






一.IO流概述
1.IO流的概述:
IO流用来处理设备之间的数据传输
Java对数据的操作是通过流的方式
Java用于操作流的对象都在IO包中
2.IO流的分类:
A:按数据流向分:输入流 读入数据
输出流 写出数据
B:按数据类型分:字节流 :可以读写任何类型的文件(音频 视频 文本文件等)
字节流又可以分为:字节输入流(InputStream 读)和字节输出流(OutputStream 写)
字节流的抽象基类是 InputStream ,OutputStream。
字符流: 只能读写文本文件
字符流又可以分为:字符输入流(Reader 读)和字符输出流(Writer 写)
字符流的抽象基类是 Reader , Writer。
注:字符流和字节流的4个抽象基类派生出来的子类名字都是以父类名字为结尾。
比如文件输出流和文件输入流的名字分别为FileoutputStream和InputStream
问:什么情况下使用哪种流呢?
答:如果数据所在的文件通过windows自带的记事本打开并能读懂里面的内容,就用字符流。其他用字节流。
如果你什么都不知道,就用字节流
字节流的关系:

二.FileOutputStream
1.文件输出流,写出数据
A: 构造方法
FileOutputStream(File file)//可以用文件名来封装字节输出流
FileOutputStream(String name)//可以通过字符串来封装字节输出流
B:案例演示
FileOutputStream写出数据
注意事项:
创建字节输出流对象了做了几件事情?
a:调用系统资源创建a.txt文件
b:创建了一个字节输出流对象
c:把对象指向这个文件
问:为什么一定要close()?
a: 通知系统释放关于管理所创建文件的资源
b: 让Io流对象变成垃圾,等待垃圾回收器对其回收
c:当字节输入流为空时,就要进行非空判断,不然会出现空指针异常
2.FileOutputStream的三个write()方法
A:public void write(int b):写一个字节 超过一个字节 砍掉前面的字节
B:public void write(byte[] b):写一个字节数组
C:public void write(byte[] b,int off,int len):写一个字节数组的一部分
案例:使用以上方法
public class Test1 {
public static void main(String[] args) throws IOException {
FileOutputStream fos=new FileOutputStream(new File("a.txt"));
fos.write(98);
byte[]bytes="Hello,everyone".getBytes();
fos.write(bytes);
fos.write(bytes,0,2);
//用完一定要注意释放资源
fos.close();
}
}在此工程下创建了文件a.txt
内容:
bHello,everyoneHeA换行: windows下的换行符只用是 \r\n
Linux \n
Mac \r
在我们使用过程中,用\r\n
B追加:将构造函数中的参数默认的为false改为true就可以完成追加
案例:实现FileOutputStream写出数据实现换行和追加写入
public class Test2 {
public static void main(String[] args)throws IOException{
//如果你再运行一遍,会覆盖原来的值
FileOutputStream fos=new FileOutputStream(new File("b.txt"));
fos.write(100);
//那么在实际中,我们会采取在构造文件时,将默认的false改为true既可以实现拼接
//追加内容
FileOutputStream fos1=new FileOutputStream(new File("c.txt"),true);
fos1.write(97);
fos1.write("\r\n".getBytes());
fos1.close();
}
}dc.txt内容:
a
a注2:当我们在写入部分字节汉数组时,要注意区分字的编码格式,不同的编码格式,则所占的字节数不同。
GBK编码,一个汉字占2个字节,
UTF-8编码,一个汉字占3个字节,
案例A:”春天来了,你好”请输出前两个汉字。
我使用的是UTF-8,因为包含头,不包含尾,所以范围为0-6,格式如下:
byte[] bytes1 = "春天来了,你好".getBytes();
//GBK编码一般汉字是2个字节,UTF-8编码,一个汉字是3个字节
//获取前两个汉字,包含头,不包含尾
fos.write(bytes1,0,6);测试类:
public class Test4 {
public static void main(String[] args) {
FileOutputStream file=null;
try {
// file=new FileOutputStream(new File("love.txt"));
// file=new FileOutputStream("qq.txt");
file.write("你好".getBytes());
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
file.close();
} catch (IOException e) {
e.printStackTrace();
}catch (NullPointerException e){
//NullPointerException是由catch捕捉到的
e.printStackTrace();
}
}
}
}
结果:
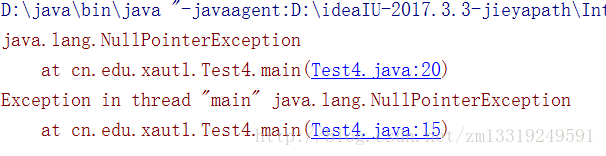
注:我们发现在15行和20都会出现空指针异常,在用FileoutputStream写出数据时,我们必须要处理异常,一般处理异常有两种方式,一种是直接抛出去让JVM处理,但是我们一般不采用这种方式,而是用自己的方法,就是用try{}catch{}来实现,tryl里边大多写的是可能发生异常的代码,而将可能发生的异常写在catch中,让catch去捕捉。一般情况都会打印堆栈信息。
三.FileInputStream
1.FileInputStream读取数据一次一个字节
方法: int read():一次读取一个字节,返回值为int型
如果没有数据返回的就是-1
注:每次都要释放资源
案例:读取数据一次一个字节来复制文件
public class Test3 {
public static void main(String[] args) throws Exception {
FileInputStream fis=new FileInputStream(new File("D://aa.exe"));
FileOutputStream fos=new FileOutputStream(new File("E://aa.exe"));
int len=0;
while ((len=fis.read())!=-1){
fos.write(len);
}
//释放资源
fis.close();
fos.close();
}
}
结果:发现E盘下出现aa.exe
2.FileInputStream读取数据一次一个字节数组
方法: byte[] bytes = new byte[1024] ;//定义一个缓冲区
int len = 0 ;// 作用: 记录读取到的有效的字节个数
while((len = fis.read(bytes)) != -1){
System.out.print(new String(bytes , 0 , len)); }
案例:因为用一次一个字节来读取文件,这样速度很慢,所以我们采用一次读取一个字节数组,这个字节数组相当于一个缓冲区,自己可以定义它的大小,可以定义为1024,或者1024的倍数。
分析过程:a: 创建字节输入流对象和字节输出流对象
b: 频繁的读写操作
c: 释放资源
public class Test4 {
public static void main(String[] args) throws IOException {
//我们可以看出一次复制一个字节文件这个比较耗时
//因此我们采用一次读取一个字节素组来复制文件
FileInputStream fis=new FileInputStream(new File("D://aa.exe"));
FileOutputStream fos=new FileOutputStream(new File("E://aa.exe"));
//创建一个数据缓冲区
byte[]bytes=new byte[1024];
int len=0;
//获取当前时间
Instant strat=Instant.now();
int i=0;
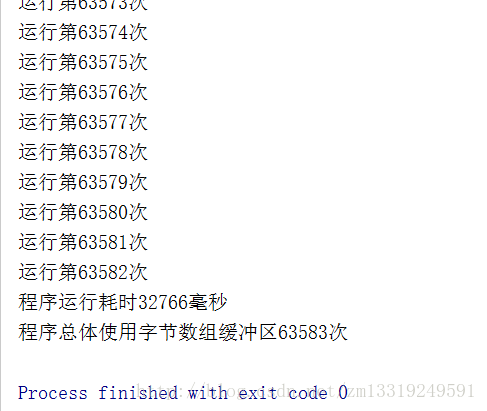
while((len=fis.read(bytes))!=-1){
System.out.println("运行第"+i+"次");
fos.write(bytes,0,len);
//刷新流
fos.flush();
i++;
}
//获取结束的当前时间
Instant end=Instant.now();
Duration between = Duration.between(strat, end);
long l = between.toMillis();
System.out.println("程序运行耗时"+l+"毫秒");
System.out.println("程序总体使用字节数组缓冲区"+i+"次");
}
}
四.BufferedOutputStream和BufferedInputStream
1.A:BufferedOutputStream和BufferedInputStream为字节缓冲区流,在上述的例子中,我们不难发现,一次读写一个字节数组比一次读写一个字节要速度快的多,这是因为使用了数组的缘故,java本身也设计的时候也考虑到缓冲区的思想,因此,提供了字符缓冲区流。
B:BufferedOutputStream的构造方法(高效的字节输出流)
BufferedOutputStream(OutputStream out)//因为OutputStream是字节输出流的顶层父类,是一个抽象基类,因此必须传递它的子类对象
方法作用:创建一个新的缓冲区输出流,以将数据写入指定的底层输出流
C:BufferedInputStream的构造方法(高效的字节输入流)
BufferedInputStream(InputStream in)//因为InputStream是字节输入流的顶层父类,是一个抽象基类,因此必须传递它的子类对象
方法作用:创建一个BufferedInputStream,并保存其参数,即输入流 in,以便将来使用。
案例1:复制一个视频文件来比较使用了字节缓冲区流是否使程序运行加快
测试类:
public class Test1 {
public static void main(String[] args) throws IOException {
// BufferedInputStream BufferedOutputStream 底层引入了这个缓冲区的思想
//定义程序的开始时间
Instant start = Instant.now();
//test();//消耗时间为3059毫秒
test1();//消耗时间为2398毫秒
//记录程序结束的时间
Instant end = Instant.now();
Duration between = Duration.between(start, end);
long l = between.toMillis();
System.out.println("消耗时间为" + l + "毫秒");
}
private static void test1() throws IOException {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("D://abc.exe"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("E://abc.exe"));
//定义一个字节数组
byte[] bytes = new byte[1024];
int len = 0;
while ((len = bis.read(bytes)) != -1) {
bos.write(bytes, 0, len);
bos.flush();
}
bis.close();
bos.close();
}
private static void test() throws IOException {
FileInputStream fis = new FileInputStream("D://abc.exe");
FileOutputStream fos = new FileOutputStream("E://abc.exe");
//定义一个字节数组
byte[] bytes = new byte[1024];
//记录读取到的有效的字节个数
int len = 0;
//一次读取一个字节数组
while ((len = fis.read(bytes)) != -1) {
fos.write(bytes, 0, len);
//刷新
fos.flush();
}
fis.close();
fos.close();
}
}
案例2:将一个文件夹下的所有文件及文件夹都复制到另外一个盘下。
分析:首先我选择将D://ccc文件复制到E://ccc
文件夹下边有文件也有文件夹,因此我们必须把文件的复制和文件夹的复制分开,创建为两个方法,一个复制文件夹,一个复制文件,在文件夹里去判断是否为文件是则继续调用自己,不是则调用文件复制方法,将文件复制到该目录下。利用递归的方法去实现。
A:首先必须先把D://ccc单级文件夹复制到E://ccc
a:封装源文件夹
b:封装目标文件夹
c:如果发现E盘没有该文件夹就创建该文件夹
d:复制文件夹,自己创建一个复制文件的方法,每当需要复制文件夹时就去调用该方法
B:创建一个复制文件的方法
a:先将该文件夹下的所有文件夹和文件找出,存储到一个文件数组中
b:去遍历这个文件数组,进行判断,如果是文件则调用文件复制的方法,把该复制到目标文件夹下,如果是文件夹,则进行递归调用,只是要修改目标文件夹的位置,目标文件夹在原目标文件夹的下一层,文件夹的名称为源文件夹的名称相同,因此可以进行字符串拼接的方法,重新封装一个新的目标文件夹,然后在目标文件夹下创建该文件夹
c:继续进行递归调用复制文件夹的方法
C:创建一个复制文件的方法
a:先读取原目标文件
b:封装新的目标文件,利用字符串拼接的方法,重新构建一个新的目标文件目录,在原目标目录的基础上再添加一个现原文件那夹的名称即可
c:为了提高运行的速度,因此一般都会采用一次访问一个字节的方法来复制文件
d:注意进行文件的刷新和资源释放,自己利用try catch方法来处理异常,一般不采用去直接抛给JVM去处理异常
分析完成之后,下边就是具体的实现类
测试类:
public class Test {
public static void main(String[] args) {
//复制单级文件夹
//封装原文件目录
File afile=new File("D://ccc");
//封装目标文件目录
File dfile=new File("E://ccc");
//如果目标目录不存在就自己创建一个目标目录
if(!dfile.exists()){
dfile.mkdirs();
}
copyfile(afile,dfile);
}
private static void copyfile(File afile, File dfile) {
File[] files = afile.listFiles();
for(File f:files){
if(f.isFile()){
//如果是文件,开始复制
copysinglefile(f,dfile);
}else {
//不是目标文件,可能是文件夹
//递归调用
File bbfile=new File(dfile+"\\"+f.getName());
//该文件夹如果不存在就重新创建
if(!bbfile.exists()){
bbfile.mkdirs();
}
copyfile(f,bbfile);
}
}
}
private static void copysinglefile(File f, File dfile) {
try{
BufferedInputStream bis=new BufferedInputStream(new FileInputStream(f));
BufferedOutputStream bos=new BufferedOutputStream(new FileOutputStream(dfile+"\\"+f.getName()));
byte[]bytes=new byte[1024];
int len=0;
while ((len=bis.read(bytes))!=-1){
bos.write(bytes,0,len);
bos.flush();
}
bis.close();
bos.close();
}catch (IOException e){
e.printStackTrace();
}
}
}
结果:
D:\ccc\a
E:\ccc\a
D:\ccc\a\d
E:\ccc\a\d
D:\ccc\b
E:\ccc\b
D:\ccc\b\aa
E:\ccc\b\aa















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









