







一、Hadoop架构
任何一个程序都可以被分为两个逻辑部分:程序逻辑本身和它操作的数据。数据本身需要大量的存储空间,而基于这些数据的计算或操作会消耗cpu,内存和存储空间。
因此Hadoop作为一个开源的分布式框架,自然需要考虑的也是两个方面:如何实现数据的分布data distribution,以及计算的分布computation distribution。
hadoop使用了master/slave node的架构,即主控服务器和从服务器。首先master将数据分散到各个slave node上,然后根据move-code-to-data的原则,将计算也分散到各个slave node上。同时master知道所有数据的具体存储位置,以及所有计算任务的执行情况,从而可以动态的调度–每台机器的作用并不固定– 由其上正在运行的daemon而定–其上运行了什么daemon,机器就具有了什么功能。
关于数据的进程:
NameNode 和 DataNode
NameNode是 HDFS (hadoop file system)的主控服务器。它指挥slave的DataNode守护进程执行低level的IO任务。It keeps track of how your files are broken down into file blocks, which nodes store those blocks, and the overall health of the distributed filesystem.
Secondary NameNode 并非NameNode的backup,而是部分承担了NameNode的工作。因此NameNode是单节点的(single point of failure)。在超大规模hadoop系统中,Namenode往往负载很重,容易失败。因此facebook,cloudera都修改了hadoop架构来减少系统失败几率。
关于计算的进程:
JobTracker 和 TaskTracker
和用于storage的进程一样,用于计算的进程也使用了master/slave架构。The JobTracker is the master overseeing the overall execution of a MapReduce job and the TaskTrackers manage the execution of individual tasks on each slave node. Once you submit your code to your cluster, the JobTracker determines the execution plan by determining which files to process, assigns nodes to different tasks, and monitors all
tasks as they’re running. Should a task fail, the JobTracker will automatically relaunch the task, possibly on a different node, up to a predefined limit of retries. 同时JobTracker还负责集群资源管理,如是否有新节点加入集群,是否有节点离开等等。
Each TaskTracker is responsible for executing the individual tasks that the JobTracker assigns. Although there is a single TaskTracker per slave node, each TaskTracker can spawn multiple JVMs to handle many map or reduce tasks in parallel.
TaskTracker甚至可以同时执行mapper和reducer。
综合以上两个方面,一个典型的hadoop cluster结构如下:
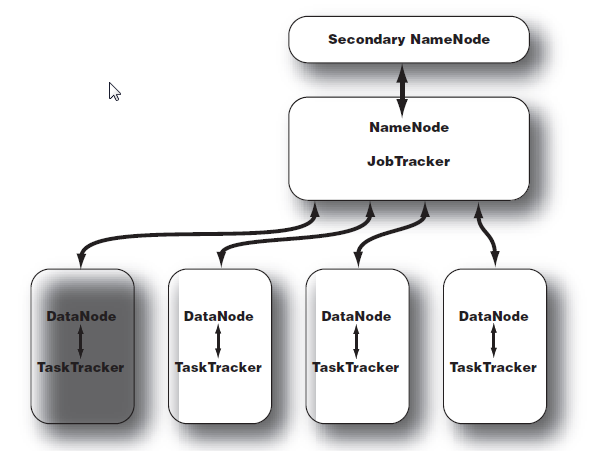
可以看到NameNode既是HDFS的master,也是JobTracker的master。同时由于NameNode在内存中管理HDFS数据,因此运行压力大,单节点,扩展性差。据报道Hadoop1.0能管理的集群上线为4000~5000台机器。
二、数据结构,数据存储,数据操作
Hadoop采用MapReduce计算范型。如果希望将项目迁移到Hadoop集群运行,则必须使用Hadoop提供的API重写整个项目。这带来三方面的影响:
- MapReduce很适合处理非结构数据。
MapReduce处理key/value pair形式的数据。不同的k/v数据之间逻辑上没有什么关系,因此大文件很容易被分片并分散到集群中去。同时支持非结构数据,就可以将几乎所有项目迁移到Hadoop。而不像关系型数据库那样,对数据有严格的要求。 - 在用Hadoop的API重写传统项目时会发现,Hadoop只有map和reduce两种语义。也就是说,任何数据操作,如join等,都需要被转换为map和reduce函数。因此复杂任务转换为MapReduce任务的开发效率比较低。
- Hadoop的底层存储系统只能是HDFS,而不能使用普通文件系统或其他文件系统。因为只有使用了HDFS,才能自动对数据进行分发和处理。而操作HDFS上的文件需要调用特定的API,从而又增加了开发成本。
三、编程思想:move-code-to-data philosophy
这是一个思想,即computation应该发生在存储data的地方。其实这不是Hadoop的设计思想,而是MapReduce计算范型的思想。
四: 执行任务:MapReduce
hadoop是基于MapReduce架构,但单个MapReduce job当然不足以应付各种应用的复杂需求。要实现大规模的复杂数据处理,hadoop实现了多MapReduce job的复杂组合,主要是:
- Chaining MapReduce jobs in a sequence. 即hadoop可实现按顺序调用多个MapReduce jobs。这样数据可以做成像pipeline一样的一级级的处理。
- Chaining MapReduce jobs in a dependency. 即每个MapReduce jobs之间可有相互的依存关系。例如首先使用两个job读入两种数据,之后将他们join。hadoop方便的实现了,在job1和job2都完全前等待,都完成后自动开始执行下一个job,即joining。
- Chaining preprocessing and postprocessing steps。 在每一个job前后执行预处理和后处理。
- Bloom filter。通常是一个大小固定的特殊数据对象,因此可以被放进内存中而不必担心内存溢出。Bloom filter可以在不要求高准确率的应用中,实现用小数据量估算结果的功能。因此适用于缓存数据等应用。
另外,Bloom filter and implement it with a mapper that keeps state information across records.















 1098
1098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









