







引言
喷泉码不算一个特别新的码字了,2002年Luby就提出了喷泉码的概念,当年Luby也拿着这个东西去创业了,好像后面还是死掉了,但不管怎么说,这个码字还是十分有应用价值的,核心在于其编解码算法理解简单,实现也比较简单,就是对于其度分布的核心生成的推导十分复杂。系列文章分为两篇,第一篇主要是对于典型的喷泉码,LT码的编译码算法的详解,第二篇会对于其度分布生成的推导过程进行引导性的说明(核心的那一块的随机游走过程太难说了,有兴趣的自己看论文吧),对于LT码的实现,我写了一份放在GitHub上,网址为:https://github.com/zk3326312/LT_code/,其中包含一份matlab的实现,方便理解整体的过程,一份是c++的,将LT码的整体功能封装为了一个类,如果要使用只需注册一个发送回调函数即可使用,另一份是纯c语言编写的,这一份代码提供了LT码的各种编译码功能函数,OK,下面我们开始对LT码的编译码算法流程进行详细的说明。
LT码编译码算法流程详解
喷泉码是一类基于图的线性纠删码,而LT码是一种被提到3GPP标准中的实际可用的喷泉码,顾名思义,喷泉码中,编码包就如同喷泉的水滴,而接收方只要能接收到足够多的水滴就能够形成一桶水(译码得到原始数据)。反映在实际流程上,就是发送端对原始信息进行编码,得到源源不断的编码信息并且发送,只要接收端能正确接收到足够的编码信息就可以译出原始数据。在二进制删除信道上(数据包要么正确接收,要么丢包),这个过程相比于反馈重传的机制来说更为有效,尤其适是RTT较大的环境。
而LT码的编译码过程并不复杂,尤其是编码过程,十分简单,依据相应的公式生成度分布,按照流程生成相应的编码包即可,具体流程如下
LT码的编码算法
LT码作为第一种实用的喷泉码,其编码过程较为简单,下面就某一编码包的产生过程介绍如下:
① 由已定的度分布p(d)(度现有的良好度分布为鲁棒孤波分布,具体流程在后续表附录);
② 随机选取一个度值d;
③ 将这d 个不同的数据包求异或和,生成该编码包。
具体过程如下图所示
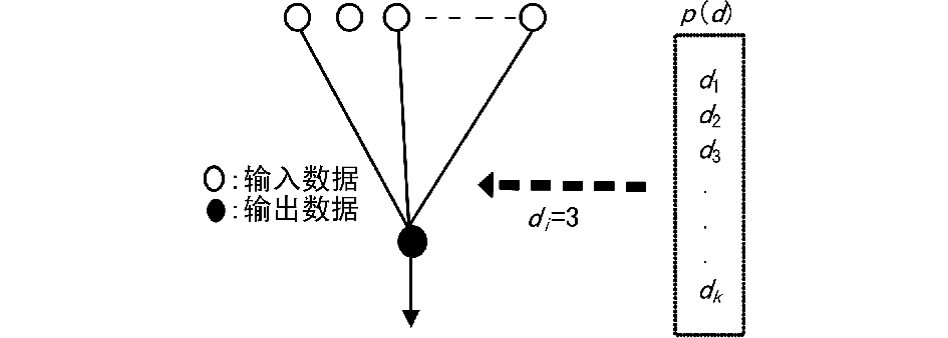
不断重复上面的步骤,就可以得到无限多个编码分组。在这些步骤中一些细节需要注意:LT 码编码之前要先确定度分布函数,度值的确定由度分布函数来计算。不同的度分布,k的概率值是不同的,但度分布概率函数只是确定了取度值为d的概率是多少,而并不能确定这d个原始编码分组是哪些,所以对于这d个原始编码分组的选择来说是任意的,本文对这d个原始编码分组的选择采用均匀分布来进行选取,即从区间[1,k]中按均匀分布随机生成d个整数。区间[1,k]中所有整数被选取的概率是相等的。把这d个整数进行异或,就得到了一个编码分组。
LT码的译码算法
LT码的译码算法有两种,BP(后向传播)译码算法和GE(高斯消元)译码算法,本文先从图的形式讲述译码过程,再通过矩阵的形式讲述译码过程,方便大家理解。我们之前提到的,喷泉码时一类基于图的线性纠删码,什么意思呢?我们来看一个BP译码过程的Tanner图
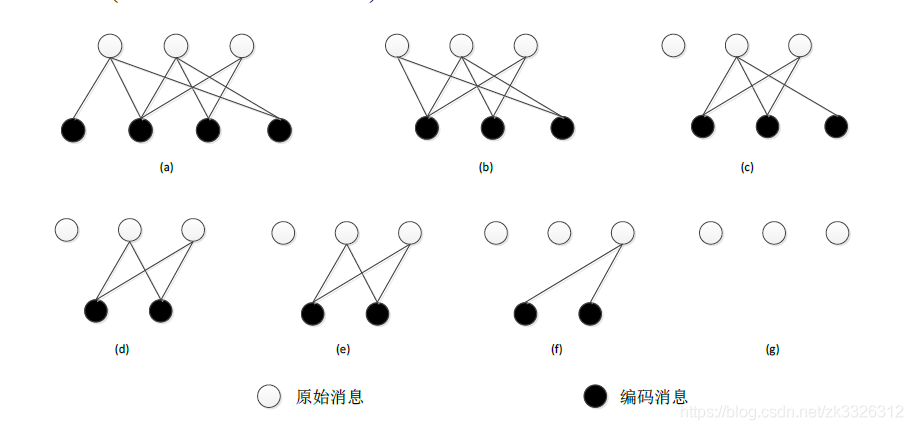
对于一个编码包来说,与他相连的所有原始消息进行异或得到了编码消息,我们可以通过一个度数为1的编码包(也就是只有一个原始消息参与的编码包,即编码包等于原始消息)来使与之关联的编码包的度数减1,什么意思呢?我们称“+”为异或运算,我们知道a+a = 0。对于一个编码数据包来说,编码数据为a+b+c,即此编码包度数为3,而我们此时收到了一个度数为1,消息为a的编码包,我们可以通过a+b+c+a = b+c。此时编码包度数为2了,如果我们此时又收到一个度数为1,消息为b的数据包,则可以通过b+c+b = c,使编码包度数变为1,而此时这个编码包的度数为1,消息为c,它可以参与到另一个编码包如c+d的译码过程中去,通过这样的不断迭代,我们最终就可以把a,b,c,d.....所有原始数据包解出,这也就是所谓的BP译码算法。
那么怎么从矩阵的角度来理解译码过程呢?设原始数据分片后的消息矩阵为S,编码过程相当于乘以一个生成矩阵G,设编码后矩阵为M,则整个编码过程可以表示为M= SG,式子可以通过向量表示为:
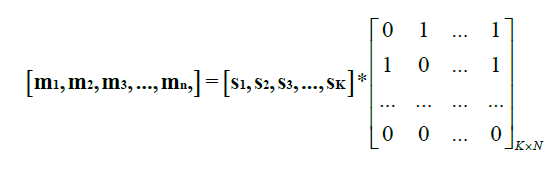
生成矩阵G为一个根据度分布随机生成的K*N的矩阵,其中K为LT码码长,N为生成的编码包数量,其值理论上可以为无穷大,G矩阵中的每一列中1的个数就表明生成的编码包的度数,其中1的位置表明参与编码的源数据包的序号,因此,当G的秩等于K(行满秩)时,整个方程组是可解的,此时源消息可译码,当G的秩不足K时,接收端持续接收数据包,反应在矩阵上为G的列数持续增加,直到G的秩满足要求。解方程组的过程我们一般通过高斯消元进行,这也就是所谓的高斯消元译码。以矩阵的形式来看,BP译码也就是每次找寻一个1的个数仅为1的Mi来进行译码。
讲到这里,基本的LT码编译码流程就说完了,拿来用已经足够了,如果你后续还想对LT码有一些深入的理解,请看我后续的博文。
附表-鲁棒孤波分布
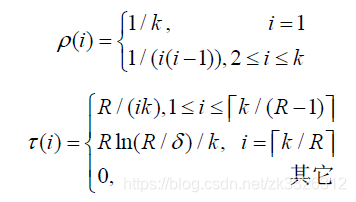
其中:
![]()
将(i)和其对应的
 (i)相加起来,然后再归一化,就得到了鲁棒孤波分布的表达式:
(i)相加起来,然后再归一化,就得到了鲁棒孤波分布的表达式:
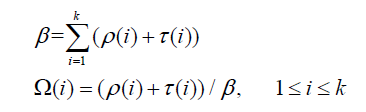

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









