 2 -> name = "2";
default -> name = "3";
}
return name;
}
}
getName使我们定义的default方法, 如果这个方法对于所有实现类来说是公共的逻辑, 那么我们直接在接口中完成它即可, 不用再放置在抽象类或者每个实现类中了, 是不是很方便?
类型变量推断
在Java8的时候,其实就已经支持了类型推断了.
在Java10的时候又引入了另外一个特性,叫局部变量类型推断这个特性。正如这个特性的名称,这个特性只能用于局部变量,且类型是确定的,无二义性的,下面的示例代码中给出了哪些地方不能用局部变量类型推断,也就是var关键词在哪些场景下不允许使用。
public class VarTest {
var name; //成员变量不可使用var
private int age;
public VarTest(var age) { //构造方法或者普通方法的入参不可使用var
this.age = age;
}
public var getAge() { //方法返回值不可使用var
return this.age;
}
public void setAge(var age) {
this.age = age;
}
public void test(int a) {
var b = a + 1; //方法内的变量是可使用var类型推断的
System.out.println(b);
}
public void tryc() { // catch中的参数变量不可使用var
try {
int i = 1 / 0;
} catch (var e) {
}
}
}
从上面列举的示例中我们可以看到, 只有方法内的局部变量才可以使用var类型推断, 并且是类型唯一的才可以.
HttpClient优化
终于它还是优化了,原来的JDK自带的Http客户端真的非常难用,这也就给了很多像okhttp、restTemplate等第三方库极大的发挥空间,几乎就没有人愿意去用原生的http客户端的。但现在不一样了,感觉像是新时代的API了。FluentAPI风格,处处充满了现代风格,用起来也非常地方便,再也不用去依赖第三方的包了,方便了很多, 这样我就不用再依赖三方api, 就可以实现远程调用了.
1. jdk8
HttpClient httpClient = HttpClient.New(new URL("https://www.baidu.com"));
httpClient.setConnectTimeout(1000);
MessageHeader messageHeader = new MessageHeader();
messageHeader.add("keep-alive", "true");
httpClient.writeRequests(messageHeader, null);
OutputStream outputStream = httpClient.getOutputStream();
byte[] b = new byte[1024];
outputStream.write(b);
System.out.println(new String(b));
估计大部分人看这个代码都不熟悉了, 好多人也没用过, 反正我是没用过.
2. jdk17
Map<String, Object> params = new HashMap<>();
params.put("event_type", "custom-reader");
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://edith.xiaohongshu.com/api/sns/web/activity/report_event"))
.timeout(Duration.ofMinutes(1))
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(JSON.toJSONString(params), StandardCharsets.UTF_8))
.build();
HttpClient client = HttpClient.newBuilder()
.version(HttpClient.Version.HTTP_1_1)
.connectTimeout(Duration.ofSeconds(100))
.build();
try {
//这个是同步方法
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
//异步调用请使用client.sendAsync()
String body = response.body();
System.out.println(body);
} catch (Exception e) {
throw new RuntimeException(e);
}
看着是不是特别像restTemplate格式的api, FluentAPI风格看着就是很舒服.
定义request的时候, 可以直接设置url, timeout, header, 请求方式, 以及body参数等等.
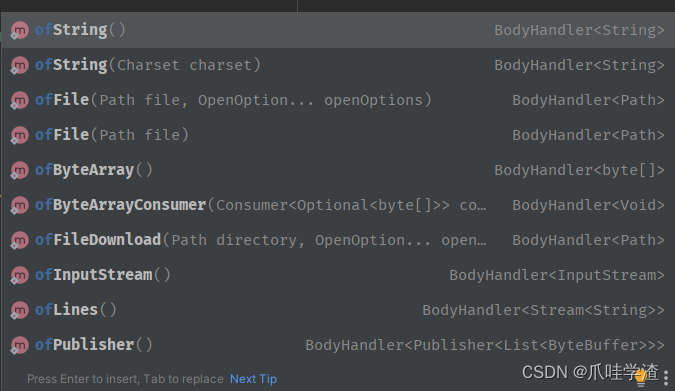
3. HttpResponse.BodyHandlers
这里我们延伸一下, 当请求发出后, 一般情况下我们都要获取请求返回的结果, 在我们正常项目开发中, 为了方便操作数据, 我们一般都要转成javabean以供后续使用.
@FunctionalInterface
public interface BodyHandler<T> {
public BodySubscriber<T> apply(ResponseInfo responseInfo);
}
BodyHandler是一个泛型的函数式接口, 下图中返回的所有的内置的ofxx方法, 返回的都是BodyHandler函数.
public static BodySubscriber<String> ofString(Charset charset) {
Objects.requireNonNull(charset);
return new ResponseSubscribers.ByteArraySubscriber<>(
bytes -> new String(bytes, charset)
);
}
这是一个ofString的实现, 看这个是把返回的结果转换成了string对象.
4. 问题来了, 如果我想要直接转成javabean该如何实现呢?
public class MyBodyHandler<R> implements HttpResponse.BodyHandler<R>{
private final Class<R> responseType;
public MyBodyHandler(Class<R> responseType) {
this.responseType = responseType;
}
@Override
public HttpResponse.BodySubscriber<R> apply(HttpResponse.ResponseInfo responseInfo) {
return HttpResponse.BodySubscribers.mapping(
HttpResponse.BodySubscribers.ofString(StandardCharsets.UTF_8),
json -> JSON.parseObject(json, responseType));
}
}
我们只需要实现HttpResponse.BodyHandler, 在apply里面实现结果集到javabean的转化即可.
MyBodyHandler myBodyHandler = new MyBodyHandler(Result.class);
HttpResponse<Result> response = client.send(request, myBodyHandler);
Result body = response.body();
当定义好自定义的BodyHandler后, 在调用的时候, 只需要把我们自定义的实例对象作为入参传到send方法中即可, 这样response.body()返回的直接就是我们定义好的javabean对象.
5. 并发访问
在正常的业务处理中, 考虑到性能问题, 可能要并发访问多个地址, 请看demo
HttpClient client = HttpClient.newHttpClient();
List<HttpRequest> requests = IntStream.range(1, 5)
.mapToObj(url -> {
Map<String, Object> params = new HashMap<>();
params.put("event_type", "custom-reader");
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://edith.xiaohongshu.com/api/sns/web/activity/report_event"))
.timeout(Duration.ofMinutes(1))
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(JSON.toJSONString(params), StandardCharsets.UTF_8))
.build();
return request;
})
.toList();
List<CompletableFuture<HttpResponse<String>>> futures = requests.stream()
.map(request -> client.sendAsync(request, HttpResponse.BodyHandlers.ofString()))
.toList();
futures.forEach(e -> e.whenComplete((resp, err) -> {
if (null == err) {
System.out.println(resp.body());
}
}));
CompletableFuture.allOf(futures.toArray(CompletableFuture<?>[]::new)).join();
总之, jdk17新提供的HttpClient, 已经满足了我们的需求了, 还是很好用的.
集合的优化
集合肯定就包含map, list, set
Set<Integer> integers = Set.of(1, 2, 3);
List<Integer> integers1 = List.of(1, 2, 3, 4);
Map<String, Integer> stringIntegerMap = Map.of("1", 2, "3", 4);
这个就是jdk17的实现方式, 如果使用过guava的朋友, 看起来肯定很熟悉, 是的, 你没看错, 它确实是差不多的, 类似于guava的Sets.newHashSet()等等
Set<Integer> set = new HashSet<>();
set.add(1);
set.add(1);
在jdk8中, 我们想要添加值, 只能先创建set对象后, 然后调用add方法才可以使用.
string新的api
String a = "";
System.out.println(a.isEmpty());//true
System.out.println(a.isBlank());//true
String b = " ";
System.out.println(b.isEmpty());//false
System.out.println(b.isBlank());//true
String c = "c";
System.out.println(c.repeat(3));//ccc
String d = " asdfals sdfjasdjlfwejdsf dfs ";
System.out.println(d.stripLeading());//"asdfals sdfjasdjlfwejdsf dfs "
System.out.println(d.stripTrailing());//" asdfals sdfjasdjlfwejdsf dfs"
System.out.println(d.strip());//asdfals sdfjasdjlfwejdsf dfs
String e = "a\nb\nc\nd\n";
Stream<String> lines = e.lines();
long count = lines.count();
System.out.println(count);//4
String f = "abc";
String indent = f.indent(3);
System.out.println(indent);//" abc"
- 提供了isBlank方法, 判断是否有空格, 之前大家应该使用呢的都是三方的一些, 比如apache
- 新加了repeat方法, 生成重复个数的字符串
- 提供了3个去除字符串空格的方法, 前空格, 尾空格, 所有空格
- 提供了lines, 如果字符串中有终止换行符, 通过lines方法直接转成stream流式, 方便后续做流式处理
- 提供了indent的缩进方法
streamApi
IntStream intStream = IntStream.range(1, 10)
.takeWhile(i -> i % 2 == 1);
List<Integer> list = intStream.boxed().toList();
//结果是[1]
IntStream intStream2 = IntStream.range(1, 10)
.dropWhile(i -> i % 2 == 1);
List<Integer> list2 = intStream2.boxed().toList();
//结果是[2,3,4,5,6,7,8,9]
/**
* return t == null ? Stream.empty()
*/
Stream<Object> nullStream = Stream.ofNullable(null);
long count = nullStream.count();
//结果是0
- takeWhile和dropWhile都是过滤的一种方式, 和jdk8现有的流的filter类似
- takeWhile是当遇到第一个满足条件的时候停止
- dropWhile是删除掉满足条件的元素, 直到第一个不满足条件的停止
- ofNullable是对空流处理, 当调用Stream.ofNullable时, 如果是空流, 就会返回Stream.empty(), 防止NPE
提供了很多新的api, 以满足各种场景下的使用.
同时大家也看到了toList()方法, 不再使用collect(Collectors.toList())了.
Files(api)
String readString = Files.readString(Path.of(Test17.class.getClassLoader().getResource("test.txt").toURI()));
Path path = Path.of(File.createTempFile("temp", ".txt").toURI());
Files.writeString(path, "hello world", Charset.defaultCharset(), StandardOpenOption.WRITE);
Path path1 = Path.of(Test17.class.getClassLoader().getResource("test.txt").toURI());
Path path2 = Path.of(Test17.class.getClassLoader().getResource("test2.txt").toURI());
- 第一个是从指定路径读取文件内容, 以string输出
- 第二个是把string内容写入到指定路径
- 第三个是比对2个文本内容是否完全一致, 如果完全一致返回的是-1.
提供的新的api主要是为了开发者更方便的读写文件内容.
在jdk8中也有类似的方法, 比如Files.readlines(), Files.readAllLines()
还有apache的, FileUtils.readFromFile()等等.
密封类
JDK 17推出密封类的原因主要是为了增加对类继承关系的限制,以提供更好的封装性和安全性。
密封类的作用主要有以下几点:
限制类的继承:通过使用密封类,可以确保该类不能被其他类继承,从而提供更好的封装性和安全性。这对于那些不希望外部扩展功能的组件来说非常有用。
防止恶意代码的攻击:由于密封类的继承被限制,因此可以防止恶意代码通过继承来获取或修改类的内部实现,从而增加了代码的安全性。
public sealed class Shape permits Circle, Hexagon{
}
定义了一个Shape的基础类, 加了密封类的标识符sealed.
permits定义可以继承Shape的子类, 有Circle, Hexagon
这个类也可以是抽象类
public non-sealed class Circle extends Shape{
}
public final class Hexagon extends Shape{
}
- 定义了sealed的密封类必须有子类
- 子类可以是final修饰的类, 可以是no-sealed修饰的类(非密封类), 也可以是sealed密封类(必须有子类)
- permits指定的子类必须直接继承该父类
- 接口间的继承也是同样的道理
时段支持(DateTimeFormatter)
DateTimeFormatter提供了对时段的支持, 可以通过api查询指定时间是一天的上午还是下午.
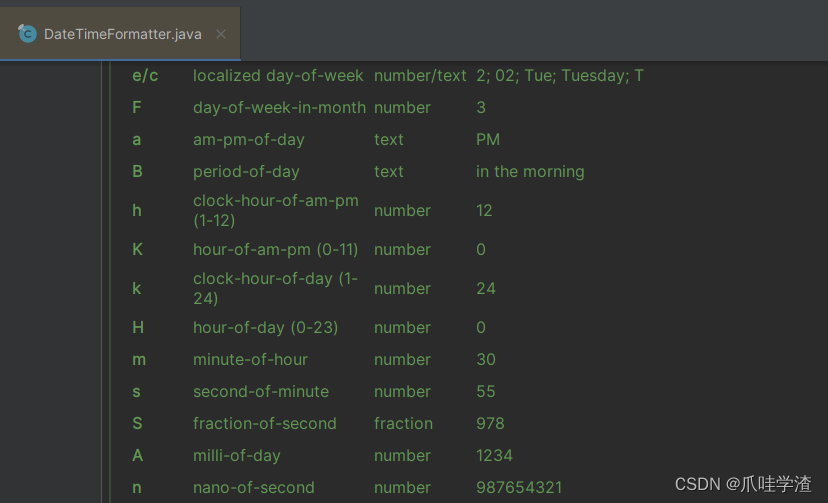
这是DateTimeFormatter一些格式化注释说明.
LocalTime localTime = LocalTime.of(10, 0, 0);
//这里只会返回上午 下午
String date1 = DateTimeFormatter.ofPattern("a").format(localTime);
//会返回上午 中午 下午 晚上
String date2 = DateTimeFormatter.ofPattern("B").format(localTime );
//返回一天的小时
String date3 = DateTimeFormatter.ofPattern("k").format(localTime );
java文件运行
之前运行java文件必须要javac编译一下, 才可以运行, jdk17直接使用java xx.java就可以直接运行了, 省去了单文件编译的麻烦.
模块化
关于模块的官方说明请戳这里
什么是模块?
模块化在包之上提供更高层次的聚合。关键的新语言元素是模块,它是一组专属命名、可重用的相关包、资源(例如图像和 XML 文件)和一个模块描述符,用于指定:
- 模块名称
- 模块的依赖项(即此模块依赖的其他模块)
- 明确可以让其他模块使用的包(其他模块隐式不可用模块中的所有其他包)
- 它提供的服务
- 它使用的服务
- 允许哪些其他模块使用reflection
为什么要有模块系统?
JDK推出的模块系统(Java Platform Module System,JPMS)的作用是将Java平台分解为互相依赖的模块,并提供了一种更加灵活和可控的方式来管理和组织代码。这个模块系统是为了解决Java平台长期以来存在的一些问题,包括:
- 依赖管理:模块系统可以帮助开发人员更好地管理代码之间的依赖关系,提供了更加清晰和可控的方式来定义和管理模块之间的依赖关系。
- 可重用性:模块系统可以提高代码的可重用性,使得开发人员可以更容易地将代码组织成可重用的模块,并且可以更好地控制模块的可见性和访问权限。
- 安全性:模块系统可以提高代码的安全性,使得开发人员可以更容易地控制模块之间的访问权限,从而减少了一些潜在的安全风险。
看下jdk8的rt.jar
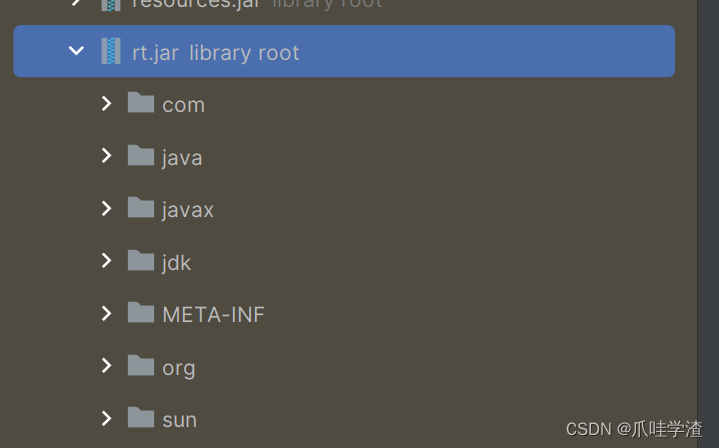
看下jdk17的rt.jar
新的jdk已经对jar进行了模块化区分了.
现在我们就要看下如果要模块化管理, 需要怎么做?
- module-name
建模块也必须遵守下面的规则:
- 模块名称必须是唯一的。
- 模块描述符文件module-info.java 必须有。
- 包名称必须是唯一的。即使在不同的模块中,我们也不能有相同的包名。
- 每个模块将创建一个 jar 文件。对于多个 jar,我们需要创建单独的模块。
- 一个项目可以由多个模块组成。
module m1 {
exports org.example to m3, m2;
exports org.example2 to m2;
opens org.example;
provides org.example.M with org.example.M1;
}
- requires
requires 模块指令指定此模块依赖于另一个模块,此关系称为模块依赖关系。每个模块必须明确地指出其依赖项。当模块 A requires 模块 B 时,模块 A 称为读取模块 B,模块 B 则是给模块 A 读取。如需指定对其他模块的依赖性,请使用 requires指令.
module m3 {
requires m1;
requires m2;
uses org.example.M;
}
这里就表明m3模块需要依赖m1模块
requires static 指令,用于指示在编译时必需要有模块,在运行时则不是必须的。这称为可选相关项
requires transitive — 隐式可读性。指定对其他模块的依赖性并确保其他模块读取您的模块时也能读取这依赖性,所谓的隐式可读性,请使用 requires transitive
这个就有点像是maven依赖的传递性, 比如B依赖了A, C依赖了B, 那么C可以直接使用A的模块的API.
- exports
默认情况下,模块里下所有包都是私有的,即使被外部依赖也无法访问,一个模块之内的包还遵循之前的规则不受模块影响。
exports 及 exports…to。exports 模块指令指定模块的一个包,其 public 类型(及其嵌套的 public 和 protected 类型)应可供所有其他模块的代码访问。通过 exports…to 指令,您可以在逗号分隔的列表中指定哪个模块或模块的代码可以访问导出的包,这就是所谓的限定导出。
module m1 {
exports org.example to m3;
exports org.example2 to m2;
opens org.example;
provides org.example.M with org.example.M1;
}
比如这里的exports, 对于m3模块, 它只能使用org.example包下的api, 不能使用org.example2包下的api.
对于m2模块, 它只能使用org.example2包下的api, 不能使用org.example包下的api.
这两个是定向导出的, 当然我们也可以直接使用:
module m1 {
exports org.example;
}
那么只要是依赖了m1的模块, 都可以使用org.example包下的api.
- uses
uses 模块指令指定此模块所使用的服务,使此模块成为服务使用者。service 是类的对象,用于实施接口或扩展 uses 指令中指定的 abstract 类。
使用 uses 关键字,我们可以指定我们的模块需要或使用某些服务, 这个服务通常是一个接口或抽象类, 而不是一个具体的实现类。
uses只能从模块自己的包中或者requires、requires static以及requires transitive传递过来的接口或者抽象类。
module m3 {
requires m1;
requires m2;
uses org.example.M;
}
比如这里使用了org.example.M, M是m1模块中定义的接口, m3模块依赖了m1和m2, 只要这2个模块中有M的实现类, 那么我们就可以直接使用了.
ServiceLoader<M> load = ServiceLoader.load(M.class);
load.stream().forEach(p -> System.out.println(p.type()));
比如我们通过ServiceLoader加载所有M的实现类, 只要依赖的模块或者间接依赖的模块有提供M的实现, 就是下面的provides指令, 我们都可以加载到.
- provides
provides…with 模块指令指定模块提供服务实施,使模块成为服务提供者。指令的 provides 部分指定模块的 uses 指令指令中列出的接口或 abstract 类;指令的 with 部分指定 implements 接口或 extends abstract类的服务提供类的名称。
module m2 {
requires m1;
exports org.zk;
provides org.example.M with org.zk.M21;
}
对于M接口m2模块提供了它的实现是M21.
- opens
包 的 public 类型(及其嵌套的 public 和 protected 类型)只能在运行时可供其他模块中的代码访问。同样,指定包中的所有类型(以及所有类型的成员)都可通过 reflection 进行访问.
我们来看下jdk8反射的使用方式
User user = new User();
user.setName("1");
Class<? extends User> aClass = user.getClass();
Field name = null;
try {
name = aClass.getDeclaredField("name");
name.setAccessible(true);
Object object = name.get(user);
System.out.println(object);
} catch (Exception e) {
throw new RuntimeException(e);
}
这样直接使用的化, 我们就可以取到name的值.
同样的方式, 如果在jdk17模块系统中, 就会有如下提示:

因为我们定义的User类是在m1模块的org.example包下, 所以这时候就必须要用opens指令开放反射权限.
module m1 {
exports org.example to m3, m2;
exports org.example2 to m2;
opens org.example;
}
添加了opens指令后, 我们就可以正常使用反射api的方式了.
注意:
未命名模块
添加到类路径中的 jar 和类。当我们将 jar 或类添加到类路径时,所有这些类都会添加到未命名的模块中只导出到其他未命名的模块和自动模块。这意味着,应用程序模块无法访问这些类。它可以访问所有模块的类。
G1
G1 (Garbage First) 是一款面向服务器的垃圾收集器,主要针对配置多核处理器以及大容量内存的机器,以极高概率满足GC停顿时间要求的同时,还具备高吞吐量性能特征,JDK 9开始默认使用G1 垃圾收集器.
G1的特点
G1的主要特点可以分为以下四点:
- 并行与并发: G1能充分利用CPU,多核环境下的硬件优势,使用多个CPU来缩短STW时间,部分其他收集器原本需要停顿Java线程来执行GC动作,G1收集器仍然可以通过并发的方式让Java线程继续执行
- 分代收集: 虽然G1可以不需要其他收集器配合就能独立管理整个堆,但还是保留了分代的概念
- 空间整合:和CMS的标记-清除算法不同,G1从整体上看是标记-整理算法,但是从局部上来看是基于标记-复制的算法来实现的
- 可预测的停顿:
这是G1相对于CMS的另一个大优势,降低停顿时间是G1和CMS的共同关注点,但是G1在追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为毫秒的时间片段
通过-XX:MaxGCPauseMillisk来指定内完成垃圾收集
垃圾收集算法方法论是基于分代收集的思想,垃圾收集器又是垃圾收集算法方法论的具体实现,而其他的垃圾收集器也都是这么实现的,把堆划分成年轻代、老年代,但是G1在物理方面却已经脱离了分代的概念,虽然底层逻辑还是借用了分代的思想,既然脱离了分代的概念, 可以参考下图.
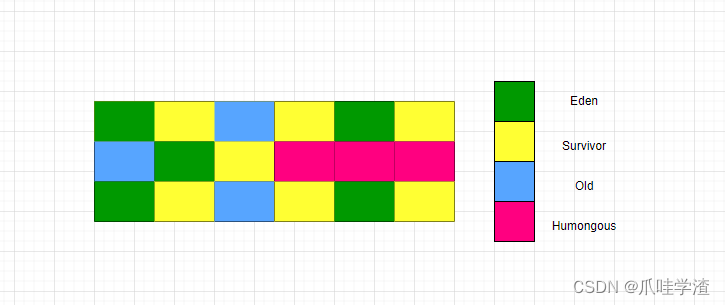
G1将一整块堆划分成多个大小相等的独立区域Region,JVM最多可以有2048个Region默认也是2048个。
一般Region大小等于堆大小除以2048,比如堆大小是4096M,则Region的大小是2M,当然可以通过JVM命令 -XX:G1HeapRegionSize 调整Region大小,但是推荐默认的大小调整。
年轻代对堆内存的占比是5%,如果堆大小是4096M,那么年轻代占据约200MB左右的内存,对应的Region区域个数就是100个。
年轻代中的Eden区和Survivor区对应的region也跟之前一样,默认8:1:1,假设年轻代现在有100个Region,那么Eden区就是80个,survivor0就是10个,survivor1就是10个。
一个Region可能之前是年轻代,如果Region进行了垃圾回收,之后可能又会变成老年代,也就是说Region的区域功能可能会动态变化,所以说在G1的世界里,它只认识Region,但是逻辑上还是有新生代和老年代。
大对象处理方式
G1垃圾收集器对于对象什么时候会移动到老年代和之前讲的套路一样,唯一不同的就是对于大对象的处理,G1有专门分配大对象的Humongous区,而不是让大对象进入老年代的Region,在G1中,如果一个对象超过了Region区的50%大小,那么就被判定成大对象,比如上面说的,如果Region区是2M的大小,如果一个对象超过了1M,那么就放入Region区,而且一个大对象如果太大,那么会横跨多个Region来存放。
Humongous区专门用来存放大对象,不用直接进入老年代,可以节约老年代的空间,Full GC的时候除了收集年轻代和老年代之外,也会将Humongous区一并回收。
下图是G1运行示意图:
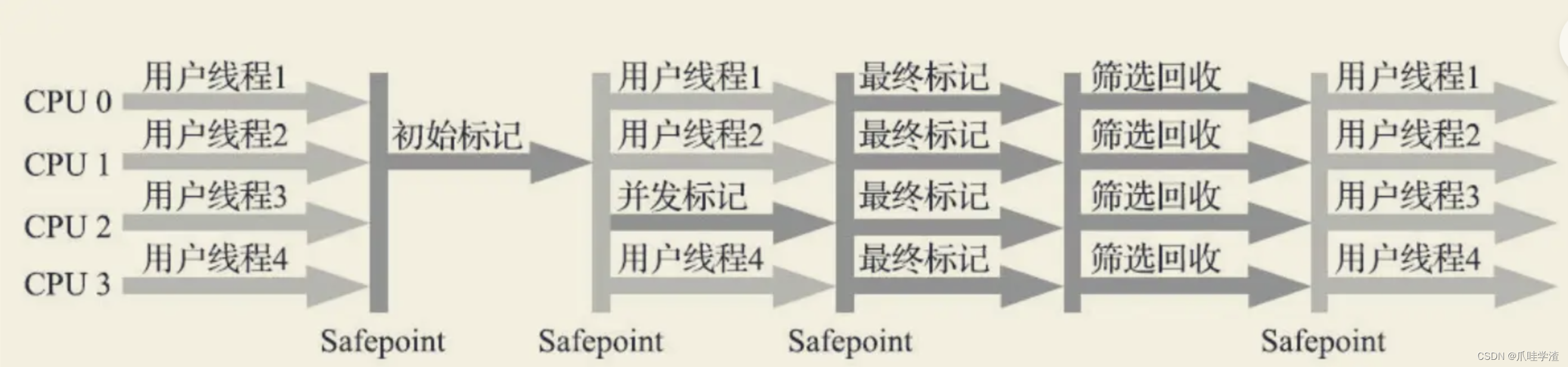
- 初始标记: 暂停其他的所有线程STW,并记录下GC Roots直接引用的对象,这步和CMS一样,速度很快
- 并发标记: 同CMS的并发标记
- 最终标记: 同CMS的重新标记,也会STW
- 筛选回收: 筛选回收阶段首先对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿STW时间来制定回收计划,可以用-XX:MaxGCPauseMillis来指定时间,比如说老年代有1000个Region都满了,但是因为预期停顿时间只有200ms默认是200ms,那么通过对各个Region的回收价值和成本计算可知,可能回收其中的800个需要200ms,那么就只会回收其中的800个Collection Set, 要回收的集合,尽量把GC的停顿时间控制在我们指定的范围内。这个阶段其实也可以做到和用户线程一起并发执行,但是因为只回收一部分Region,时间是用户可控制的,而且停顿用户线程时间将大幅提高收集效率因为GC线程占用的CPU时间片多了),不管是年轻代还是老年代,回收算法主要用的还是复制算法,将一个Region中的存活对象复制到另一个Region中,这种不会像CMS那样回收完因为有很多内存碎片还需要整理一次,G1采用复制算法回收几乎不会有太多内存碎片
CMS回收阶段是跟用户线程一起并发执行的,但是G1因为内部实现太过复杂,所以暂时没有实现并发回收,到了ZGC,Shenandoah就实现了并发收集Shenandoah可以看作是G1的升级版
总体上来说,G1用的算法有点类似于标记-整理,因为产生很少的内存碎片,和标记-整理达到的效果是一样的,但是它底层还是用的标记-复制算法。
优化内容
- jdk9选用G1垃圾收集器作为默认垃圾收集器
- jdk10实现了并行Full GC,来优化G1的延迟
- jdk12G1收集器的优化,将GC的垃圾分为强制部分和可选部分,强制部分会被回收,可选部分可能不会被回收,提高GC的效率
Shenandoah
Shenandoah一词来自于印第安语,十九世纪四十年代有一首著名的航海歌曲在水手中广为流传,讲述一位年轻富商爱上印第安酋长Shenandoah的女儿的故事。 后来美国有一条位于Virginia州西部的小河以此命名,所以Shenandoah的中文译名为“情人渡”。
Shenandoah在Open JDK12中推出,是由Red Hat开发,主要为了解决之前各种垃圾回收器处理大堆时停顿较长的问题。
Shenandoah的设计目标是将停顿压缩到10ms级别(G1将低停顿做到了百毫秒级别),且与堆大小无关。它的很多设计点在权衡上更倾向于低停顿,而不是高吞吐。
Shenandoah是OpenJDK中的垃圾处理器,ZGC是Oracle JDK的垃圾处理器,Shenandoah很多方面与G1非常相似,甚至共用了一部分代码。
Shenandoah和G1有三点主要区别:
1.G1的回收是需要STW的,而且这部分停顿占整体停顿时间的80%以上,Shenandoah则实现了并发回收。
2.Shenandoah不再区分年轻代和年老代。
3.Shenandoah使用连接矩阵替代G1中的卡表。
- 卡表
G1堆中的每一个Region都有一份Rememberd Set,也叫RSet,它的作用就是为每一个Region记录哪些Region对其含有引用。
由于对象引用变更非常频繁,如果同步写卡表消耗非常大,所以通常会把更新信息存入队列中再异步更新RSet。耗费计算资源还占据了非常大的内存空间。- 连接矩阵
连接矩阵可以简单理解为一个二维表格,如果Region A中有对象指向Region B中的对象,那么就在表格的第A行第B列打上标记。
连接矩阵的颗粒度更粗,直接指向了整个Region,这是通过选择更低资源消耗的连接矩阵而对吞吐进行妥协的一项决策。
下图是shenandoah的运行示意图:
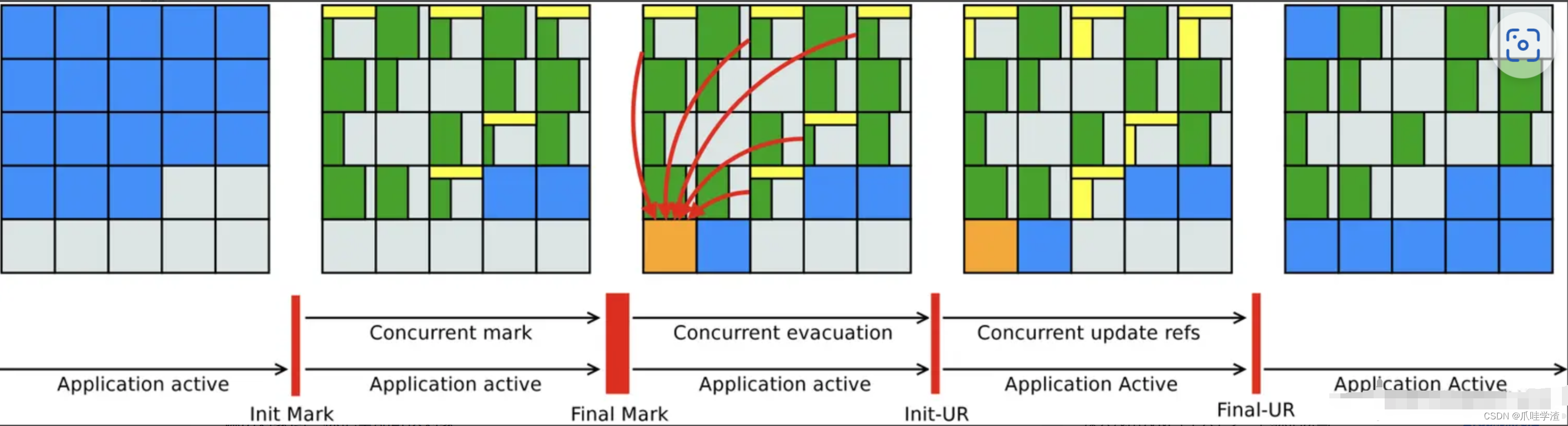
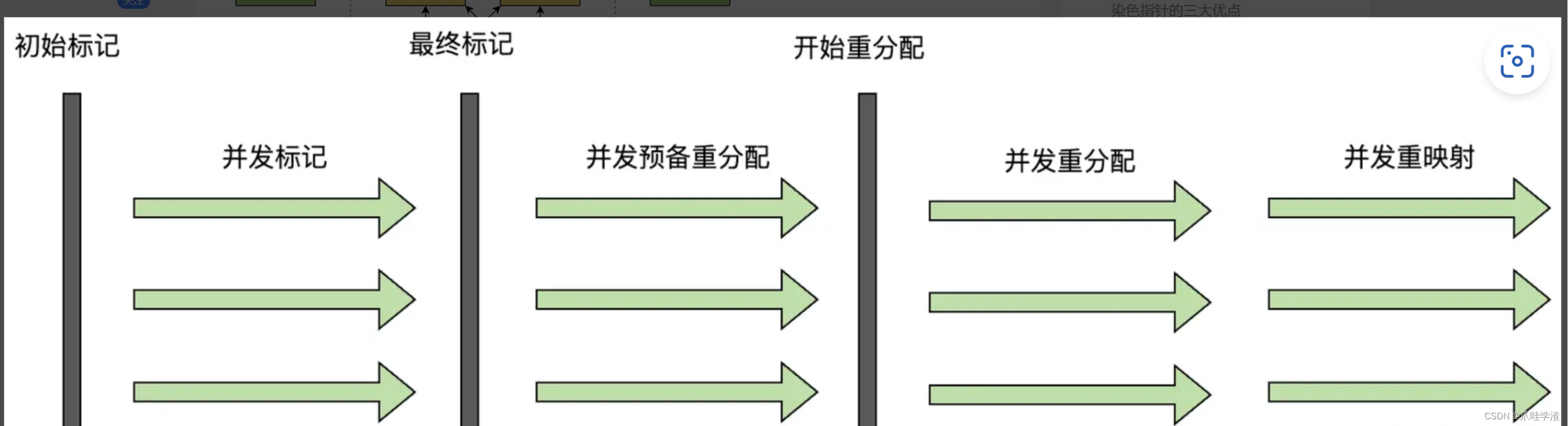
- 初始标记(Init Mark)[STW]: 标记与GC Roots直接关联的对象。
- 并发标记(Concurrent Marking): 遍历对象图,标记全部可达对象。
- 最终标记(Final Mark)[STW] : 处理剩余的SATB扫描,并在这个阶段统计出回收价值最高的Region,将这些Region构成一组回收集。
- 并发清理(Concurrent Cleanup) : 回收所有不包含任何存活对象的Region(这类Region被称为Immediate Garbage Region)。
- 并发回收(Concurrent Evacuation):
将回收集里面的存货对象复制到一个其他未被使用的Region中。并发复制存活对象,就会在同一时间内,同一对象在堆中存在两份,那么就存在该对象的读写一致性问题。Shenandoah通过使用转发指针(在对象头前面增加一个新的引用字段,在非并发移动情况下指向自己,产生新对象后指向新对象。那么当访问对象的时候,都需要先访问转发指针看看其指向哪里)将旧对象的请求指向新对象解决了这个问题。这也是Shenandoah和其他GC最大的不同。 - 初始引用更新(Init Update References)[STW]:
并发回收后,需要将所有指向旧对象的引用修正到新对象上。这个阶段实际上并没有实际操作,只是设置一个阻塞点来保证上述并发操作均已完成。 - 并发引用更新(Concurrent Update
References):顺着内存物理地址线性遍历堆空间,更新并发回收阶段复制的对象的引用。 - 最终引用更新(Final Update References)[STW]:堆空间中的引用更新完毕后,最后需要修正GC Roots中的引用。
- 并发清理(Concurrent Cleanup):此时回收集中Region应该全部变成Immediate Garbage
Region了,再次执行并发清理,将这些Region全部回收。
ZGC
介绍
ZGC是Oracle在JDK11中引入,并于JDK15中作为生产就绪使用,其设计之初定义了三大目标:
1.支持TB级内存
2.停顿控制在10ms以内,且不随堆大小增加而增加
3.对程序吞吐量影响小于15%
随着JDK的迭代,目前JDK16及以上版本,ZGC已经可以实现不超过1毫秒的停顿,适用于堆大小在8MB到16TB之间。
内存布局
ZGC和G1一样也采用了分区域的堆内存布局,ZGC的Region(官方称为Page,概念同G1 Region)可以动态创建和销毁,容量也可以动态调整。
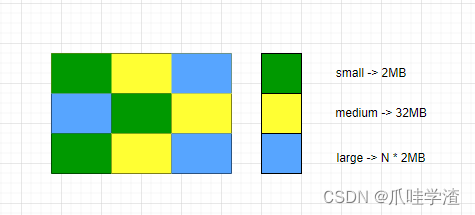
ZGC的Region分为三种:
1.小型Region容量固定为2MB,用于存放小于256KB的对象。
2.中型Region容量固定为32MB,用于存放大于等于256KB但不足4MB的对象。
3.大型Region容量为2MB的整数倍,存放4MB及以上大小的对象,而且每个大型Region中只存放一个大对象。由于大对象移动代价过大,所以该对象不会被重分配。
重分配集(RS)
G1中的回收集用来存放所有需要G1扫描的Region,而ZGC为了省去卡表的维护,标记过程会扫描所有Region,如果判定某个Region中的存活对象需要被重分配,那么就将该Region放入重分配集中。
通俗的说,如果将GC分为标记和回收两个主要阶段,那么回收集是用来判定标记哪些Region,重分配集用来判定回收哪些Region。
染色指针
和Shenandoah相同,ZGC也实现了并发回收,不同的是前者是使用转发指针来实现的,后者则是采用染色指针的技术来实现。
三色标记本质上与对象无关,仅仅与引用有关:通过引用关系判定对像存活与否。HotSpot虚拟机中不同垃圾回收器有着不同的处理方式,有些是标记在对象头中,有些是标记在单独的数据结构中,而ZGC则是直接标记在指针上。
64位机器指针是64位,Linux下64位中高18位不能用来寻址,剩下46位中,ZGC选择其中4位用来辅助GC工作,另外42位能够支持最大内存为4T,通常来说,4T的内存完全够用。
运行过程
- 并发标记 并发标记阶段和G1相同,都是遍历对象图进行可达性分析,不同的是ZGC的标记在染色指针上。
- 并发预备重分配
在这个阶段,ZGC会扫描所有Region,如果哪些Region里面的存活对象需要被分配的新的Region中,就将这些Region放入重分配集中。
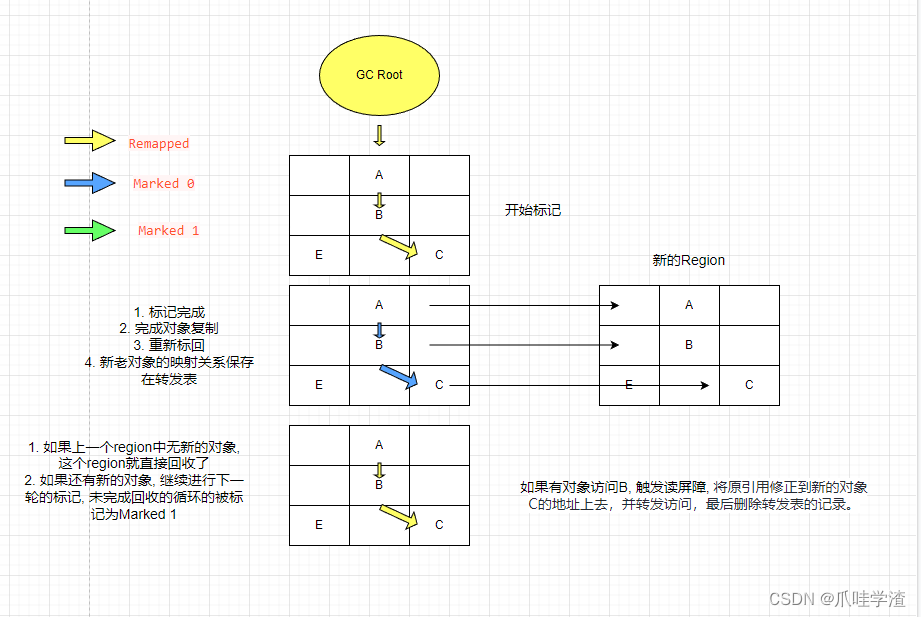
此外,JDK12后ZGC的类卸载和弱引用的处理也在这个阶段。 - 并发重分配
ZGC在这个阶段会将重分配集里面的Region中的存货对象复制到一个新的Region中,并为重分配集中每一个Region维护一个转发表,记录旧对象到新对象的映射关系。
如果在这个阶段用户线程并发访问了重分配过程中的对象,并通过指针上的标记发现对象处于重分配集中,就会被读屏障截获,通过转发表的内容转发该访问,并修改该引用的值。
ZGC将这种行为称为自愈(Self-Healing),ZGC的这种设计导致只有在访问到该指针时才会触发一次转发,比Shenandoah的转发指针每次都要转发要好得多。
另一个好处是,如果一个Region中所有对象都复制完毕了,该Region就可以被回收了,只要保留转发表即可。 - 并发重映射 最后一个阶段的任务就是修正所有的指针并释放转发表。
这个阶段的迫切性不高,所以ZGC将并发重映射合并到在下一次垃圾回收循环中的并发标记阶段中,反正他们都需要遍历所有对象。
版本升级问题
- javax包改名为jakarta了(servelt, validation等相关的包要重新引入)
- @EnableEurekaClient修改为@EnableDiscoveryClient
- junit4改为junit5
- @RequestMapping不能添加在@FeignClient接口上了, 通过@FeginClient的path属性处理
- springfox需要3.0版本
- 使用jdk17后, spring framework必须要升级到5.3.x以上版本才支持
- springboot如果使用3.x.x版本, 必须使用jdk17

















 423
423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









