







最近在学习solr时候,碰到一个问题,就是如果采用默认的分词器,会将每个字都分割成一个词组进行索引
比如:长沙市 会被分词为 “长”,“沙”,“市”,这样就达不到我想要的效果
例如:
<field name="name" type="text_general" indexed="true" stored="true"/>这个是默认的分词器
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>结果:
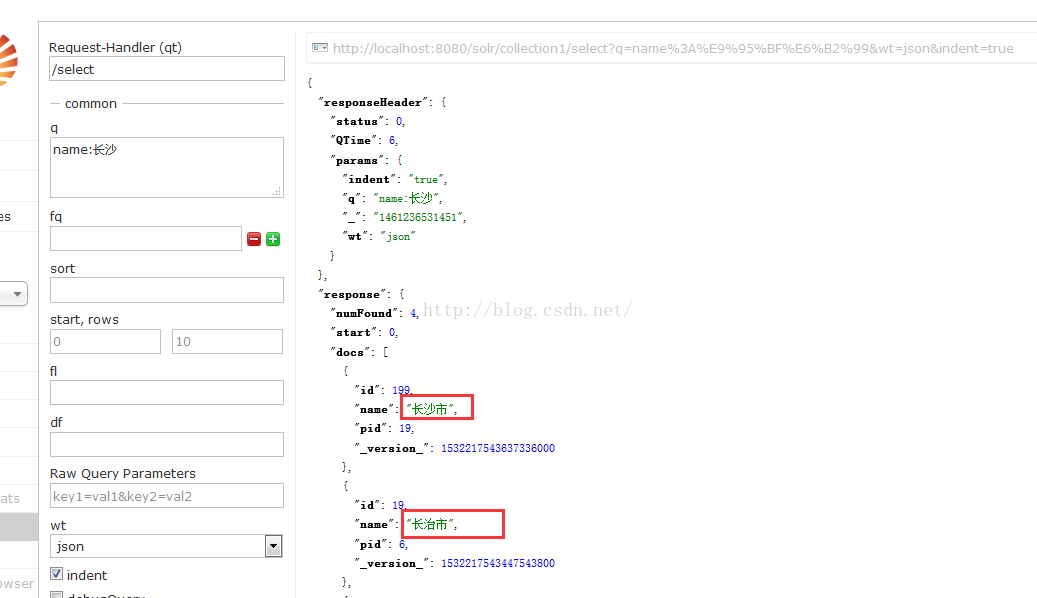
对每个字都进行了分词
所以这里我们需要手动加入分词功能,我这里采用的IKAnalyzer,这里分词,会进行词组分词 “长沙”,“市” 这样
在schema.xml文件中加入
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType> <field name="name" type="text_ik" indexed="true" stored="true"/>然后重启
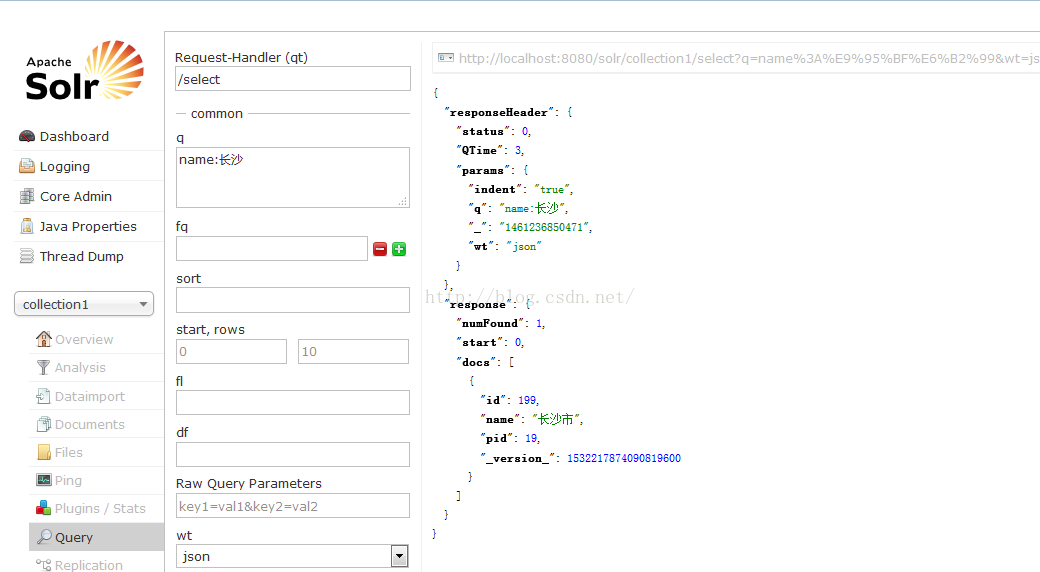
这样效果就达到了,这里和lucene的差不多滴!















 106
106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









