







MapReduce其实是两个分离的阶段:map和reduce。首先看一个简单的例子:
现需要计算1w篇文章中字母‘w’的数量。这些文章以键值对(key/value)的形式存储(表一):
| DocumentID(key) | DocumentContent(Value) |
|---|---|
| 1 | “This is an article”//假设这篇文章中含有“w”字母5个 |
| 2 | “This is another article”// 含有“w”字母8个 |
| . | “…” |
| . | “…” |
| 10000 | “This is the last article” //含有“w”字母9个 |
下面是一段伪代码:
map(String key, String value):
// key: document ID
// value: document contents
for each word w in value:
EmitIntermediate(w, “1”);
map函数将被应用到每一个键值对。因此第一次调用为map(1, “This is a article”),最后一次是map(10000, “This is the last article”)。全部map函数运行完毕后,将输出一个中间结果集(表二):
| 字母 | 次数 |
|---|---|
| w | “5” //第一次调用的结果 |
| w | “8” //第二次调用的结果 |
| . | . |
| . | . |
| w | “9” //第1w次 |
该结果集接下来交给reduce函数:
reduce(String key, Iterator values):
// key: a word,”W”
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
reduce函数将被应用到每一个要查询的字母上。在此例中只有一个,”w”。此时只调用一次, reduce(“w”, [“5”, “8”…..”9”])。reduce做的仅仅是将数列中的所有数字相加,就得到了1w篇文章中w字母的个数。处理完成。
从上例我们可以总结出MapReduce的过程:
- Map
首先,因为map是对每一个键值对分别进行计算(即,map函数用来分别统计每一篇文章中w的个数),而文章与文章之间没有什么关联。因此map函数可以实现很高的并行度,map函数的调用可以被灵活分散到多个服务器。
map的输入一般是:(k1, v1)。如上例为(int DocumentID, string ArticleContent),输出是(k2, v2)。如上例是(“W”, 次数).
因此输出结果的key:k2通常不再是k1。k1的信息在大部分情况下并不需要,所以会被丢弃。例如我们通常不再需要DocumentID了。 - Reduce
reduce函数实际的作用是汇总。此时对于字母w,reduce函数的工作已不能再被划分(只有一次调用),因此reduce的并行度并不高。但想象一下,现在的工作是统计1w篇文章中“word“, ”hello“, ”good“….”no“等1w个单词出现的次数,就会需要1w次reduce调用。因此reduce在执行大量复杂任务时,仍然能实现很高的并行度。
reduce的输入一般是(k2, list(v2))。上例中即为(string Word, list count).
输出为(k3, v3)。在上例中reduce函数就是将list sum了一下,所以k2=k3。但并非所有的应用都是这样的。
至此,对map和reduce给出概念
MapReduce是一种批处理计算范型。它可以简单的分为Map和reduce阶段。该范型特别适合在分布式集群上执行计算任务。
Map 函数,由用户编写,处理输入的键值对,输出一系列键值对形式的中间结果。
Reduce函数,也由用户编写,将键值对形式的中间结果作为输入参数。它按key将value merge到一起(可以是求和,求平均值等多种操作),形成一个较小的结果集。
注意在实际应用中,map函数和reduce函数都可以有多个,被称为mapper和reducer。
在实际的MapReduce分布式计算系统(以Hadoop为例)中,为了加快大数据处理,会经过如下更复杂的过程。需要注意的是,用户必须定义的只有Map和reduce函数,其他的步骤(函数)都是分布式计算系统自动完成的。
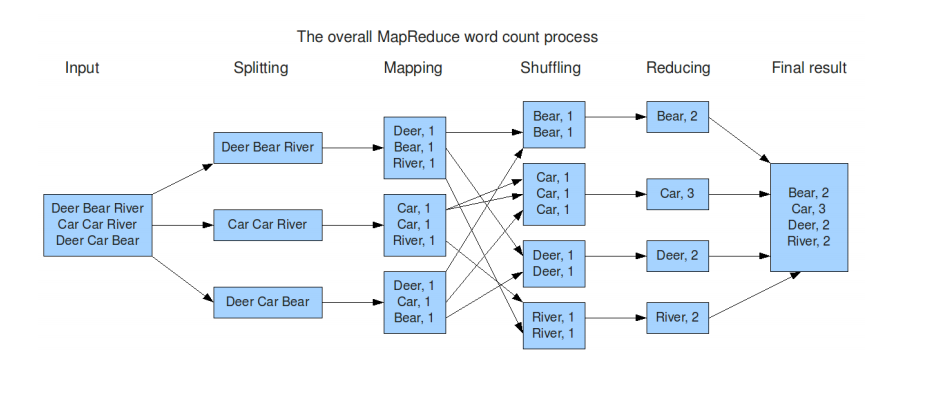
- 数据分片阶段Splitting:The MapReduce library in the user program first shards the input files into M pieces of typically 16MB to 64 MB per piece. It then starts up many copies of the program on a clusterof machines. 上图中数据被分成3份,并分配给3个Mapper处理。
One of the copies of the program is special: the master. The rest are workers that are assigned workby the master. There are M map tasks and R reduce tasks to assign. The master picks idle workers and assigns each one a map task or a reduce task. 注意数据处理开始前,Mapper和Reducer的数量就已经决定了,且可以由系统自动产生,也可以用户自行指定数量。 - Mapping阶段:A worker who is assigned a map task reads the contents of the corresponding input shard. It parses key/value pairs out of the input data and passes each pair to the user-defined Map function. The intermediate key/value pairs produced by the Map function are buffered in memory.
- Combiner函数:Map阶段后,可以对每个mapper的中间结果做一个简单的合并。例如将一个map worker的输入(表二)汇总成(w,“567”)这样的形式,进而提高后续步骤的效率。当一个node的mapper函数输出后,就会调用Combiner将mapper的输出结果整合且合并仅仅发生在单个Mapper的中间结果内部。
- Shuffle和Partition阶段:该阶段的目的是将中间结果分区,且分区的数量是由reducer(记为R)决定的。也就是说,如果有4个reducer,那么就一定会将数据分成4个partition,以便很容易的将partition分配给reducer做进一步处理。分区一般采取的是哈希取模法,即根据key计算哈希值,然后对R取模。由此可知相同的key会被分到一个partition中(如果数据量太大则可能跨多个分区),因此该阶段也有shuffle的效果,既将相同key的数据整个到一起。由示意图可知这个过程由多个Mapper交互完成。
- Reducer开始数据拉取:When a reduce worker is notified by the master about these locations, it uses remote procedure calls to read the buffered data from the local disks of the map workers.
- 拉取完成后,每个reducer对自己负责的数据排序。
- The reduce worker iterates over the sorted intermediate data and for each unique intermediate key encountered,it passes the key and the corresponding set of intermediate values to the user’s Reduce function.The output of the Reduce function is appended to a final output file for this reduce partition.
- When all map tasks and reduce tasks have been completed, the master wakes up the user program.At this point, the MapReduce call in the user program returns back to the user code.
需要注意的是,Mapper和reducer并非是一个机器一个。在一台机器上运行多个虚拟机就可以同时运行多个mapper和reducer。主控服务器决定有多少个mapper和reducer(也可由用户指定个数),以及如何给它们分配计算task。
MapReduce的缺点
- MapReduce更适合非结构化数据的ETL处理类操作,且其可扩展性及容错性好,但是单机处理效率较低。
- 在系统从传统项目转换为MapReduce项目时,所有的数据操作逻辑都必须转换为Mapper和Reducer函数。尽管MapReduce提供了简洁的编程接口及完善的处理机制,使得大规模并发处理海量数据成为可能,但从发展趋势看,相对复杂的任务转换为MapReduce任务的开发效率还是不够高,所以其有逐步被封装到下层的趋势,即在上层系统提供更为简洁方便的开发接口,在底层由系统自动转换为大量MapReduce任务。
- MapReduce本质上是由Map和Reduce序列两阶段构成。尽管Map和Reduce都支持大规模并发,但是由于在Map完成后有任务同步过程(例如 shuffle和partition),因此只有所有Map任务执行完成后才能开始Reduce过程。MapReduce对子任务间复杂的交互和依赖关系缺乏表达能力。















 2324
2324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









