







aggregate聚合,是一个action
有一个初始值,有两个函数参数,第一个是把各个分区聚合,第二个分区结果聚合
例如
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
rdd1.aggregate(0)(_+_, _+_) //先对第一个分区数求和,在对各个分区后的数据求和
rdd1.aggregate(10)(_+_, _+_)//10与各个个分区数值相加,最后各个分区结果值再与初始值10相加
//结果为10+1+2+3+4+10+5+6+7+8+9+10
rdd1.aggregate(5)(math.max(_, _), _ + _)//math.max(_, _) 将每个分区数据取出进行两两比较取最大,分区结果相加
//初始值为5,将初始值5与每个分区数据进行比较,第一个分区值为5,第二个为9,
//再与初始值相加结果为5+5+9=19
定义一个函数查看各个分区数据分布
val func1= (index: Int, iter:Iterator[(Int)]) => {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator}
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
rdd1.mapPartitionsWithIndex(func1).collect
分区数据结果

val rdd4 = sc.parallelize(List("12","23","345",""),2)
rdd4.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)
//空字符串math为0
//先 math.min("".length,"12".length) res int=0 toString 为"0"
//math.min("0".length,"23".length)
//math.min("345".lengtg,"".length) res int =0
aggregateByKey
对key分组进行操作,先进行局部操作,在进行整理操作
val pairRDD = sc.parallelize(List( ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 2)
def func2(index: Int, iter: Iterator[(String, Int)]) : Iterator[String] = {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
} //第一个参数分区编号,第二个是迭代器:分区数据,返回一个迭代器
pairRDD.mapPartitionsWithIndex(func2).collect
分区数据结果

pairRDD.aggregateByKey(0)(math.max(_, _), _ + _).collect
//把一个区每个key最大值取出,在将每个相同key相加
结果为:

pairRDD.aggregateByKey(0)( _ + _, _ + _).collect
//将每个分区key的值相加,最后再全局统计 将每个key值相加
pairRDD.reduceByKey()(_ + _).collect //与aggregateByKey结果相同,
//相当于把_ + _先传给局部函数再传给全局函数
结果为:

reduceByKey与groupBykey区别
reduce 是先进行局部求和然后进行汇总,reduceByKey底层用的是conbineByKey()(这个底层接口使用必须要写类型)
group将k,v数据都放入一个大集合里面, shuffle的时候会消耗更多的带宽。
combineByKey : 和reduceByKey是相同的效果
分组后,第一个参数:第一个元素取出来进行操作, 第二个参数:是函数, 局部运算, 第三个:是函数, 对局部运算后的结果再做运算
每个分区中每个key中value中的第一个值, (hello,1)(hello,1)(good,1)–>(hello(1,1),good(1))–>x就相当于hello的第一个1, good中的1
// 从HDFS中读数据,有几个块就会默认分几个区
val rdd1 = sc.textFile("hdfs:/192.168.146.100:9000/wordcount/input/").flatMap(_.split(" ")).map((_, 1))
val rdd2 = rdd1.combineByKey(x => x, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n)
//x => x, (a: Int, b: Int) => a + b, 解释
//x => x 将第一个元素原封不动的取出来
//第二个函数必须要写类型,把vlue值原封不动取出来,
//a,b都是局部1,然后相加
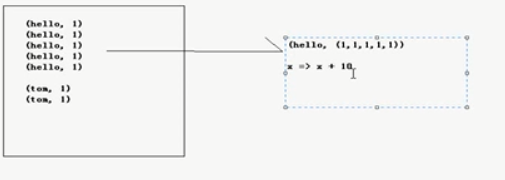
combineByKey 之后为(hello,(1,1,1,1,1))
x相当于一个初始值10+1,局部操作 11+1+1+1+1
val rdd4 = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), 3)
val rdd5 = sc.parallelize(List(1,1,2,2,2,1,2,2,2), 3)
val rdd6 = rdd5.zip(rdd4) //拉链操
val rdd7 = rdd6.combineByKey(List(_), (x: List[String], y: String) => x :+ y, (m: List[String], n: List[String]) => m ++ n)
//val list=List(1) 不可变list 不能直接用+=
//list:+2 res:List(1,2) 原list没有变还是list=List(1)
//list++list res2:List(1,1) 俩list相加
//list ::: res res1:List[int]=List(1,1,2) :+追加一个元素,::: 追加两个list
rdd6 拉链操作结果为:

rdd7解释:
combineByKey得到(1,(dog,cat,turkey))
第一个函数List(_) 弄一个集合把dog放进去,_就代表将dog放入
第二个函数 将局部追加到List里面。因为第一个将它转为List了 故第一个参数x:List[string] ,第二个参数是其他的字符所以是String。 将字符逐步追加到List里面
第三个函数 将List相加

结果:
repartition 能对数据重新分区
coalesce, repartition 功能差不多
val rdd1 = sc.parallelize(1 to 10, 2)
val rdd2=rdd1.repartition(3) //数据可能被打散,进行shuffle 网络传输,跑到另外一台机器上
val rdd3 = rdd1.coalesce(4) //第二个参数默认不进行shuffle 结果还是为3个分区
val rdd3 = rdd1.coalesce(4,true) //分区为4个
rdd3.partitions.length
collectAsMap
把结果放入一个Map
val rdd = sc.parallelize(List(("a", 1), ("b", 2)))
rdd.collectAsMap

countByKey
计算Key的数量
val rdd1 = sc.parallelize(List(("a", 1), ("b", 2), ("b", 2), ("c", 2), ("c", 1)))
rdd1.countByKey

countByValue
rdd1.countByValue

filterByRange
返回一个范围
val rdd1 = sc.parallelize(List(("e", 5), ("c", 3), ("d", 4), ("c", 2), ("a", 1)))
val rdd2 = rdd1.filterByRange("b", "d")
rdd2.collect

flatMapValues
先把value处理
val rdd3 = sc.parallelize(List(("a", "1 2"), ("b", "3 4")))
val rdd4 = rdd3.flatMapValues(_.split(" "))
rdd4.collect
// Array((a,1), (a,2), (b,3), (b,4))
foldByKey
val rdd1 = sc.parallelize(List("dog", "wolf", "cat", "bear"), 2)
val rdd2 = rdd1.map(x => (x.length, x)) //将字母长度与字母放入一个元组里
val rdd3 = rdd2.foldByKey("")(_+_) //将相同key的value拼接
//结果res14: Array[(Int, String)] = Array((4,wolfbear), (3,dogcat))
foreach
对每一个rdd元素进行操作
foreachPartition
把每一个分区进行操作,不会产生一个新的rdd
keyBy 以传入的参数做key
val rdd1 = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)
val rdd2 = rdd1.keyBy(_.length) //把长度作为key
val rdd3 = rdd1.keyBy(_(0)) //第一个字母作为key
rdd2.collect
//结果rdd2: Array[(Int, String)] = Array((3,dog), (6,salmon), (6,salmon), (3,rat), (8,elephant))
keys values
val rdd1 = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2)
val rdd2 = rdd1.map(x => (x.length, x))
rdd2.keys.collect //把key取出来 res18: Array[Int] = Array(3, 5, 4, 3, 7, 5)
rdd2.values.collect //把value取出来 res19: Array[String] = Array(dog, tiger, lion, cat, panther, eagle)
http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html
RDD算子权威解释














 240
240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









