







使用zip、set、split、len 函数及应用
词频统计
一、编辑字符串
1、字符链接 — zip( )

2、创建不重复集合— set( )

3、字符串分隔 — split( )
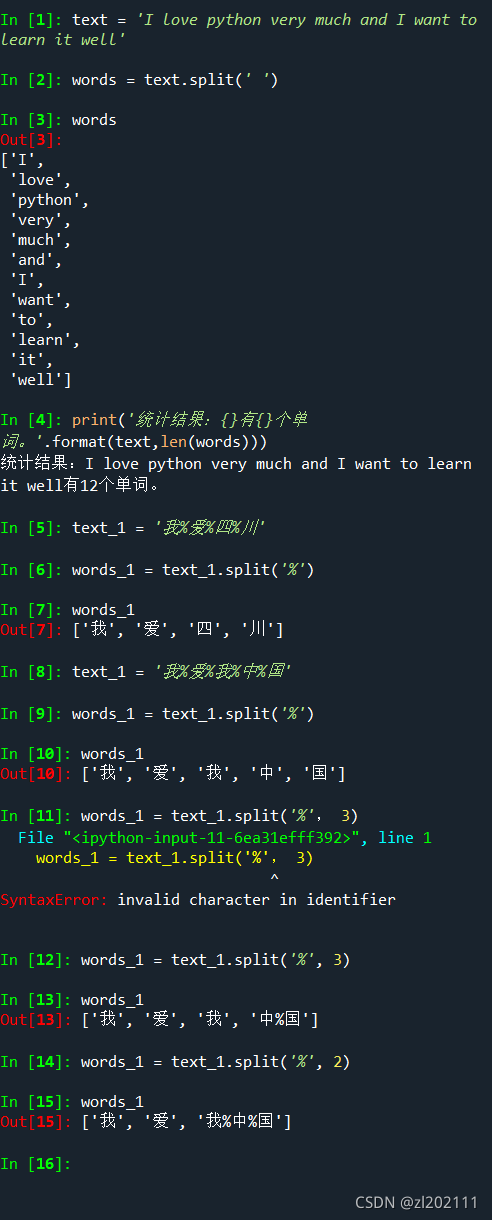
4、获取字符串长度 — len( )
- 通过len()计算字符串长度时,不区分英文、数字和汉字,都按一个字符计算。
- 采用utf-8编码的字符串,一个汉字当3个字节。
- 采用gbk编码的字符串,一个汉字当2个字节。

二、词频统计
# -*- coding: utf-8 -*-
'''
功能:词频统计
作者:zwh
日期:2021/11/21
'''
text = 'I love python I love java I learn python'
# 拆分
words = text.split(' ')
# 去重
diff_words = list(set(words))
# 统计单词个数的列表
counts = []
for i in range(len(diff_words)):
counts.append(0)
# 遍历单词列表,统计各个单词的个数
for i in range(len(words)):
for j in range(len(diff_words)):
if diff_words[j] == words[i]:
counts[j] = counts[j] + 1
# 输出统计结果
for word_count in zip(diff_words, counts):
print(word_count)
学习提示:
Details determine success or failure!
细节决定成败!















 1355
1355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









