









使用边界标识法实现简单分配器
前言
前一篇我们已经了解了边界标识算法和数据结构,其实边界标识法还是比较复杂的,它的难点在于对C的使用的淋漓尽致,以及复杂的逻辑关系。所以我们还需要多思考,多体会才能领悟个中精髓,其实我昨天在学习那个小例子的时候由一瞬间感觉如果用C++实现可能更方便,所以再此决定等这几篇完成,就使用C++实现一个小小的实例。
言归正传,我们今天需要看一个用C使用边界标识法实现的简单分配器,这个分配器主要是首先重内存申请一大片内存,然后根据程序的调用来分配空间的有点像实现一个malloc/free 函数。
学习目标
1.通过这个实例,加深边界标识法的理解。
2.对这个实例从效率,多线程等角度进行测试。
3.为后边伙伴算法打基础。
PS:个人还是觉得大学学习两件事:一个看天,一个看自己。
1.看天是根据自己的性格特点,兴趣爱好学习。
2.看自己处了努力学习外,还有练就总结的能力,大学的课废话太多。(又跑偏了)
__START
块的结构
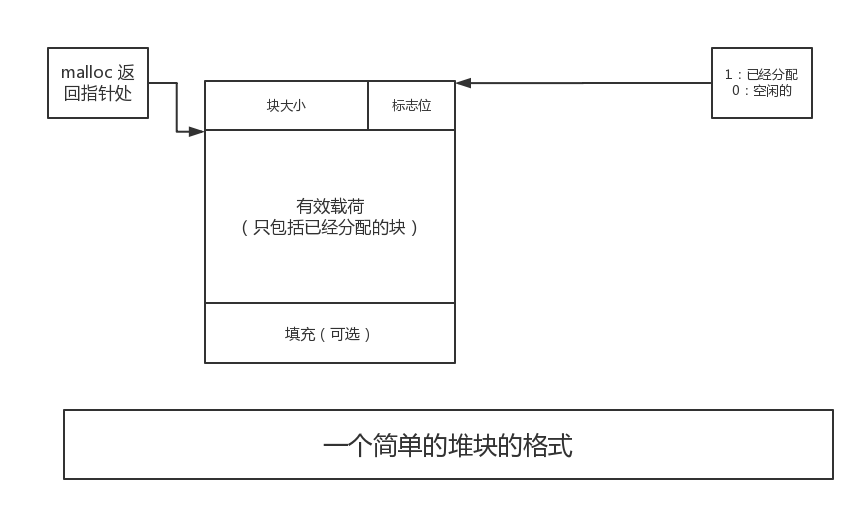
如图所示
基本上一个堆块的大小就是这个样子的,并不陌生呢,我前边已经介绍过了,基本都是由头部,内存块,尾部组成的。
这里需要说明的是:
标志位已经不再是一个int了,而是3位,因为内存对齐的关系我们需要按照4/8字节对齐,假设这里按照4字节对齐,那么就是0~31个位,我们释放低3位来作为状态的标识。
举个例子:
假设我们有一个已经分配的块大小为24(0x18) 字节。那么它的头部是
0x00000018 | 0x1 = 0x00000019
再加设我们有一个没有分配的块大小为40字节。那么它的头部是
0x00000028 | 0x00 = 0x00000028
在有效载荷后边由一块填充块,这个块是不使用的,因为现在用不上不代表以后都用不上,所以我们要为可持续发展做长远的考虑。
安置已分配的块
放置策略
首次适配 :每一次都从头开始给它匹配一个可以使用的块。
下次适配 :每次从上次分配的块后+1 开始匹配一个块。
最佳适配 :每次遍历整个链表,然后找到一个我们认为合适的块给它。
这些和我们之前搞的东西很像。
申请额外的空间
当我们的预申请的对空间不够用时,我们就可以调用sbrk 函数来提升堆的大小。
基本思路纵向导图

我们使用系统调用mmap( )函数从内存中请求一片100MB 的大小的空间当作我们的对空间,初始化一个序言块这个主要是为了便与我们后边的边界计算。
分步解析内存管理系统
0.我们的变量和一些宏处理
#include<stdio.h>
#include<assert.h>
#include<unistd.h>
#include<sys/mman.h>
#include<string.h>
#include<errno.h>
#include<fcntl.h>
#define MAX_HEAP (100 *(1 << 20))//100MB 大小
#define MINSIZE 2
#define WSIZE 4 //一个字的大小4KB
#define DSIZE 8 //双字大小8KB
#define CHUNKSIZE (1<<12) //初始空闲堆的大小和默认的大小 4MB
#define MAX(x,y) ((x) > (y)? (x):(y))
#define PACK(size,alloc) ((size) | (alloc))
#define GET(p) (*(unsigned int *)(p))
#define PUT(p,val) (*(unsigned int *)(p) = (val))
#define GET_SIZE(p) (GET(p) & ~0x7) //从头部或脚部返回大小
#define GET_ALLOC(p) (GET(p) & 0x1) //返回分配位
#define HDRP(bp) ((char *)(bp) - WSIZE) //返回头部
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE) //返回脚部指针
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE))) //返回下一个指针
#define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE))) //返回上一个指针
static char *heap_listp = 0;
static char *heap;
static char *mem_brk;
static char *mem_max_addr;
static char *flist_free = NULL; //指向释放的链表
static char *heap_tailp = NULL; //指向最后一块
static int count = 0; //指示链表中块的数目
1.内存空间申请
void mem_init(void){
//从内存里拿出一个100MB 的空间来作为我们的堆空间
int dev_zero = open("/dev/zero",O_RDWR);
heap = mmap((void *)0x800000000,MAX_HEAP,PROT_WRITE,
MAP_PRIVATE,dev_zero,0);
mem_max_addr = heap + MAX_HEAP;
mem_brk = heap;
}效果如图:

成功从内存条申请了100MB 的空间
2.初始化我们的堆空间,建立序言块。
int mm_init(void){ //初始化序言块
if((heap_listp = mem_sbrk(4*WSIZE)) == (void *)-1)
// brk :0x800000010
return -1;
init_free_list();
PUT(heap_listp,0);
PUT(heap_listp + (1*WSIZE),PACK(DSIZE, 1));
PUT(heap_listp + (2*WSIZE),PACK(DSIZE, 1));
PUT(heap_listp + (3*WSIZE),PACK(0,1));
heap_listp += (2*WSIZE); //heap_listp::0x800000008
count++;
//链表中现在只有一个序言块
//保持对齐并且,根据需求请求更多的堆存储器,初始化堆空间4KB
return -1;
return 0;
}
效果如图:

现在我们可以看到各个位置已经初始化完毕。
4.堆扩展函数以及新增空闲块函数
static void *extend_heap(size_t words){
//用一个新的空块扩展堆
char *bp;
size_t size;
size = (words % 2)?(words + 1)*WSIZE : words *WSIZE;
//保持和2的倍数对齐,内存对齐
if((long)(bp = mem_sbrk(size)) == -1)
return NULL;
PUT(HDRP(bp),PACK(size,0)); //设置头和尾的信息
PUT(FTRP(bp),PACK(size,0));
PUT(HDRP(NEXT_BLKP(bp)),PACK(0,1)); //并且设置下一个块的头
return bp;
}
void *mem_sbrk(int incr){
//申请额外的堆空间就是malloc 的分配,分配主要的工作函数
char *old_brk = mem_brk;
if((incr < 0) || ((mem_brk + incr) > mem_max_addr)){
//超过大小或者超过我们的堆空间大小都会报错
printf("out of memory\n");
//brk 来返回堆的尾部地址
return (void *)-1;
}
mem_brk += incr;
return (void *)old_brk;
}5.分配函数malloc( )
void *malloc(size_t size){
size_t asize; //建议块的大小,根据size 且需要对齐
size_t extendsize;
char *bp;
if(size == 0)
return NULL;
if(size <= DSIZE)
asize = 2*DSIZE;
else
asize = DSIZE*((size + (DSIZE) + (DSIZE-1)) / DSIZE);
//设置最小的块为16 其中留了8字节为头部和脚部
if((bp = find_fit(asize)) != NULL){
//如果找到可以分配的块就分配
place(bp,asize);
return bp;
}
extendsize = MAX(asize,CHUNKSIZE);
//对比我们的初始化堆和需要分配的大小,向我们的堆空间申请额外的空间
if((bp = extend_heap(extendsize/WSIZE)) == NULL)
return NULL;
place(bp,asize);
return bp;
}
static void place(void *bp,size_t asize){
//分配函数,根据需求分配相应的块,并把它放置到,我们的堆链后
size_t csize = GET_SIZE(HDRP(bp));
//csize 得到这个块的大小
if((csize - asize) >= (2*DSIZE)){
//如果分配减去需求大于最小块的大小,进行分割
PUT(HDRP(bp),PACK(asize,1)); //设置头和尾
PUT(FTRP(bp),PACK(asize,1));
bp = NEXT_BLKP(bp);
//下一个块就是尾减一
PUT(HDRP(bp),PACK(csize-asize,0));
//设置下一个块的属性,大小为剩余块的大小
PUT(FTRP(bp),PACK(csize-asize,0));
}else{
//如果剩余块的大小,小于一个标准块那就将整个块分配出去
PUT(HDRP(bp),PACK(csize,1));
PUT(HDRP(bp),PACK(csize,1));
}
}
6.释放函数free 以及合并函数coalesce
void free(void *bp){
//回收我们的内存,有用有还,再借不难
size_t size = GET_SIZE(HDRP(bp));
PUT(HDRP(bp),PACK(size,0));
PUT(FTRP(bp),PACK(size,0));
coalesce(bp);
}
static void *coalesce(void *bp){ //块的合并算法
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp));
if(prev_alloc && next_alloc){ //当两边都被占用,直接释放不需要做任何事
return bp;
}else if(prev_alloc && !next_alloc){
//前一个被占用,后一个空闲,直接合并后边的
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp),PACK(size,0));
PUT(FTRP(bp),PACK(size,0));
}else if(!prev_alloc && next_alloc ){
//前一个空闲,后一个被占用,直接合并前一个
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp),PACK(size,0));
PUT(HDRP(PREV_BLKP(bp)),PACK(size,0));
bp = PREV_BLKP(bp);
}else{
//前后都是空闲,直接全部合并
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)),PACK(size,0));
PUT(FTRP(NEXT_BLKP(bp)),PACK(size,0));
bp = PREV_BLKP(bp);
}
return bp;
}
匹配算法这里主要是首次适配
static void *find_fit(size_t asize){ //首次适配
char *bp;
int len = 0;
for(bp = heap_listp;GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp),len++){
if(!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp)))){
//寻找第一个可以匹配的块
return (void *)bp;
}
}
return NULL;
}这里都是简单的实现,我们也可以使用下次适配,和最佳适配。
下次适配很简单:
加上:
heap_listp = bp; //每次让它指向最后分配的位置就好,下次从这里匹配最佳适配:这里就是改一下for语句就好,读者可以自行实现。但是说明一点,最佳匹配在边界标识法体现的并不强烈,可以说它其实是伙伴算法的特性。
8.其他测试函数
static void print(){ //测试函数
printf("the heap :%p\n heap_brk:%p \n heap_max_addr:%p\n",heap,mem_brk,mem_max_addr);
printf("the heap_listp:%p the flist_free is %p \n",heap_listp,flist_free);
}
static void print_blcok(void *bp){
printf("the heap_prev:%p heap_next is %p \n",PREV_BLKP(bp),NEXT_BLKP(bp));
}
static void print_show(void){
char *temp;
int a = 10;
for(temp = heap_listp; temp != mem_brk;temp = NEXT_BLKP(temp),a--)
{
printf("the start is %p \n ",temp);
printf("the flag is %d\n",GET_ALLOC(temp));
}
}
测试与运行
1.测试
int main(){
char *p;
char *q;
char *t;
mem_init();
mm_init();
print();
p = (char *)malloc(sizeof(char)*10);
q = (char *)malloc(sizeof(char) *10);
t = (char *)malloc(sizeof(char) *10);
print_show();
free(p);
free(q);
free(t);
print();
print_show();
}运行结果:
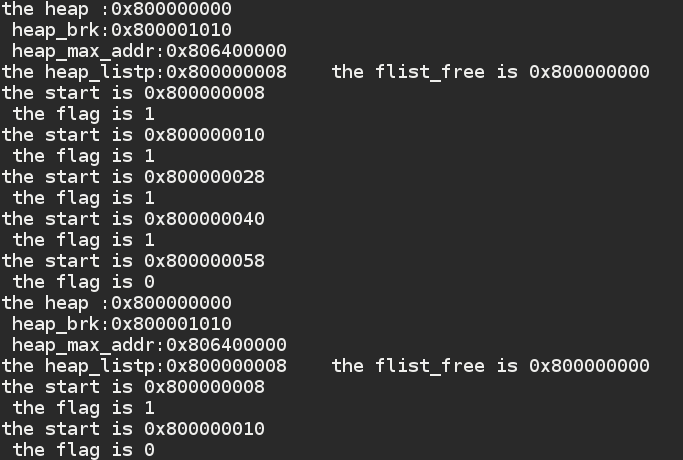
可以看到,第一个序言块在分配前后都是1。
计算他们的大小:24 这是对的,首先我们需求10 但是按照8字节对齐,给他们分配16字节大小,然后再加上头和尾各4字节。所以一共:
16 + 8 = 24 字节
并且我们发现,在释放后,我们的程序已经他们合并了。
2.多线程测试
void *one(void *arg){
while(1){
char *p;
p = (char *)malloc(sizeof(char)*10);
free(p);
printf("i am the one thread\n");
sleep(1);
}
}
void *two(void *arg){
while(1){
char *q;
q = (char *)malloc(sizeof(char)*10);
free(q);
printf("i am the two thread\n");
sleep(1);
}
}
int main(){
mem_init();
mm_init();
pthread_t thid1;
pthread_t thid2;
int err;
err = pthread_create(&thid1,NULL,one,NULL);
err = pthread_create(&thid2,NULL,two,NULL);
while(1){
sleep(1);
}
}
运行结果如图所示:
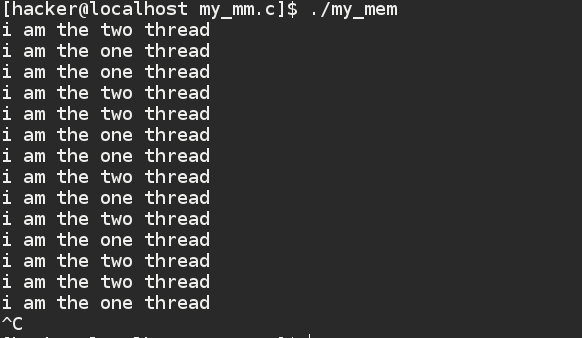
虽然看到这里在多线程的时候可以执行,但是确实线程极不安全的,最简单的来说多个线程一个锁都没有用到,这怎么可能支持多线程,所以不能支持多线程,后续我们还会对这个分配器进行改造,甚至是重构!
my_malloc VS sys_malloc 和系统的malloc函数对比
int main(){
//根据多次分配释放来看看效率
int i = 10000000;
while(i > 0){
char *p;
p = (char *)malloc(sizeof(char)*10);
free(p);
i--;
}
return 0;
}
效果如图
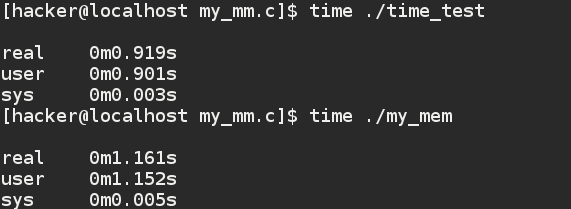
我被系统完爆。。。.。。.。.。。。。.。
当然这只是一个简单的实现,以后再做优化。
预告:
下来:
内核内存,伙伴算法。















 1570
1570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









