







面试总结
上午
问题:
1. spring 使用到的设计模式
2. springboot和spring 区别
3. JVM 类加载原理,怎么加载一个冲突的jar(自定义类加载器)
4. 重写和重载方法在JVM中的体现
5. JVM 7 和8区别
6. 数据库设计范式
7. 数据库sql优化方案
8. CAP原则(分布式)–zk和eureka区别
9. Lnux操作系统常用命令,(CPU使用量查询)—内核态和用户态
10. springcloud hystrix 原理
11. redis 基本数据结构
12. 简单介绍一下GC
13. docker 镜像怎么挂载,怎么构建docker镜像,k8s使用
答案:
- spring设计模式:
简单工厂又叫做静态工厂方法(StaticFactory Method)模式,但不属于23种GOF设计模式之一。
简单工厂模式的实质是由一个工厂类根据传入的参数,动态决定应该创建哪一个产品类。
spring中的BeanFactory就是简单工厂模式的体现,根据传入一个唯一的标识来获得bean对象,但是否是在传入参数后创建还是传入参数前创建这个要根据具体情况来定。如下配置,就是在 HelloItxxz 类中创建一个 itxxzBean。
<beans>
<bean id="singletonBean" class="com.itxxz.HelloItxxz">
<constructor-arg>
<value>Hello! 这是singletonBean!<value>
</constructor-arg>
</bean>
<bean id="itxxzBean" class="com.itxxz.HelloItxxz" singleton="false">
<constructor-arg>
<value>Hello! 这是itxxzBean! <value>
</constructor-arg>
</bean>
</beans>
工厂方法(Factory Method)
通常由应用程序直接使用new创建新的对象,为了将对象的创建和使用相分离,采用工厂模式,即应用程序将对象的创建及初始化职责交给工厂对象。
一般情况下,应用程序有自己的工厂对象来创建bean.如果将应用程序自己的工厂对象交给Spring管理,那么Spring管理的就不是普通的bean,而是工厂Bean。
以工厂方法中的静态方法为例讲解一下:
import java.util.Random;
public class StaticFactoryBean {
public static Integer createRandom() {
return new Integer(new Random().nextInt());
}
}
建一个config.xm配置文件,将其纳入Spring容器来管理,需要通过factory-method指定静态方法名称
<bean id=“random”
class=“example.chapter3.StaticFactoryBean” factory-method=“createRandom” //createRandom方法必须是static的,才能找到 scope=“prototype”
/>
测试:
public static void main(String[] args) {
//调用getBean()时,返回随机数.如果没有指定factory-method,会返回StaticFactoryBean的实例,即返回工厂Bean的实例 XmlBeanFactory factory = new XmlBeanFactory(new ClassPathResource(“config.xml”)); System.out.println(“我是IT学习者创建的实例:”+factory.getBean(“random”).toString());
}
单例(Singleton)
保证一个类仅有一个实例,并提供一个访问它的全局访问点。
spring中的单例模式完成了后半句话,即提供了全局的访问点BeanFactory。但没有从构造器级别去控制单例,这是因为spring管理的是是任意的java对象。
核心提示点:Spring下默认的bean均为singleton,可以通过singleton=“true|false” 或者 scope=“?”来指定
适配器(Adapter)
在Spring的Aop中,使用的Advice(通知)来增强被代理类的功能。Spring实现这一AOP功能的原理就使用代理模式(1、JDK动态代理。2、CGLib字节码生成技术代理。)对类进行方法级别的切面增强,即,生成被代理类的代理类, 并在代理类的方法前,设置拦截器,通过执行拦截器重的内容增强了代理方法的功能,实现的面向切面编程。
Adapter类接口:Target
public interface AdvisorAdapter {
boolean supportsAdvice(Advice advice);
MethodInterceptor getInterceptor(Advisor advisor);
}
MethodBeforeAdviceAdapter类,Adapter
class MethodBeforeAdviceAdapter implements AdvisorAdapter, Serializable {
public boolean supportsAdvice(Advice advice) {
return (advice instanceof MethodBeforeAdvice);
}
public MethodInterceptor getInterceptor(Advisor advisor) {
MethodBeforeAdvice advice = (MethodBeforeAdvice) advisor.getAdvice();
return new MethodBeforeAdviceInterceptor(advice);
}
}
包装器(Decorator)
在我们的项目中遇到这样一个问题:我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。我们以往在spring和hibernate框架中总是配置一个数据源,因而sessionFactory的dataSource属性总是指向这个数据源并且恒定不变,所有DAO在使用sessionFactory的时候都是通过这个数据源访问数据库。但是现在,由于项目的需要,我们的DAO在访问sessionFactory的时候都不得不在多个数据源中不断切换,问题就出现了:如何让sessionFactory在执行数据持久化的时候,根据客户的需求能够动态切换不同的数据源?我们能不能在spring的框架下通过少量修改得到解决?是否有什么设计模式可以利用呢?
首先想到在spring的applicationContext中配置所有的dataSource。这些dataSource可能是各种不同类型的,比如不同的数据库:Oracle、SQL Server、MySQL等,也可能是不同的数据源:比如apache 提供的org.apache.commons.dbcp.BasicDataSource、spring提供的org.springframework.jndi.JndiObjectFactoryBean等。然后sessionFactory根据客户的每次请求,将dataSource属性设置成不同的数据源,以到达切换数据源的目的。
spring中用到的包装器模式在类名上有两种表现:一种是类名中含有Wrapper,另一种是类名中含有Decorator。基本上都是动态地给一个对象添加一些额外的职责。
代理(Proxy)
为其他对象提供一种代理以控制对这个对象的访问。 从结构上来看和Decorator模式类似,但Proxy是控制,更像是一种对功能的限制,而Decorator是增加职责。
spring的Proxy模式在aop中有体现,比如JdkDynamicAopProxy和Cglib2AopProxy。
观察者(Observer)
定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
spring中Observer模式常用的地方是listener的实现。如ApplicationListener。
策略(Strategy)
定义一系列的算法,把它们一个个封装起来,并且使它们可相互替换。本模式使得算法可独立于使用它的客户而变化。
spring中在实例化对象的时候用到Strategy模式
在SimpleInstantiationStrategy中有如下代码说明了策略模式的使用情况:
模板方法(Template Method)
定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。Template Method使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
Template Method模式一般是需要继承的。这里想要探讨另一种对Template Method的理解。spring中的JdbcTemplate,在用这个类时并不想去继承这个类,因为这个类的方法太多,但是我们还是想用到JdbcTemplate已有的稳定的、公用的数据库连接,那么我们怎么办呢?我们可以把变化的东西抽出来作为一个参数传入JdbcTemplate的方法中。但是变化的东西是一段代码,而且这段代码会用到JdbcTemplate中的变量。怎么办?那我们就用回调对象吧。在这个回调对象中定义一个操纵JdbcTemplate中变量的方法,我们去实现这个方法,就把变化的东西集中到这里了。然后我们再传入这个回调对象到JdbcTemplate,从而完成了调用。这可能是Template Method不需要继承的另一种实现方式吧。
以下是一个具体的例子:
JdbcTemplate中的execute方法

JdbcTemplate执行execute方法

- spring和springboot区别
Spring MVC提供了一种轻度耦合的方式来开发web应用。它是Spring的一个模块,是一个web框架。通过Dispatcher Servlet, ModelAndView 和 View Resolver,开发web应用变得很容易。解决的问题领域是网站应用程序或者服务开发——URL路由、Session、模板引擎、静态Web资源等等。
Spring Boot实现了自动配置,降低了项目搭建的复杂度。它主要是为了解决使用Spring框架需要进行大量的配置太麻烦的问题,所以它并不是用来替代Spring的解决方案,而是和Spring框架紧密结合用于提升Spring开发者体验的工具。同时它集成了大量常用的第三方库配置(例如Jackson, JDBC, Mongo, Redis, Mail等等),Spring Boot应用中这些第三方库几乎可以零配置的开箱即用(out-of-the-box)。
Spring Boot只是承载者,辅助你简化项目搭建过程的。如果承载的是WEB项目,使用Spring MVC作为MVC框架,那么工作流程和你上面描述的是完全一样的,因为这部分工作是Spring MVC做的而不是Spring Boot
springboot自动配置实现原理----@EnableAutoConfiguration
@Enable*注释并不是SpringBoot新发明的注释,Spring 3框架就引入了这些注释,用这些注释替代XML配置文件。比如:
@EnableTransactionManagement注释,它能够声明事务管理
@EnableWebMvc注释,它能启用Spring MVC
@EnableScheduling注释,它可以初始化一个调度器。
这些注释事实上都是简单的配置,通过@Import注释导入。
/**
* The location to look for factories.
* <p>Can be present in multiple JAR files.
*/
public static final String FACTORIES_RESOURCE_LOCATION = "META-INF/spring.factories";
//spring.factories---样例---类全路径
# Auto Configure
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
org.springframework.boot.devtools.autoconfigure.DevToolsDataSourceAutoConfiguration,\
org.springframework.boot.devtools.autoconfigure.LocalDevToolsAutoConfiguration,\
org.springframework.boot.devtools.autoconfigure.RemoteDevToolsAutoConfiguration
附:springboot启动流程

3. jvm类加载,自定义类加载器加载冲突jar
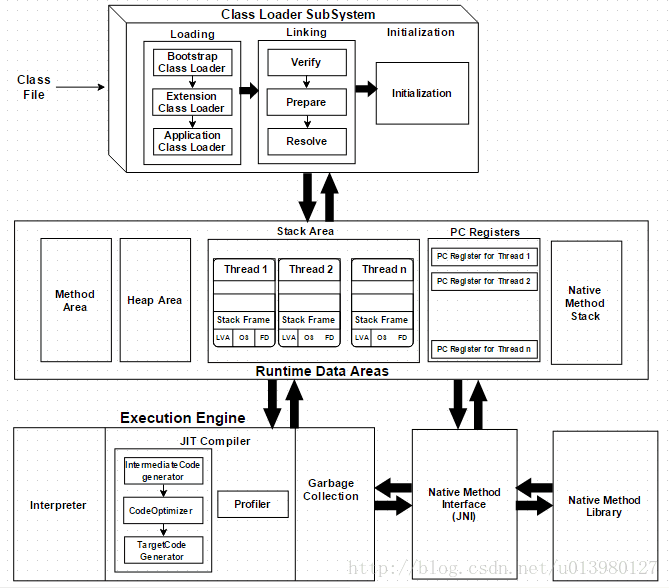
类从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期包括:加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)7个阶段。其中准备、验证、解析3个部分统称为连接(Linking)。
加载
在加载阶段(可以参考java.lang.ClassLoader的loadClass()方法),虚拟机需要完成以下3件事情:
通过一个类的全限定名来获取定义此类的二进制字节流(并没有指明要从一个Class文件中获取,可以从其他渠道,譬如:网络、动态生成、数据库等);
将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构;
在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口;
加载阶段和连接阶段(Linking)的部分内容(如一部分字节码文件格式验证动作)是交叉进行的,加载阶段尚未完成,连接阶段可能已经开始,但这些夹在加载阶段之中进行的动作,仍然属于连接阶段的内容,这两个阶段的开始时间仍然保持着固定的先后顺序。
验证
验证是连接阶段的第一步,这一阶段的目的是为了确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
验证阶段大致会完成4个阶段的检验动作:
文件格式验证:验证字节流是否符合Class文件格式的规范;例如:是否以魔术0xCAFEBABE开头、主次版本号是否在当前虚拟机的处理范围之内、常量池中的常量是否有不被支持的类型。
元数据验证:对字节码描述的信息进行语义分析(注意:对比javac编译阶段的语义分析),以保证其描述的信息符合Java语言规范的要求;例如:这个类是否有父类,除了java.lang.Object之外。
字节码验证:通过数据流和控制流分析,确定程序语义是合法的、符合逻辑的。
符号引用验证:确保解析动作能正确执行。
验证阶段是非常重要的,但不是必须的,它对程序运行期没有影响,如果所引用的类经过反复验证,那么可以考虑采用-Xverifynone参数来关闭大部分的类验证措施,以缩短虚拟机类加载的时间。
准备
准备阶段是正式为类变量分配内存并设置类变量初始值的阶段,这些变量所使用的内存都将在方法区中进行分配。这时候进行内存分配的仅包括类变量(被static修饰的变量),而不包括实例变量,实例变量将会在对象实例化时随着对象一起分配在堆中。其次,这里所说的初始值“通常情况”下是数据类型的零值,假设一个类变量的定义为:
public static int value=123;
那变量value在准备阶段过后的初始值为0而不是123.因为这时候尚未开始执行任何java方法,而把value赋值为123的putstatic指令是程序被编译后,存放于类构造器()方法之中,所以把value赋值为123的动作将在初始化阶段才会执行。
至于“特殊情况”是指:public static final int value=123,即当类字段的字段属性是ConstantValue时,会在准备阶段初始化为指定的值,所以标注为final之后,value的值在准备阶段初始化为123而非0.
解析
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符7类符号引用进行。
初始化
类初始化阶段是类加载过程的最后一步,到了初始化阶段,才真正开始执行类中定义的java程序代码。在准备极端,变量已经付过一次系统要求的初始值,而在初始化阶段,则根据程序猿通过程序制定的主管计划去初始化类变量和其他资源,或者说:初始化阶段是执行类构造器()方法的过程.
()方法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块static{}中的语句合并产生的,编译器收集的顺序是由语句在源文件中出现的顺序所决定的,静态语句块只能访问到定义在静态语句块之前的变量,定义在它之后的变量,在前面的静态语句块可以赋值,但是不能访问。
类加载器与双亲委派模型
(1) Bootstrap ClassLoader : 将存放于<JAVA_HOME>\lib目录中的,或者被-Xbootclasspath参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如 rt.jar 名字不符合的类库即使放在lib目录中也不会被加载)类库加载到虚拟机内存中。启动类加载器无法被Java程序直接引用
(2) Extension ClassLoader : 将<JAVA_HOME>\lib\ext目录下的,或者被java.ext.dirs系统变量所指定的路径中的所有类库加载。开发者可以直接使用扩展类加载器。
(3) Application ClassLoader : 负责加载用户类路径(ClassPath)上所指定的类库,开发者可直接使用。

工作过程:如果一个类加载器接收到了类加载的请求,它首先把这个请求委托给他的父类加载器去完成,每个层次的类加载器都是如此,因此所有的加载请求都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它在搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。
好处:java类随着它的类加载器一起具备了一种带有优先级的层次关系。例如类java.lang.Object,它存放在rt.jar中,无论哪个类加载器要加载这个类,最终都会委派给启动类加载器进行加载,因此Object类在程序的各种类加载器环境中都是同一个类。相反,如果用户自己写了一个名为java.lang.Object的类,并放在程序的Classpath中,那系统中将会出现多个不同的Object类,java类型体系中最基础的行为也无法保证,应用程序也会变得一片混乱。
Java 自定义 ClassLoader 实现隔离运行不同版本jar包的方式
有时候我们需要在一个 Project 中运行多个不同版本的 jar 包,以应对不同集群的版本或其它的问题。如果这个时候选择在同一个项目中实现这样的功能,那么通常只能选择更低版本的 jar 包,因为它们通常是向下兼容的,但是这样也往往会失去新版本的一些特性或功能,所以我们需要以扩展的方式引入这些 jar 包,并通过隔离执行,来实现版本的强制对应。
自定义ClassLoader 解决jar冲突
- 自定义 ClassLoader,使其 Parent = null,避免其使用系统自带的 ClassLoader 加载 Class。
- 在调用相应版本的方法前,更改当前线程的 ContextClassLoader,避免扩展包的依赖包通过Thread.currentThread().getContextClassLoader()获取到非自定义的 ClassLoader 进行类加载
- 通过反射获取 Method 时,如果参数为自定义的类型,一定要使用自定义的 ClassLoader 加载参数获取 Class,然后在获取 Method,同时参数也必须转化为使用自定义的 ClassLoade 加载的类型(不同 ClassLoader 加载的同一个类不相等)
- 重写和重载方法在JVM中的体现(Jvm怎么识别重载重写方法)
静态类型 和 实际类型
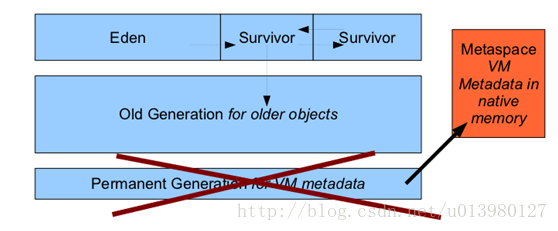
- JVM 7 和8区别
永久代为什么被移出HotSpot JVM了?
6. 数据库设计范式
第一范式
1、每一列属性都是不可再分的属性值,确保每一列的原子性
2、两列的属性相近或相似或一样,尽量合并属性一样的列,确保不产生冗余数据。
第二范式
每一行的数据只能与其中一列相关,即一行数据只做一件事。只要数据列中出现数据重复,就要把表拆分开来。
第三范式
数据不能存在传递关系,即没个属性都跟主键有直接关系而不是间接关系。像:a–>b–>c 属性之间含有这样的关系,是不符合第三范式的。
比如Student表(学号,姓名,年龄,性别,所在院校,院校地址,院校电话)
这样一个表结构,就存在上述关系。 学号–> 所在院校 --> (院校地址,院校电话)
这样的表结构,我们应该拆开来,如下。
(学号,姓名,年龄,性别,所在院校)–(所在院校,院校地址,院校电话)
最后:
三大范式只是一般设计数据库的基本理念,可以建立冗余较小、结构合理的数据库。如果有特殊情况,当然要特殊对待,数据库设计最重要的是看需求跟性能,需求>性能>表结构。所以不能一味的去追求范式建立数据库。
-
数据库sql优化方案
1.对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,
最好不要给数据库留NULL,尽可能的使用 NOT NULL填充数据库
3.应尽量避免在 where 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描。
4.应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描
5.in 和 not in 也要慎用,否则会导致全表扫描
对于连续的数值,能用 between 就不要用 in 了
很多时候用 exists 代替 in 是一个好的选择
应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描
总之,尽量避免全表扫描,能使用索引就使用索引,查询条件 小范围在前 -
CAP原则(分布式)–zk和eureka区别
CAP原则又称CAP定理,指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可兼得
分布式系统的CAP理论:理论首先把分布式系统中的三个特性进行了如下归纳:
● 一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
● 可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
● 分区容错性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
P是必须的,所以取舍就是 CP or AP
| Feature | Eureka | Zookeeper |
|---|---|---|
| 服务健康检查 | 可配支持 | (弱)长连接,keepalive |
| CAP | AP | CP |
| watch支持(客户端观察到服务提供者变化) | 支持 long polling/大部分增量 | 支持 |
| 自我保护 | 支持 | - |
| 客户端缓存 | 支持 | - |
| 自身集群的监控 | metrics | - |
Eureka支持健康检查,自我保护等
Zookeeper为CP设计,Eureka为AP设计。作为服务发现产品,可用性优先级较高,一致性的特点并不重要,宁可返回错误的数据,也比不反回结果要好得多。
服务列表变更Zookeeper服务端会有通知,Eureka则通过长轮询来实现,Eureka未来会实现watch机制
- Lnux操作系统常用命令,(CPU使用量查询)—内核态和用户态
top vmstat
内核态和用户态:

如上图所示,从宏观上来看,Linux操作系统的体系架构分为用户态和内核态(或者用户空间和内核)。内核从本质上看是一种软件——控制计算机的硬件资源,并提供上层应用程序运行的环境。用户态即上层应用程序的活动空间,应用程序的执行必须依托于内核提供的资源,包括CPU资源、存储资源、I/O资源等。为了使上层应用能够访问到这些资源,内核必须为上层应用提供访问的接口:即系统调用。
系统调用是操作系统的最小功能单位,这些系统调用根据不同的应用场景可以进行扩展和裁剪,现在各种版本的Unix实现都提供了不同数量的系统调用,如Linux的不同版本提供了240-260个系统调用,FreeBSD大约提供了320个(reference:UNIX环境高级编程)。我们可以把系统调用看成是一种不能再化简的操作(类似于原子操作,但是不同概念),有人把它比作一个汉字的一个“笔画”,而一个“汉字”就代表一个上层应用,我觉得这个比喻非常贴切。因此,有时候如果要实现一个完整的汉字(给某个变量分配内存空间),就必须调用很多的系统调用。如果从实现者(程序员)的角度来看,这势必会加重程序员的负担,良好的程序设计方法是:重视上层的业务逻辑操作,而尽可能避免底层复杂的实现细节。库函数正是为了将程序员从复杂的细节中解脱出来而提出的一种有效方法。它实现对系统调用的封装,将简单的业务逻辑接口呈现给用户,方便用户调用,从这个角度上看,库函数就像是组成汉字的“偏旁”。这样的一种组成方式极大增强了程序设计的灵活性,对于简单的操作,我们可以直接调用系统调用来访问资源,如“人”,对于复杂操作,我们借助于库函数来实现,如“仁”。显然,这样的库函数依据不同的标准也可以有不同的实现版本,如ISO C 标准库,POSIX标准库等。
Shell是一个特殊的应用程序,俗称命令行,本质上是一个命令解释器,它下通系统调用,上通各种应用,通常充当着一种“胶水”的角色,来连接各个小功能程序,让不同程序能够以一个清晰的接口协同工作,从而增强各个程序的功能。同时,Shell是可编程的,它可以执行符合Shell语法的文本,这样的文本称为Shell脚本,通常短短的几行Shell脚本就可以实现一个非常大的功能,原因就是这些Shell语句通常都对系统调用做了一层封装。为了方便用户和系统交互,一般,一个Shell对应一个终端,终端是一个硬件设备,呈现给用户的是一个图形化窗口。我们可以通过这个窗口输入或者输出文本。这个文本直接传递给shell进行分析解释,然后执行。
- springcloud hystrix 原理
SF上有个文章讲的很好 hystrix 原理 - redis 基本数据结构
一:字符串类型string
二:散列类型hash
三:列表类型(list)
四:集合类型(set)
五:有序集合类型 - 简单介绍一下GC
新生代GC,老年代GC,GC算法 - docker 镜像怎么挂载,怎么构建docker镜像,k8s使用
docker commit
Dockerfile docker build
K8S不会使用,以后补充知识
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









