







from multiprocessing import Pool
import requests
from requests.exceptions import ConnectionError
import time
def scrape(url):
try:
print(requests.get(url))
except ConnectionError:
print('Error Occured ', url)
finally:
print('URL ', url, ' Scraped')
if __name__ == '__main__':
start = time.time()
pool = Pool(3)
urls = [
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/'
]
pool.map(scrape, urls)
print(time.time()-start)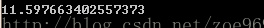
import requests
from requests.exceptions import ConnectionError
import time
def scrape(url):
try:
print(requests.get(url))
except ConnectionError:
print('Error Occured ', url)
finally:
print('URL ', url, ' Scraped')
if __name__ == '__main__':
start = time.time()
urls = [
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/'
]
for url in urls:
scrape(url)
print(time.time()-start)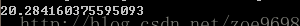















 1041
1041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









