







NIST 测试套件是由15个测试组成的统计软件包,这些是为了测试随机(任意长度)由基于硬件或软件的密码随机或伪随机数生成器产生的二进制序列。测试关注于各种不同类型的已存在的非随机序列。有些测试可以分成各种子测试。
15个测试主要是(属于密码算法安全测试方法):
- 频率(单比特)测试
- 块内频数测试(Frequency Test within a Block)
- 动向(Run)测试
- 最大游程检测
- 二进制矩阵秩(Binary Matrix Rand)测试
- 频谱测试
- 非重叠字匹配测试
- 重叠字匹配测试
- Maurer通用统计检测
10、线性复杂度测试
11、系列(Serial)测试
12、近似熵测试
13、累积和测试
14、随机游程(Random Excursions)测试
15、随机游程变量(Random Excursions Variant)测试
这里没有依赖性(扩散与混乱)---完备性与雪崩效应测试、自相关测试和Lempel-Ziv压缩测试。
下载的软件sts-2.1.2压缩包中,解压后源文件中有上述的密码算法安全测试的源码,如下
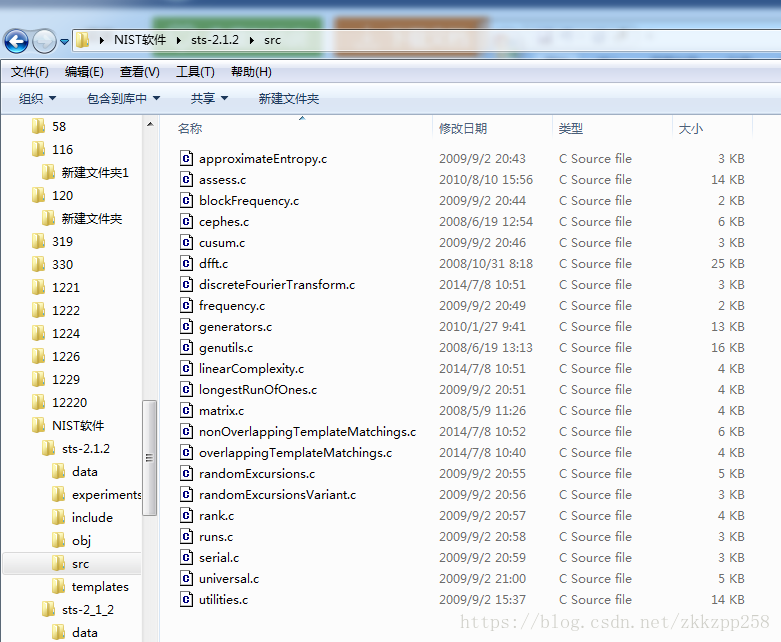
若在windows下,由于该软件是基于linux环境开发的,里面的源文件由makefile控制,要想在windows下使用,则需要借助另一软件Cygwin。
Cygwin官网下载地址:http://www.cygwin.com/
安装使用该软件参考:http://www.programarts.com/cfree_ch/doc/help/UsingCF/CompilerSupport/Cygwin/Cygwin1.htm
上面有详细讲说,但对于这个随机数测试包需要注意的主要是一下几点:
1、下载安装的时候一定注意要把组件都勾上,特别是gcc一定要勾上,如果不知道怎么选,那就有gcc的地方全勾上吧。因为需要gcc这个编译器。
2、运行Cygwin,进入该软件包sts-2.1.1中包含makefile文件的文件夹,输入:make命令,该软件就在安装了,完后之后会发现多了一个文件(assess.exe),那个就是可执行文件了。有了它就安装成功了。
还可以参考一下链接:https://wenku.baidu.com/view/dc0ada02eff9aef8941e0644.html
由于本机本身装有虚拟机及ubuntu系统,所以直接在Linux操作系统下安装。步骤如下:
- 打开已经安装好的ubuntu系统,在管理员权限进入系统,把已经下好的数字测试套件包拷贝到Home目录下
- 对包进行解压缩,解压在该目录下。
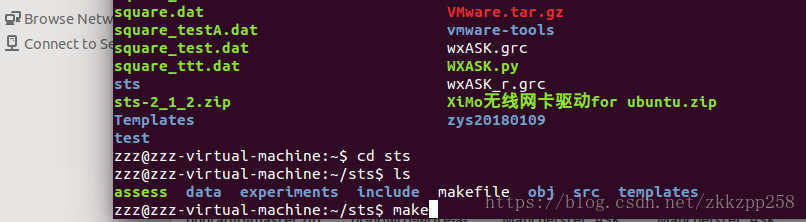
- 进入到解压缩的该目录下(输入命令cd 文件名)
- 输入make进行编译makefile文件,得到assess文件(编译成功后该目录下会有assess文件)
- 在该目录下输入./assess <datalength>,datalength为测试的数据长度。
下面举例说明
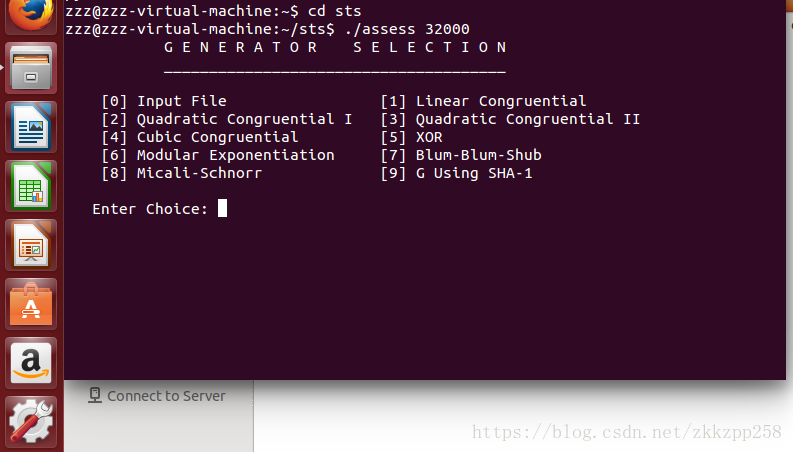
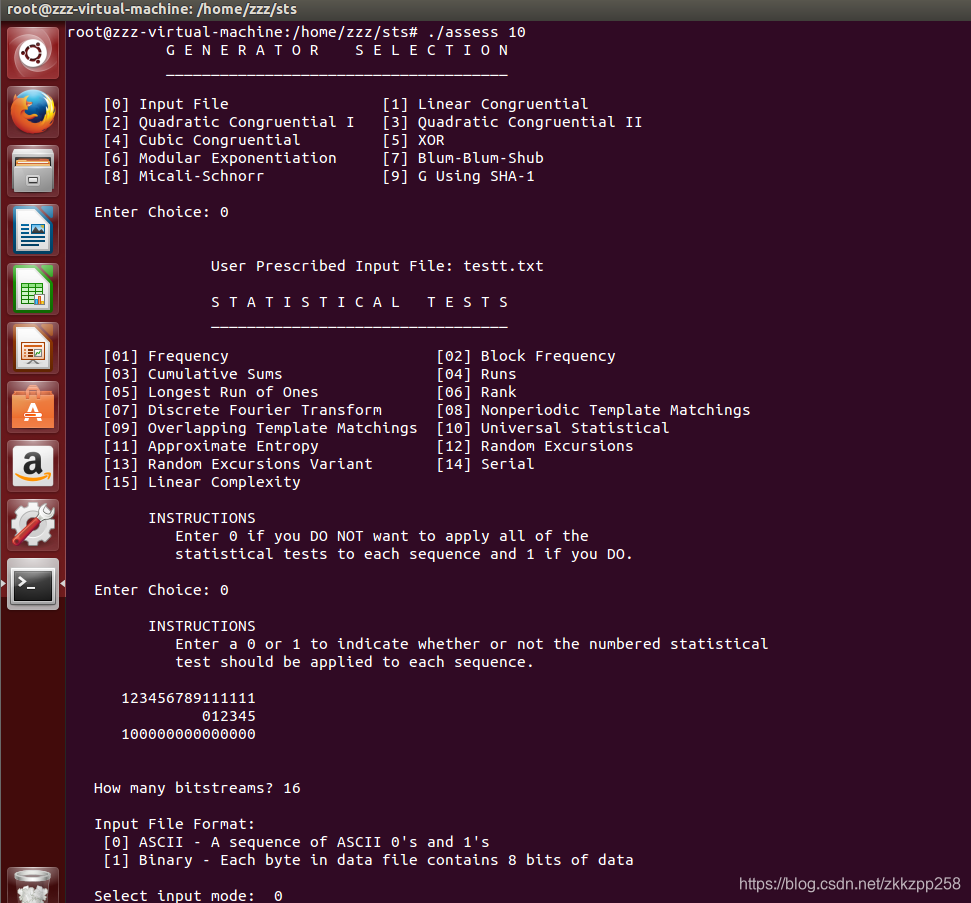
- 进入软件界面后,有基本操作指示(生成器选项)
基本测试用matlab写一个随机数矩阵(x = randsrc(1,32e3,[0,1]);
)把数据复制到txt文本中,然后把随机数矩阵的文本array.txt复制到该目录下,

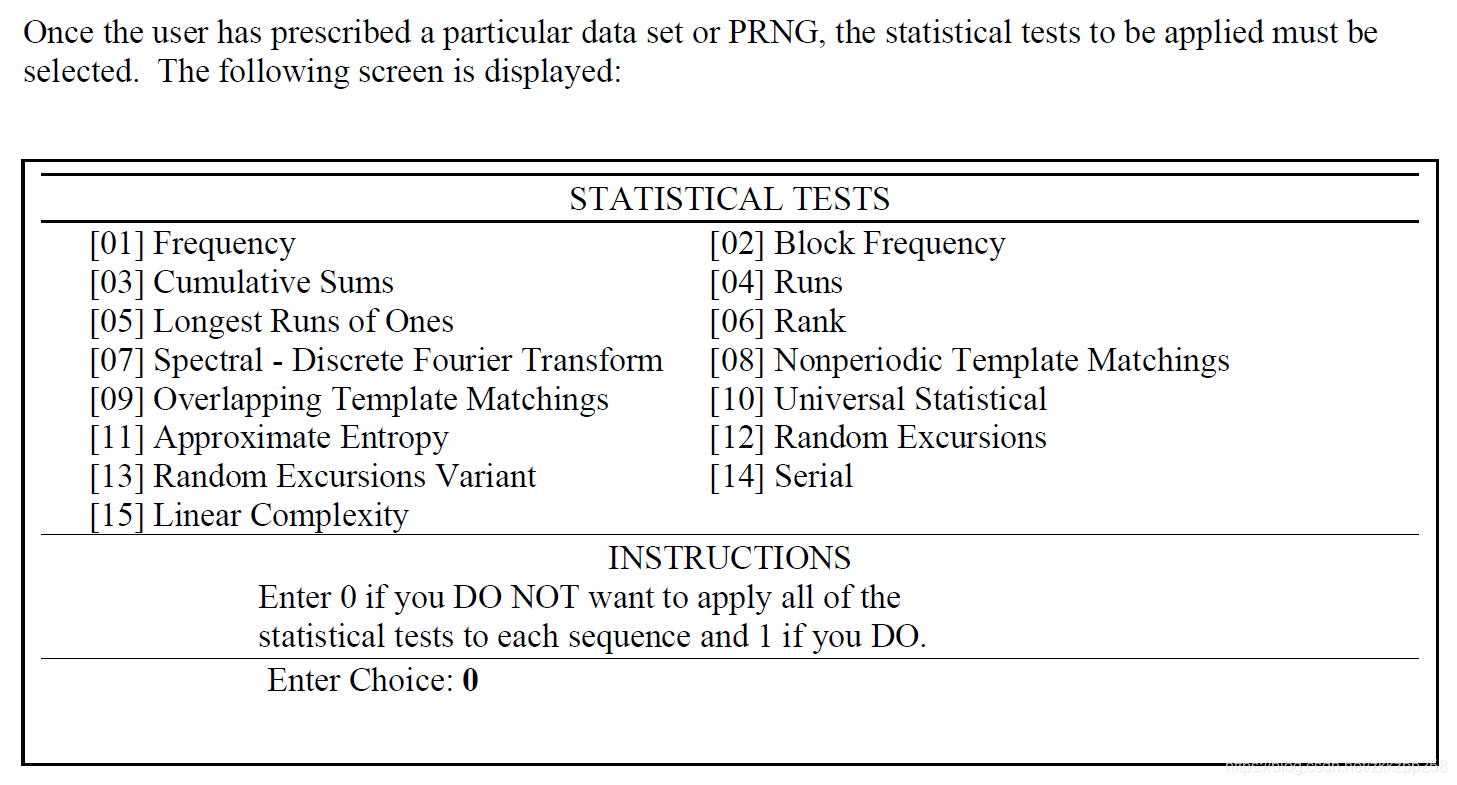
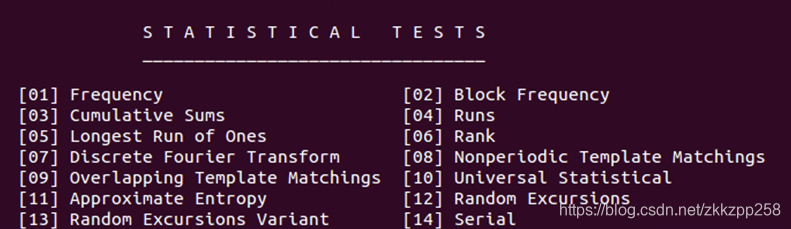
根据生成器提示选择0输入文件,输入array.txt,之后则是选择测试类型,即上面的15种测试类型。
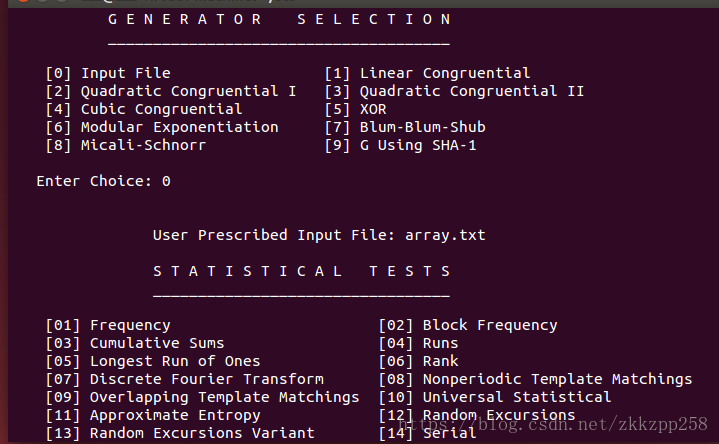
或者测试全部,它有一个提示可以测试上述15种测试,即Enter Choice输入1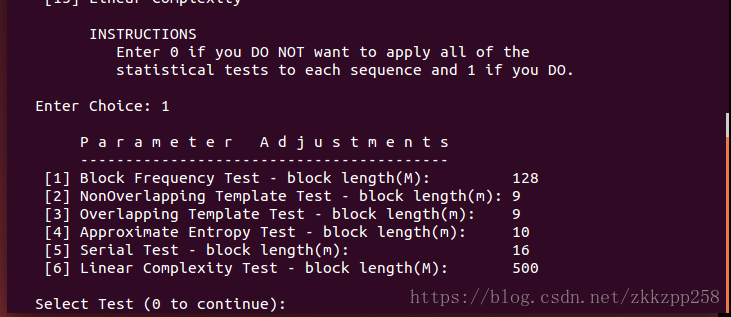
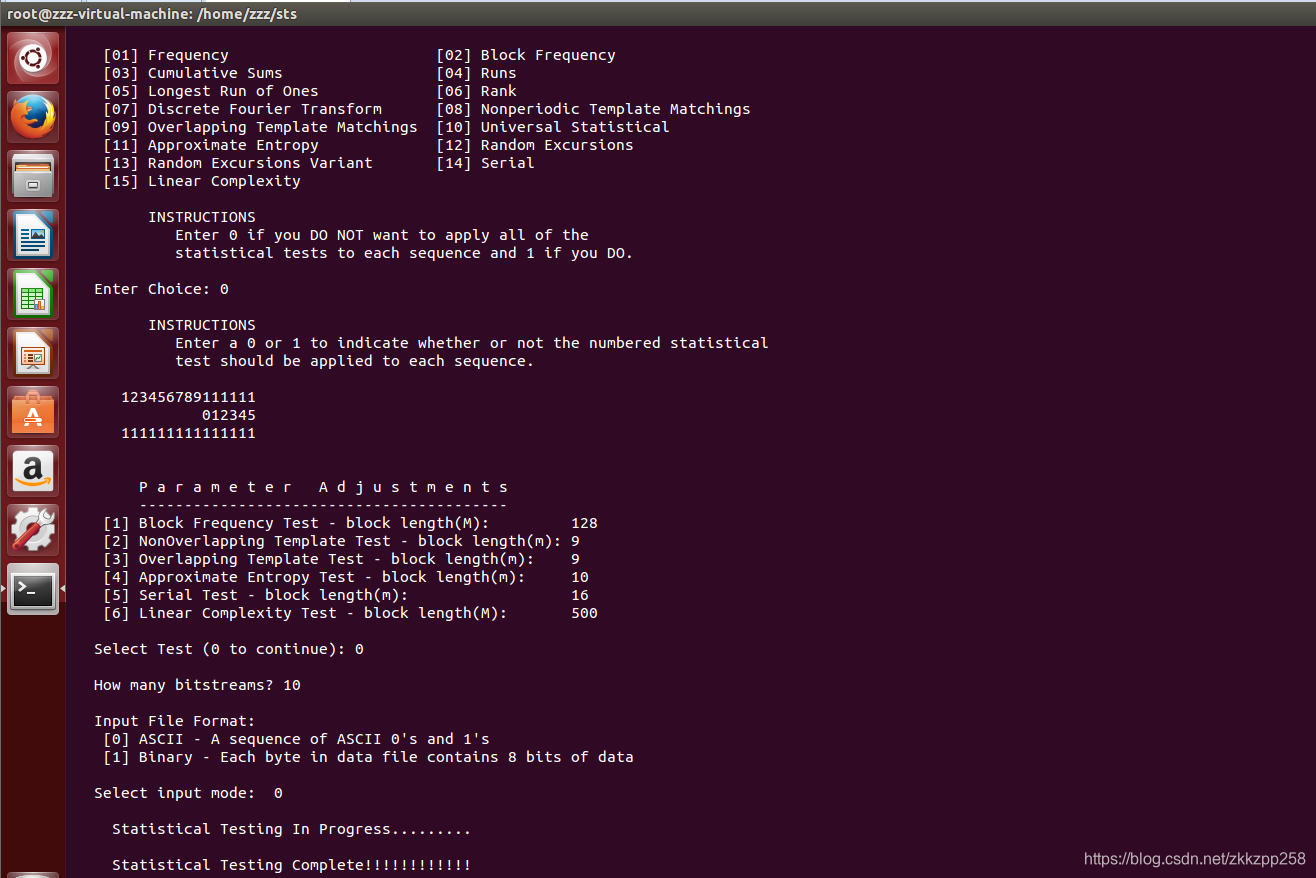
How many bitstreams? 输入流个数;这个流个数和第一步中的文件位长度存在这样关系:
位长度*bitstreamsnum=文件总位长度。一般随机数文件在32M以内(2G内存支持),bitstreamsnum默认输入1,第一步输入文件总bit长度。如果文件超过32M那么计算过 程中内从不足,因此需要第一步输入文件总长度的1/8、1/16...,然后在此处输入8、16,等价于把源文件划分为等长的几条流,来做随机性检查。
Bitstreams输入默认1后,下面会问输入文件的形式是ASCII类型的数据构成的序列(ASCII 中的0和1)还是8位的二进制数据。
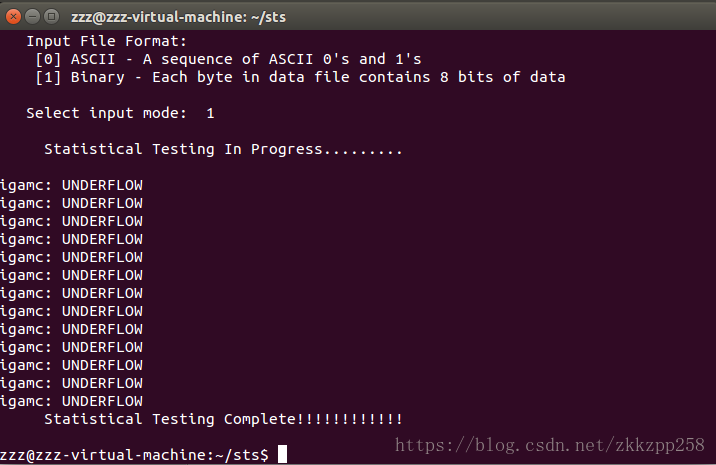
最后完成后的结果在该目录下的experiments/AlgorithmTesting下的某种测试目录下

每种算法目录下都有stats.txt 文件中描述的是P-value值,在ALPHA = 0.0100条件下(默认值),貌似这个值大于0.01就表示差不多随机,越大越好。
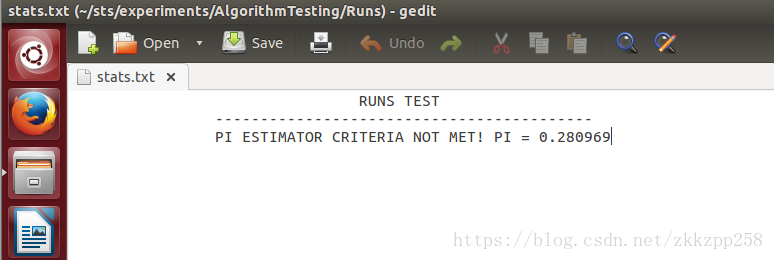
注意:使用所有测试时,参数设置如下,但是可能数据长度并不适合某些测试,所以最后只有13种统计测试完成。
测试方法参看:https://wenku.baidu.com/view/020b8df47c1cfad6195fa7e0.html
伪随机性是密码算法安全性的重要指标,用于评估密码算法的伪随机性,其原理一般是假设检验,一般要求接收水平Pv>0.01
比如看动向(Run)测试结果不符合统计量标准PI=0.280969
单比特动向测试是检测算法f的输出在0和1之间摆动的次数,其测试方法如下:


测试数据文件,有几个示例在下面这个文件夹中

1M二进制比特位数据

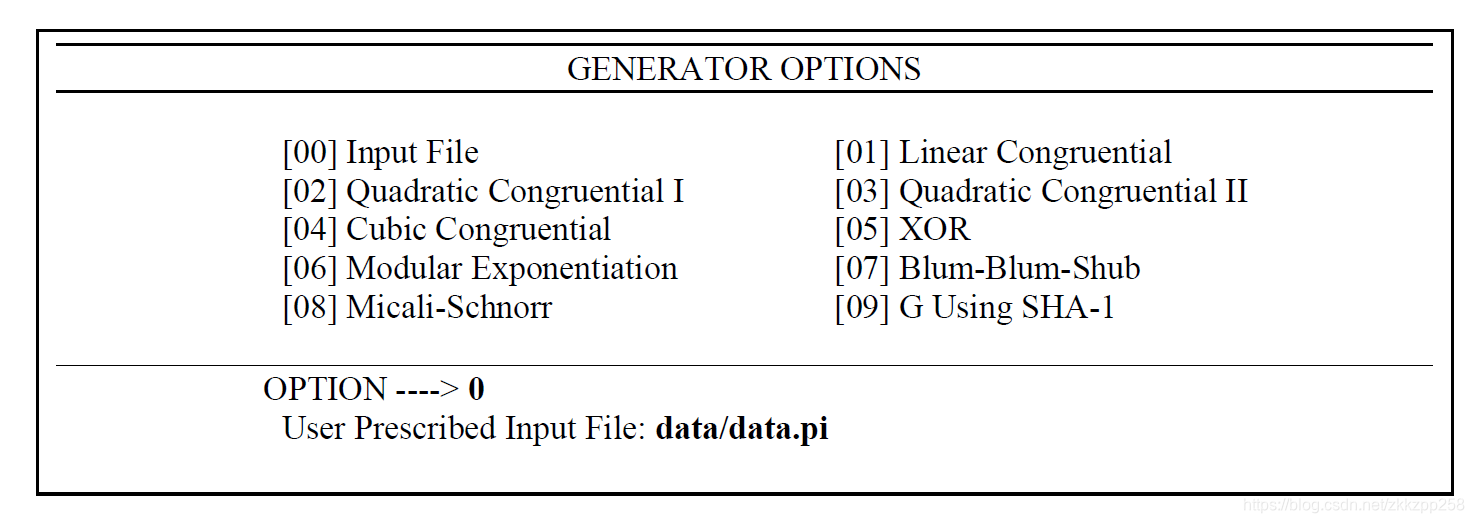

 这个地方输入表示的是15个测试中哪些测试是需要应用在该序列中,1表示应用,0表示不应用,这里就是表示重叠字匹配测试(Overlapping Template Matchings)
这个地方输入表示的是15个测试中哪些测试是需要应用在该序列中,1表示应用,0表示不应用,这里就是表示重叠字匹配测试(Overlapping Template Matchings)


我们照着样例文件写数据,按照示例测试data.pi数据:
Data.pi数据中的二进制数我们可以先复制到test.txt文件中,再用matlab读取数据
clc;clear;
res = textread('test.txt','%s');
%res为待转换的cell
for n=1:length(res)
x{n}=str2num(res{n});
end
for m=1:length(x)
y(m)=x{m}(1);
end
% format longG
得到data.pi中的数据总共有1004932个二进制数
 The file finalAnalysisReport.txt contains the results of these two forms of analysis.
The file finalAnalysisReport.txt contains the results of these two forms of analysis.
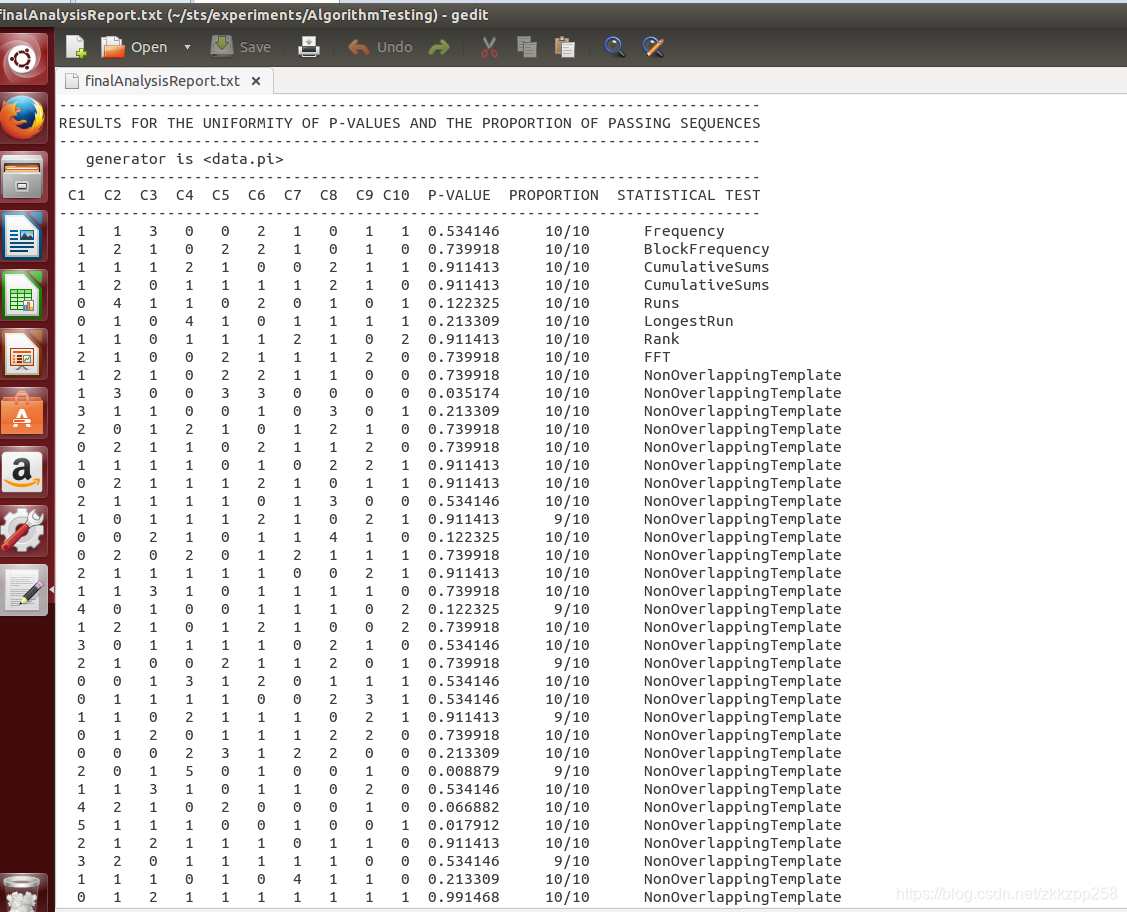 这里在sts目录下的experiments/AlgorithmTesting的finalAnalysisReport.txt文件中可以看到所有测试的结果。注意这里data.pi输入数据是100000的值,那么./assess 100000就得写10万,不然会报数据不够的错误。
这里在sts目录下的experiments/AlgorithmTesting的finalAnalysisReport.txt文件中可以看到所有测试的结果。注意这里data.pi输入数据是100000的值,那么./assess 100000就得写10万,不然会报数据不够的错误。

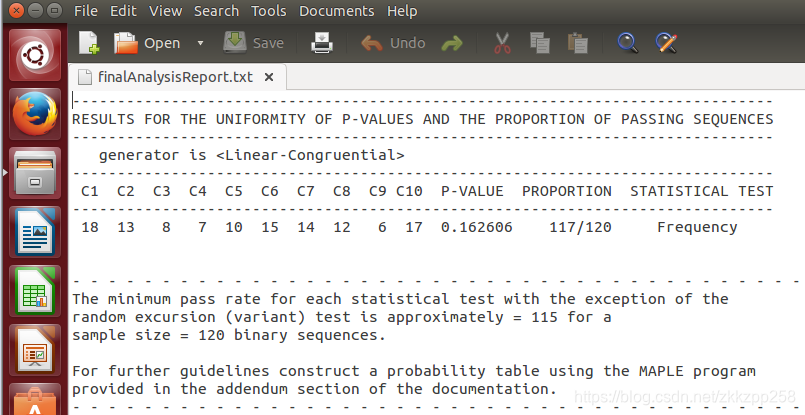
列C1-10代表相对应的p值的频率,列ProPortion代表二进制序列通过的比率。if 1000 binary sequences were tested (i.e., m= 1000), α= 0.01 (the significance level), and 996 binary sequences had P-values ≥.01, then the proportion is 996/1000 = 0.9960.
二进制序列长度就改how many bitstreams的位置。(只是需要注意./assess 长度*bitstreams长度要小于原数据总的数据长度)
./assess 长度,这里的长度是一组的长度,所以要注意序列的位数一定要足够,不然测试会报数据不够的错误。
./assess 10000(数据长度改小测试一下),结果如下
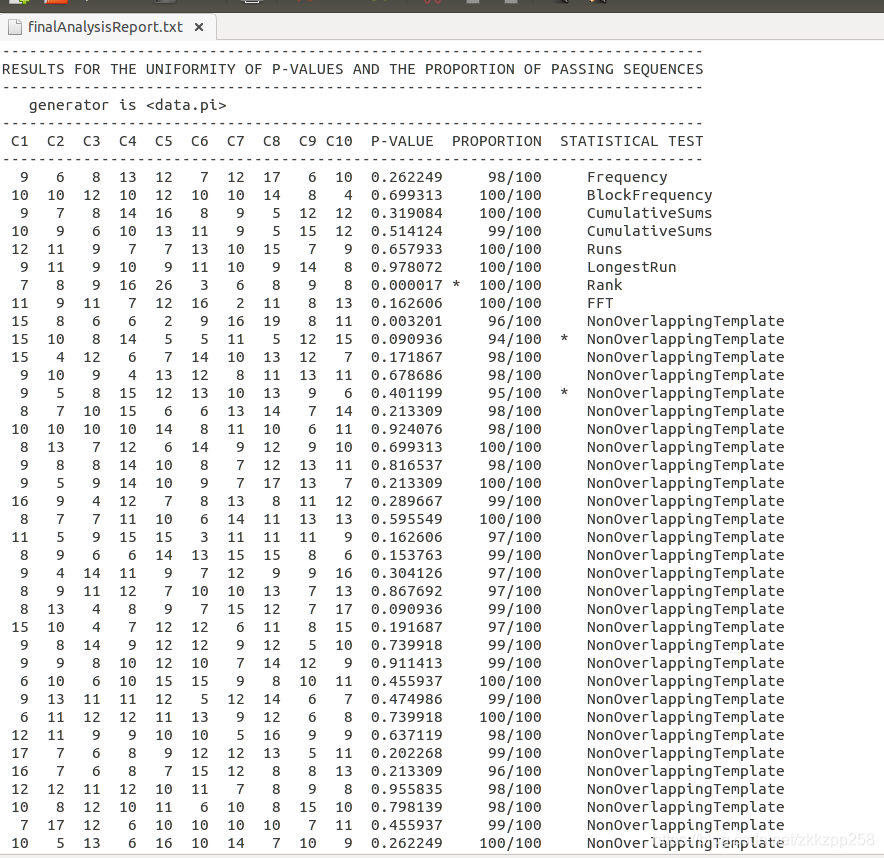
上述结果是bitstreams=100时的结果,bitstreams是测试样例中有多少组数据,proportion表示比特流中的比率
nistspecialpublication800-22r1a说明文档中,91页写到一般建议和规范,告诉我们为什么数据集没有通过统计测试:
- An incorrectly programmed statistical test:除了特殊情况,我们认为统计测试是为了解决某类特殊问题而量身定做的。但是部分统计测试受限于人工上限,比如随机偏移测试不能大于max{1000,n/128}次循环,依据实验条件,参数可能需要增加。
- An underdeveloped (immature) statistical test:很多统计测试都是以渐进近似为基础的
- An improper implementation of a random number generator:有可能由于硬件上设计的瑕疵或者编码实现错误导致硬件RNG或者软件RNG失败。
- Improperly written codes to harness test input data:一般测试数据在统计测试之前由RNG生成。比如,可能处理包括由RNG分割成合适大小的块的输出流,以及0转换成负数。
- Poor mathematical routines for computing P-values
- Incorrect choices for input parameters:某些统计测试可能对输入参数较为敏感。比如序列长度10^6,块长度接近log2(n)是可以接受的。经验证据表明,在块长度m大于14时,观察到的检验统计量将开始与期望值不一致(特别是已知的数据生成器,如sha-1)。
通常需要考虑的参数有:序列长度,样本大小,块大小和模板(template)。
样本大小:The issue of sample size is tied to the choice of the significance level. NIST recommends that, for these tests, the user should fix the significance level to be at least 0.001, but no larger than 0.01.
If a sample of only 100 sequences is selected, it would be rare to observe a rejection.
Thus, the sample should be on the order of the inverse of the significance level (α-1). That is, for a level of 0.001, a sample should have at least 1000 sequences.
块大小:Block sizes are dependent on the individual statistical test. In the case of Maurer's Universal Statistical test, block sizes range from 1 to 16.
一般情况下,NIST建议选择的块大小不大于log2 n,n是序列长度。
自己写个数据测试一下:
Matlab:
pop=round(rand(1000,25));
xlswrite('b',cellstr(reshape(sprintf(['''' repmat('%d',1,size(pop,2))],pop.'),[],size(pop,1))'))
写到xls表格中,然后拷贝到txt文件中
然后在ubuntu系统下按照上面的步骤测试该txt文本中的ASCII码表,最后测试完成后会出现错误:Segmentation fault (core dumped)
Segmentation fault (core dumped)多为内存不当操作造成。空指针、野指针的读写操作,数组越界访问,破坏常量等。如最近的势能图代码中的链表操作,对链表的新增和释放包括赋值等等,如出现不当操作都有可能造成程序崩溃。对每个指针声明后进行初始化为NULL是避免这个问题的好办法。排除此问题的最好办法则是调试。
ulimit为shell内建指令,可用来控制shell执行程序的资源 -a显示目前资源限制的设定。
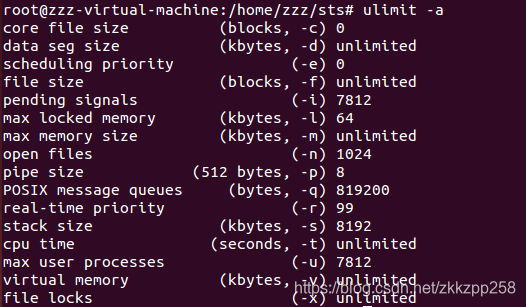
Stack size这里是8192kbytes最大上限2G
参 数:
-a 显示目前资源限制的设定。
-c <core文件上限> 设定core文件的最大值,单位为区块。
-d <数据节区大小> 程序数据节区的最大值,单位为KB。
-f <文件大小> shell所能建立的最大文件,单位为区块。
-H 设定资源的硬性限制,也就是管理员所设下的限制。
-m <内存大小> 指定可使用内存的上限,单位为KB。
-n <文件数目> 指定同一时间最多可开启的文件数。
-p <缓冲区大小> 指定管道缓冲区的大小,单位512字节。
-s <堆叠大小> 指定堆叠的上限,单位为KB。
-S 设定资源的弹性限制。
-t <CPU时间> 指定CPU使用时间的上限,单位为秒。
-u <程序数目> 用户最多可开启的程序数目。
-v <虚拟内存大小> 指定可使用的虚拟内存上限,单位为KB。
可以参看https://blog.csdn.net/zqtsx/article/details/24383755这篇文章,利用gdb等命令查看进程。
这里出现Segmentation fault大概是因为数据格式不对。
Igamc:underflow错误,网上说是因为数据量太少。在bitstreams那输入1,即只有一个比特流数据,那么通常也没办法看到没有通过的序列(假设序列是随机生成的),即proportion=1/1,因为这一组数据要么通过测试要么没通过测试。Bitstreams输入1就不会报underflow错误,或者把数据弄长些。
Bitstreams输入1的话就不会报溢出异常或者段错误。
但是bitstreams为1时没办法得到正确的结果。
自己随机写了一个32*10的随机序列,./assess 32和bitstreams=10得到结果
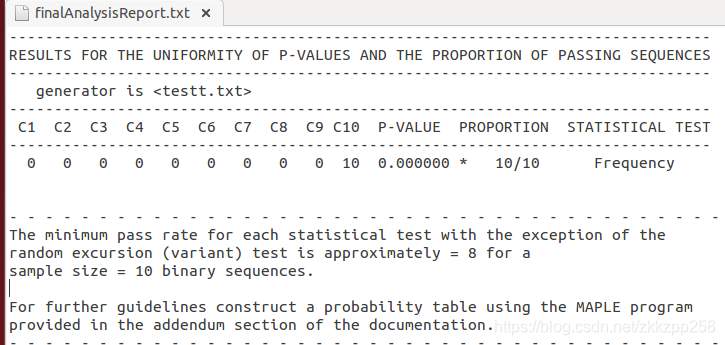
对于每个统计测试除了随机变量测试外,最小通过率接近0.8,其实结果不准确,bitstreams为1也是不准确,也没办法得到p值,按照官方说明文档要求bitstreams应该在(100,1000)的范围内。
NIST测试软件里面有伪随机数生成器,
Linear Congruential Generator (LCG),参看帮助文档115页
Quadratic Congruential Generator I (QCG-I)
Quadratic Congruential Generator II (QCG-II)
Cubic Congruential Generator II (CCG) ,参看帮助文档116页
Exclusive OR Generator (XORG)
Modular Exponentiation Generator (MODEXPG)
Secure Hash Generator (G-SHA1) ,参看帮助文档117页
Blum-Blum-Shub (BBSG)
Micali-Schnorr Generator (MSG) ,参看帮助文档118页
例如第一个线性同余生成器是通过算法生成伪随机序列,关系式是
![]()
生成的伪随机数直接进入测试,操作如下,
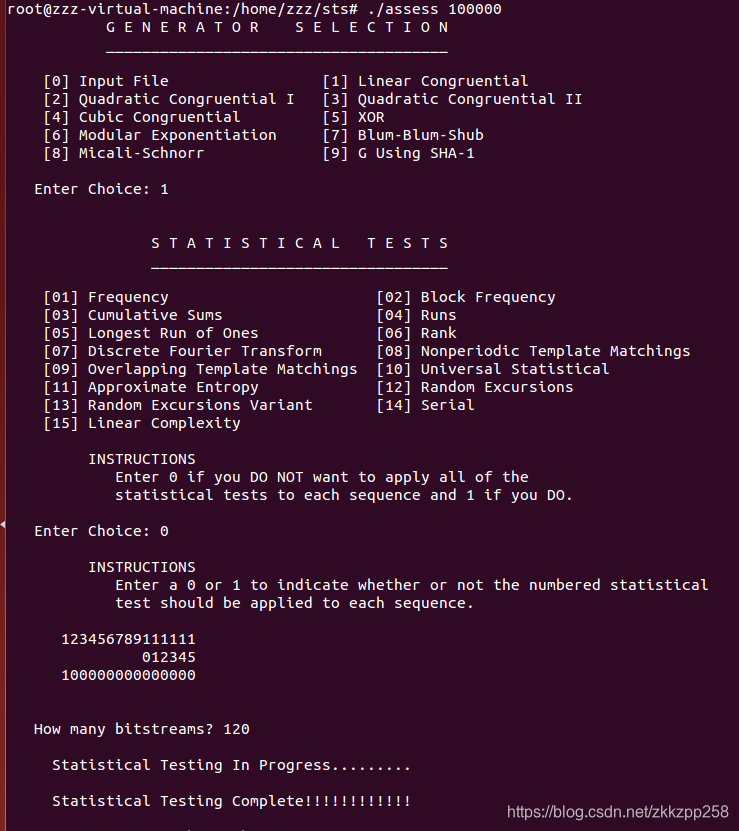
这里15个测试只选择了Frequency测试,得到结果在LCG文件夹下看,15个子文件夹代表15种测试方法的结果,里面有两个子文件
假设bitstreams=120
Results.txt包含了120次的P值的结果
stats.txt包含了120次比特流的详细结果,报错参数以及是否通过该项测试结果
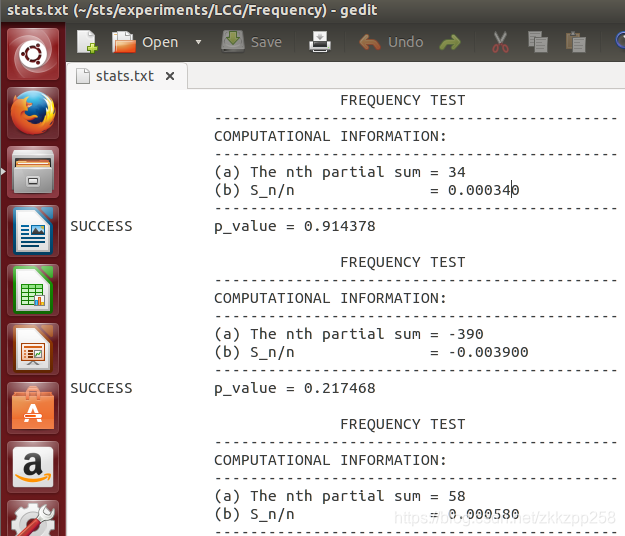
这里stats.txt是每次频率测试时的计算信息
./assess 数据长度 ,其中数据长度L=100000
特别注意:这里bitstreams*L必须小于等于文件中的数据长度,否则会报数据不够的错误。
The nth partial sum是100000个0和1序列转化为-1和1之后的和,如下面描述

拿第一组数据来检验,利用matlab的erf函数来检验
Sn=34;
n=100000;
Sobs=abs(Sn)/sqrt(n);
erfc=1-erf(Sobs/sqrt(2))
得到结果是0.9144与结果一致。
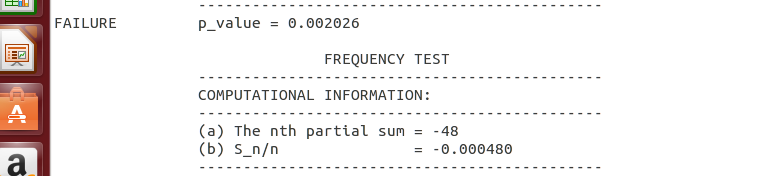
汇总的结果如下,在finalAnalysisReport.txt文件中
由上可知用自带的随机数生成的随机序列用来统计测试的结果和预想的是一致的,下面用自己写入的数据来进行测试看是否与设想完全一致。
这里面指示测试选0时虽然后面全部写000…但是仍然需要数据,如果数据不够就会报错。
下面看结果
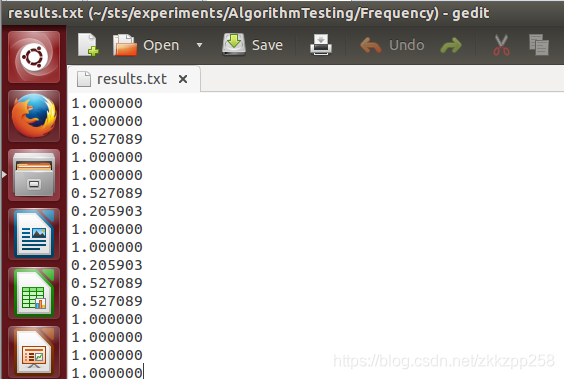
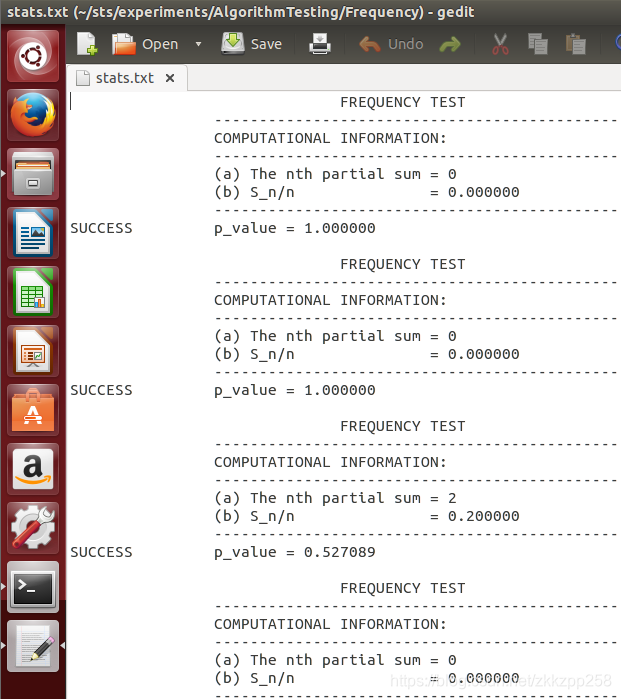
16个p值如下,
部分详细状态
原数据如下,
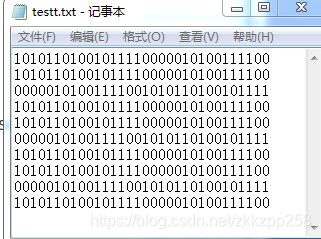
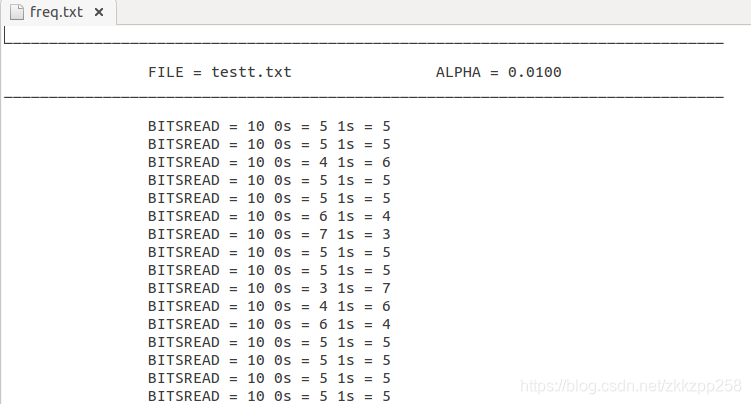
按10分数据长度,总共16组数据,后面多的数据没有读了。
第一个1010110100,总和为0,按下面计算方式p值为1

第二个1011110000,总和仍为0
第三个0101001111,总和为2,按下面计算p值为0.5271和stats.txt的结果一致

Freq.txt文件记录着0和1出现的频数
最终分析结果文件如下,16组数据全部通过频率统计测试(P值>0.01)
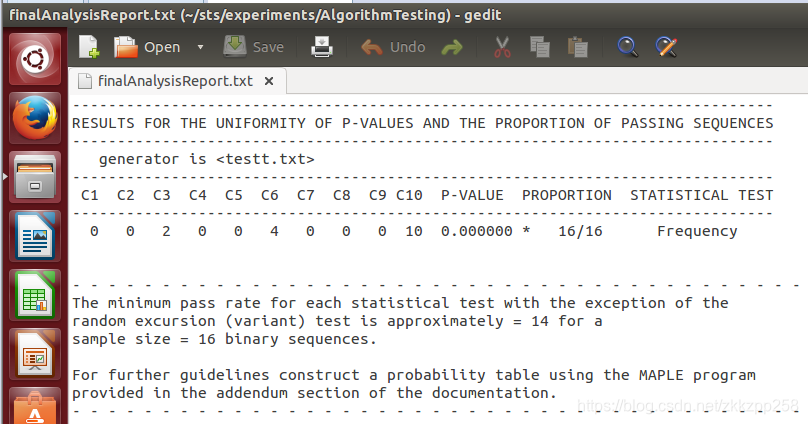
说明文档解释C1-C10是代表p值的频率(其实不太明白)。Proportion是指16组数据中通过统计测试的比率。

注:这里只是完整的验证了频率测试,如果需要进行其他验证测试只需要修改下面这个位置,
特别注意:rank测试中是测试源序列中固定长度子链间的线性依赖关系,且子链必须是32*32的矩阵类型,eg./assess 1024
Random Excursions 和 Random Excursions Variant 测试要求输入的比特数最小是1,000,000bits。
必须满足其基本要求才不会报错:Test Not Applicable.There are an insufficient number of cycle.
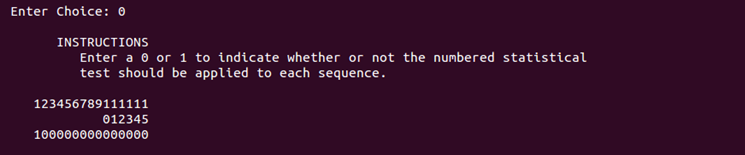
比如动向测试编号是04,那么在
12345678911111
012345
下面输入
000100000000000即可

















 3534
3534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









