







spark lisenter的设计方案?目的是啥?能干什么?怎么和其它组件解耦合?
需求背景
任务监控的需求:人对于未知的、不可见的事务总是充满恐惧。对于集群中运行的任务,希望获取运行过程中的状态信息,用户追踪、可视化运行过程中的细节;
作业优化:程序优化是很正常的事情,例如运行时间过程我们会优化性能,消费数据堆积我们会考虑增加并行度等;运行的中间状态数据可以用于反向优化作业。
设计目标
异步执行;可扩展;松耦合
设计方案
无论什么问题,第一时间想到的应该是:有没有现成的方法论,前人有没有总结出什么可用的经验或者范式。在软件工程领域,经验或者范式以“设计模式”来定义和规范,打开任何优秀的框架源码,可以看到许许多多的设计模式。设计模式来自于实际生产中的总结,最终也应该应用到实际生产中去促进可扩展、松耦合软件的生产。监控系统在实现上是有通用的设计模式作为参考的,这个设计模式就是:监听者模式。
设计模式-监听者模式:
定义了主题和观察者之间一对多依赖,当主题状态发生变化时,依赖的所有观察者将会收到通知。对于消息的通知,有两种实现方式:主题push和观察者pull。

对于push模式,主题中有三个不可缺失的方法:register、remove、push。register方法,用于注册观察者,一个主题下可以注册N个观察者;remove用于除名注册的观察者;push方法用于将消息推送给观察者,该方法中会遍历注册上来的观察者列表,调用观察者的回调函数将消息回写给观察者。

对于pull模式,消息的获取由观察者主动去pull,因此观察者需要有主题的引用,观察者调用主题的pull方法获取到主题中的状态数据。为了验证是否是一个合法的观察者,因此观察者也是需要向主题中进行注册的。
思考:
spark是一个复杂的系统,可以划分出很多主题,例如:application的启动和完成,task的开始和完成,stage的提交和完成,rdd的持久化和非持久化,blockManager的增加和移除,环境变量的更新等等。这些主题如何集中管理?是否需要抽象出N个主题?怎样做才能减少混乱做到最优?
先来看下spark中的解决方案,spark为了解决复杂类型的事件订阅和监听,采用的LisenterBus的设计,总体上还是观察者模式,是push模式的实现,LisenterBus会主动推送消息给监听者。
整体设计如下:
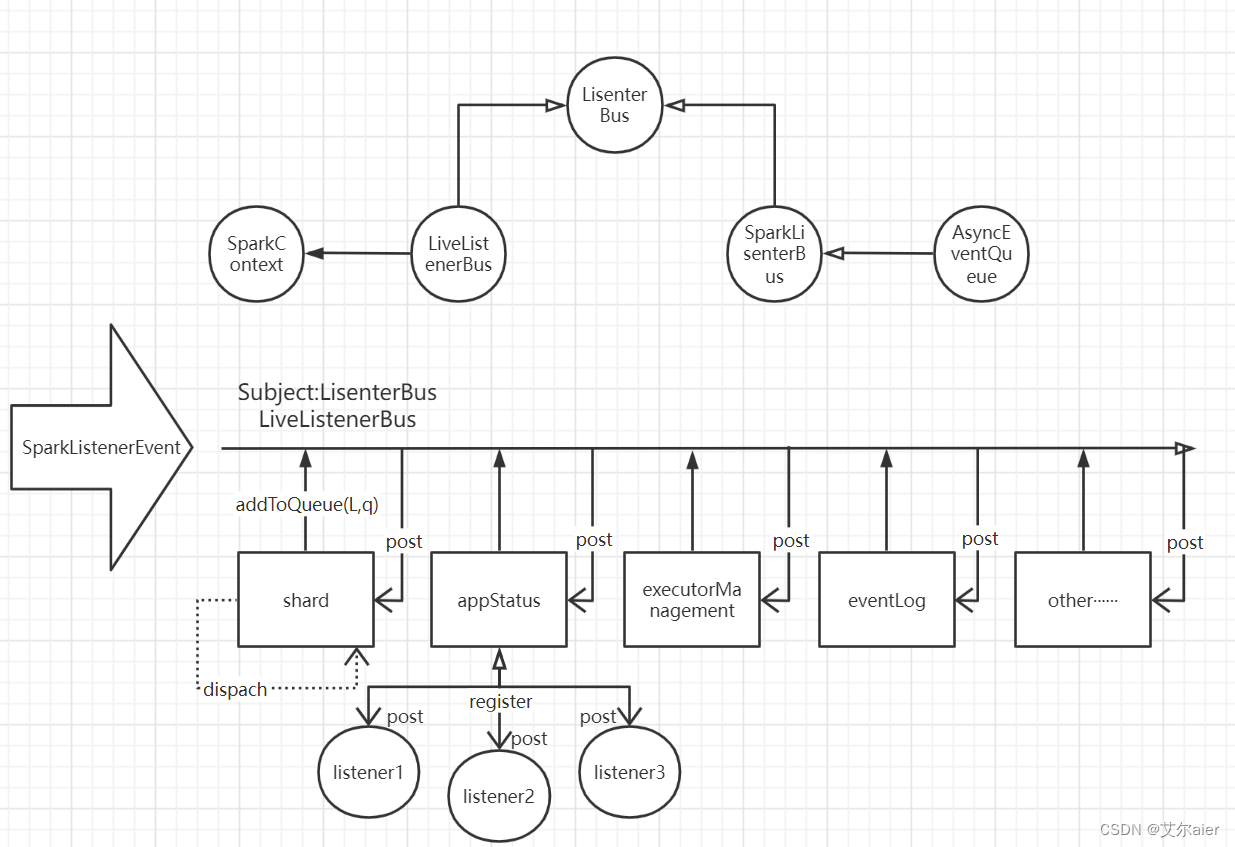
Spark默认的LisenterBus实现是LiveListenerBus,其中的queues属性即是观察者模式中的Subject主体集合,通过name对应一个具体的SyncEventQueue实现类,该类是真正的主题。即上图中的shard、appStatus、executorManagement、eventLog等。提供了addListener注册监听器、removeListener移除监听器、postToAll发送消息等方法。
对于多主题的管理,提供了addToQueue(L,q)方法,L表示Lisenter,q表示主题(对应SyncEventQueue实现类,即Subject主题),该方法先判断是否存在主题,不存在,需要先创建,然后将L放入集合中,完成监听者在主题中的注册。
具体的监听者是SparkLisenterInterface接口的实现类,该接口中定义了很多回调方法,当特定的事件到达Subject的消息队列时,怎样断定这个消息发给哪个监听者处理呢?必须知道,Spark的LisenterBus收到一个事件时,会调用post方法,将该事件发给所有的Subject,而监听只会处理特定的事件,怎么办呢?这必须要借助模式匹配了!!
下面以精简的步骤来厘清主要的数据流向:
- 外部事件向LisenterBus发送SparkLisenterEvent事件
- LisenterBus调用post方法,向所有的Subject发送收到的Event事件
- Subject自身拥有独立线程,执行dispach方法,遍历注册到自身的Lisenters集合,调用Lisenter上的回调方法,而默认队列AsyncEventQueue实现了SparkListenerBus接口,该接口中重写了doPostEvent方法,这个方法有什么特殊之处呢?将match case模式匹配中的Event调用Lisenter的相关方法进行处理,而这些方法是我们编写Lisenter需要重写的方法。
何时启动消息总线呢?Spark编程的总入口是SparkContext,在SparkContext中可以发现实例化的代码。
_listenerBus = new LiveListenerBus(_conf)总线启动后,就可以轻松处理Spark内部的各种事件了!
应用:拿到spark运行的内部数据,可以进行很多的应用了,例如:spark web上各个任务运行进度实时展示;spark sql的执行计划等。当然也可以将这些内部的数据拿到,写到自己的业务系统进行相关的应用,如:数据血缘分析。
应用:数据血缘关系管理
1.实现QueryExecutionListener接口
class Lisener extends QueryExecutionListener {
override def onSuccess(funcName: String, qe: QueryExecution, durationNs: Long): Unit = {
println(qe.logical.toJSON)
println(qe.analyzed.toJSON)
print(qe.executedPlan.toJSON)
}
override def onFailure(funcName: String, qe: QueryExecution, exception: Exception): Unit = {
println(qe.logical.toJSON)
println(qe.executedPlan.toJSON)
}
}2.使用
spark-submit --master yarn --conf 'spark.sql.queryExecutionListeners=xxxx.Lisener' --class xxxx.listener xxx.jar
拿到执行计划数据结构之后,通过解析数据结果,能够拿到原表、目标表、原属性和目标属性计算映射关系等,通过这中方式能够完善spark相关数据血缘管理。
















 864
864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











