







ElasticSearch 内置了分词器,如标准分词器、简单分词器、空白词器等。但这些分词器对我们最常使用的中文并不友好,不能按我们的语言习惯进行分词。
测试ElasticSearch 内置分词器:
post localhost:9200/_analyze
参数:
{"text":"测试分词器"}

IK分词器
ik分词器是一个标准的中文分词器。可以根据定义的字典对域进行分词,并且支持用户配置自己的字典,所以它除了可以按通用的习惯分词外,还可以定制化分词。
ik分词器是一个插件包,可以用插件的方式将它接入到ES。
一、安装
1.1 下载
点击这里,进入GitHub下载IK分词器
注:下载的包一定要和 ElasticSearch 的版本一致。点击右侧的 Releases ,选择版本

下载第一个,不要下载源码包

1.2 安装
以windows为例,在ES目录的plugins目录下创建ik子目录,然后下载的zip包解压的内容移到里面,最后重启ES,界面可以看到加载的ik插件

重启过程若出现闪退情况,请检查:
1、版本号是否匹配
2、包是否下载错
3、下载的zip包是否忘记删除,也在项目里
ik分词器有2种模式
- ik_smart 最粗粒度的拆分,比如会将“测试分词器”拆分为测试、分词器。
- ik_max_word 最细粒度的拆分,比如会将“测试分词器”拆分为“测试、分词器、分词、器等词语。
( ik_max_word 比 ik_smart 划分的词条更多,这就是它们为什么叫做最细粒度和最粗粒度。)
测试(ik_max_word)
post http://localhost:9200/_analyze
参数
{"text":"测试分词器","analyzer":"ik_max_word"}

总结:
- 针对文档添加索引库时,最好使用ik_max_work分词,能够获得当前文档最多的词条
- 针对搜索条件如果要分词的话,最好使用ik_smart分词,能够更贴近用户的需求.
自定义字典
举例:如果想让分词器把 “测试分词器试试” 分为 ‘测试分词器、测试、分词器、试试’
打开 …\elasticsearch-8.1.2\plugins\ik\config\IKAnalyzer.cfg.xml
可以看到有2个配置 ext_dict 和 ext_stopwords。分别是扩展和停用字典

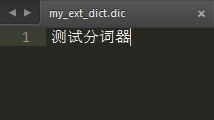
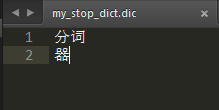
参照默认的dic文件,在config目录新建 my_ext_dict.dic 和 my_stop_dict.dic
- my_ext_dict.dic文件里 加入想要的分词
- my_stop_dict.dic文件里 加入舍弃的分词
然后配置到 IKAnalyzer.cfg.xml

重启ES,启动日志可以看到加载了我们的字典

效果:
注:配置重启后,若发现没有效果,检查下my_ext_dict.dic和 my_stop_dict.dic文件的编码格式是否UTF-8
映射
常用映射类型
1、text
1)analyzer
通过analyzer属性指定分词器。
下边指定name的字段类型为text,使用ik分词器的ik_max_word分词模式。
"name": {
"type": "text",
"analyzer":"ik_max_word"
}
analyzer是指在索引和搜索都使用ik_max_word,如果想单独定义搜索时使用的分词器则可以通search_analyzer属性。
ik分词器建议是索引时使用ik_max_word将搜索内容进行细粒度分词,搜索时使用ik_smart提高搜索精确性:
"name": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
},
"pic": {
"type": "text",
"index": false
}
2)index
通过index属性指定是否索引。
默认为index=true,即要进行索引,只有进行索引才可以从索引库搜索到;
若不需要搜索的则需要指定index=false。
2、keyword关键字字段
keyword字段为关键字字段,通常搜索keyword是按照整体搜索,所以创建keyword字段的索引时是不进行分词的,是需要全部匹配;















 8260
8260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









