









在讲表结构、树结构、图结构前,先讲一下索引。
(一)索引
就是把一个关键字与它对应的i记录相关联的过程,一个索引由若干个索引项构成,每个索引项至少应包含关键字和其对应的记录在存储器中的位置等信息。
索引按照结构可以分为:线性索引、树形索引和多级索引。
线性索引是将索引项集合组织为线性结构,也称为索引表。包括稠密索引、分块索引、倒排索引。
1.1 稠密索引
一个完美的引子:
我母亲年纪大了,记忆力不好,经常在家里找不到东西,于是她想了一个办法。她用一个小本子记录了家里所有小东西放置的位置,比如户口本放在右手床头柜下面抽屉中,针线放在电视柜中间的抽屉中,钞票放在衣柜……总之,她老人家把这些小物品的放置位置都记录在了小本子上,并且每隔一段时间还按照本子整理一遍家中的物品,用完都放回原处,这样她就几乎再没有找不到东西。从这件事情就可以看出,家中的物品尽管是无序的,但是如果有一个小本子记录,寻找起来也是非常容易的,而这小本子就是索引。
稠密索引是指在线性表中,将数据集中的每个记录对应一个索引项。
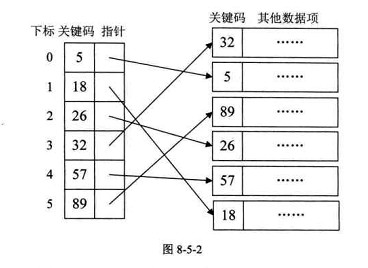
对于稠密索引这个索引表来说,索引项一定是按照关键码有序的排列。通过对索引项的查找,就可以找到丢应的结果地址,但是如果数据集非常大,比如说上亿,那也就意味着索引同样的数据规模,可能就需要反复查询内存和硬盘,性能可能反而下降了。
1.2 分块索引
引子:图书馆如何藏书
分块有序需要满足两个条件:块内无序(有序更好,代价比较大)、块间有序
对于分块有序的数据集,将每块对应一个索引项,这种索引方法叫做分块索引。
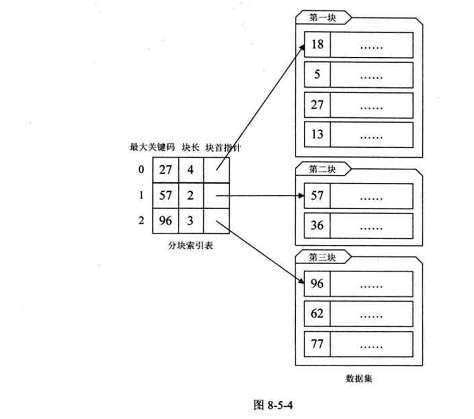
最大关键码、块长和块首指针很容易理解。
平均查找长度ASL 为 在索引表中的平均查找长度 + 在记录(数据集)中的平均查找长度。
假设 有m块,每块中共有t条记录,显然n = m * t。
故而 ASL = (m+1)/2 + (t+1)/2 = (n/t + t)/2 + 1. 上式的最小值,即n/t = t,n = t^2,则最小的ASL = n^(1/2) + 1;
课件,分块索引的效率比顺序查找o(n) 高了很多,总的来说,分块索引在兼顾了对细分块不需要有序的情况下,大大增加了整体查找的速度,所以普遍被用于数据库查找等技术的应用当中。
1.3 倒排索引
引子:搜索引擎如何进行搜索,能够在非常快的速度之下显示搜索的最优匹配内容。
索引项的结构是次关键字码和记录号表,其中记录号表存储具有相同关键字的所有记录的记录号(可以是指向记录的指针或者是该记录的主关键字),这样的索引方法就是倒排索引。
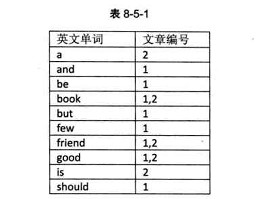
倒排索引源于实际应用中需要根据属性(或字段、次关键码)的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性来确定记录的位置,因而称为倒排索引。
倒排索引的优点显然是查找记录非常快,基本等于生成索引表后,查找时都不用去读取记录,即可以得到结果。但是它的缺点是这个记录号不定长,可多可少。
(二)图
和树的遍历相似,若从图中某顶点出发访遍图中每个顶点,且每个顶点仅访问一次,此过程称为图的遍历(Traversing Graph)。图的遍历算法是求解图的连通性问题、拓扑排序和求关键路径等算法的基础。图的遍历顺序有两种:深度优先搜索(DFS)和广度优先搜索(BFS)。它们最终都会到达所有连通的顶点。深度优先搜索通过栈来实现,而广度优先搜索通过队列来实现。 对每种搜索顺序,访问各顶点的顺序也不是唯一的。
2.1、邻接表及逆邻接表的存储方法
(1)定义
邻接表是图的一种链式存储结构。类似于树的孩子链表表示法。在邻接表中为图中每个顶点建立一个单链表,用单链表中的一个结点表示依附于该顶点的一条边(或表示以该顶点为弧尾的一条弧),称为边(或弧)结点。特征如下:
1) 为每个顶点建立一个单链表,
2) 第i个单链表中包含顶点Vi的所有邻接顶点。
把同一个顶点发出的边链接在同一个边链表中,链表的每一个结点代表一条边,叫做表结点(边结点),邻接点域adjvex保存与该边相关联的另一顶点的顶点下标 , 链域nextarc存放指向同一链表中下一个表结点的指针 ,数据域info存放边的权。边链表的表头指针存放在头结点中。头结点以顺序结构存储,其数据域da

带权图的边结点中info保存该边上的权值。
顶点 Vi 的边链表的头结点存放在下标为 i 的顶点数组中。
在邻接表的边链表中,各个边结点的链入顺序任意,视边结点输入次序而定。
设图中有 n 个顶点,e 条边,则用邻接表表示无向图时,需要 n 个顶点结点,2e 个边结点;用邻接表表示有向图时,若不考虑逆邻接表,只需 n 个顶点结点,e 个边结点。
建立邻接表的时间复杂度为O(n*e)。若顶点信息即为顶点的下标,则时间复杂度为O(n+e)。
(2)邻接表的示例及逆邻接表

在有向图的邻接表中,第 i 个链表中结点的个数是顶点Vi的出度,表结点的adjvex存储的是以当前头结点为弧尾的弦。在所有链表中其邻接点域的值为i的结点的个数是顶点vi的入度。
在有向图的逆邻接表中,第 i 个链表中结点的个数是顶点Vi 的入度,表结点的adjvex存储的是以当前头结点为弧首的弦。
如下为带权图的邻接表:

2.2 两种搜索方法
深度优先搜索:
下面图中的数字显示了深度优先搜索顶点被访问的顺序。
为了实现深度优先搜索,首先选择一个起始顶点并需要遵守三个规则:
(1) 如果可能,访问一个邻接的未访问顶点,标记它,并把它放入栈中。
(2) 当不能执行规则1时,如果栈不空,就从栈中弹出一个顶点。
(3) 如果不能执行规则1和规则2,就完成了整个搜索过程。
广度优先搜索:
在深度优先搜索中,算法表现得好像要尽快地远离起始点似的。相反,在广度优先搜索中,算法好像要尽可能地靠近起始点。它首先访问起始顶点的所有邻接点,然后再访问较远的区域。它是用队列来实现的。
下面图中的数字显示了广度优先搜索顶点被访问的顺序。
实现广度优先搜索,也要遵守三个规则:
(1) 访问下一个未来访问的邻接点,这个顶点必须是当前顶点的邻接点,标记它,并把它插入到队列中。
(2) 如果因为已经没有未访问顶点而不能执行规则1时,那么从队列头取一个顶点,并使其成为当前顶点。
(3) 如果因为队列为空而不能执行规则2,则搜索结束。
代码见 http://blog.csdn.net/andyelvis/article/details/1728378















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









