







9.13时间充分,看到网上也没有泰迪杯相关的详细文章,就想花时间记录一下我自己当时的过程,也为后面想参加的同学铺下道路。
泰迪杯我们最终的成绩是国奖一等奖,入围国特答辩,可能因为没有答辩经验,最终止步国一。先给大家看下当时的成果和作品:


这是两个月的成果,最初我们三个朋友,可以说是一点都不懂的,甚至专业都不学这些,看到题目后,靠着从零自学一步步走到最后。

通过这个时间可以看到挑战赛,从开题到全部数据公布这段时间接近两个月,我认为这两个时间从零准备,是完全足够的。只要不浪费这段时间,去查题目的各种资料,做好数据的预处理,准备好数据的各种分析方法,尝试基础的模型,以及熟悉绘图软件及论文的写作方法,拿下国家级奖项应该不难。这样到了公布全部赛题后,就是在一定基础上,带数据进行调试选方法优化,再完善自己的论文。
推荐一个流程图和其他图像的在线制作网站:https://app.diagrams.net/?libs=general;basic;arrows
我们的这道电力负荷预测题目,详细介绍也意义不大了,主要给大家介绍一下我们的探究和解决问题的方式:
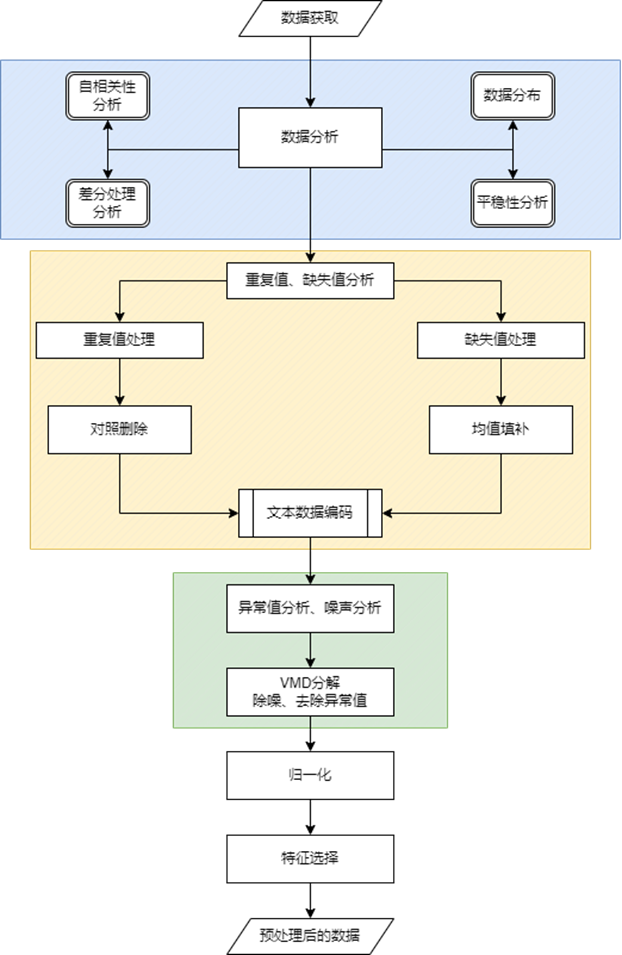
上面这张图可以完整体现我们拿到大型数据后,对他的一个基本的分析和预处理,首先是数据分析部分,具有平稳性的数据才可以更好的时序预测,这时就可以使用ADF统计检验、单位根检验:
| ADF时间序列平稳性检验 | |
| Test Statistic | -6.674614 |
| p-value | 4.497899e-09 |
| Critical value(1%) | -3.430401 |
| Critical value(5%) | -2.861563 |
| Critical value(10%) | -2.566782 |
自相关性分析可以找出数据最基本的时序时间长度,数据与其滞后96个时间的数据有良好的自相关性,即每天同一时段(15min)的数据有较好的相关性,具有一定周期性。

了解数据的分布后,也才可以进行更好的处理,同时电力负荷最早的一个断层,是明显可以去除的数据。

面对大量的数据,不可避免的其中会有一些错误的数据,所以对其中重复的数据进行删除替换和对其中缺失数据进行填补是十分必要的。因为气象数据具有很多的文字类型的数据,想应用到模型中需要对其进行编码转化为数字格式。
完成以上任务后,发现数据中还是有很多明显错误的数据,为异常值,所以需要对其进行噪声的滤波去除,也可以舍弃其中一部分对预测起到副作用的数据。
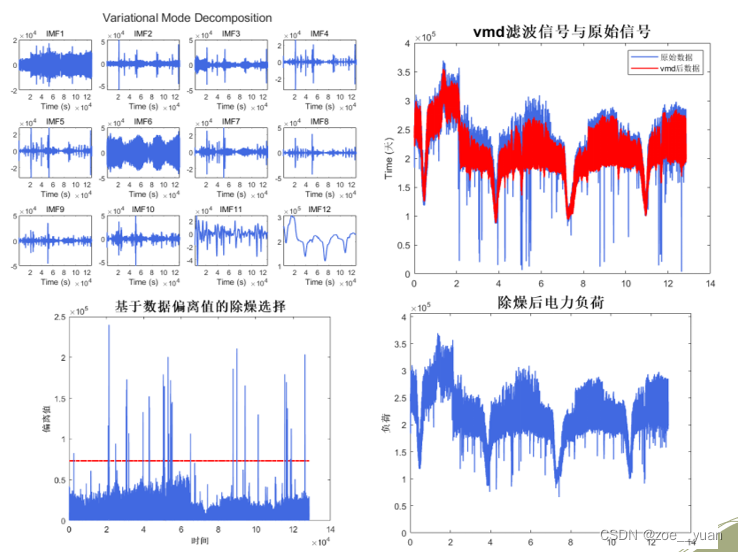
最终我们得到各项数据,它们还存在一个问题就是数据的量级不同,这样将他们全部放入模型中预测的时候它们所占到的比重就不一样,对网络的拟合也会产生坏的影响,所以应该进行归一化或者是标准化,将数据全部转化到同一量级,得到最终预处理后的电力负荷数据和气象数据。但是这些数据在后面的解题过程中,并不是每一问都要全部使用,可以对气象数据进行特征选择来选取一些不重复且相关性较大的影响因素。

(然后关于预测我说一些我自己理解,当我们刚刚开始尝试解题的时候代入各种神经网络模型,逐渐的发现很多程序都是划分了一部门训练集和测试集,在训练集进行一个网络函数的拟合,通常是一定长度的连续输入来预测下一个输出,然后将这个拟合结果代入测试集进行检测,但是我发现大部分程序都是泄露了真实现存的数据,因为每预测未来一个数据,使用的都是该数据之前的数个连续数据,这样的方式是肯定的不能实现真正的未来预测的,必须引入滑动窗口迭代这个方法才可以真正的预测未来一段时间的数据。滑动窗口迭代就是将一定的窗口长度作为输入,来预测下一个数据,并将该预测结果放入窗口中,组成新的长度不变的窗口,再预测下一个数据,不断地迭代,其实我还有想到过一下其他的预测方法,就是隔项进行预测,一定窗口的长度,预测间隔一定长度的数据,也许可以找到更好的的关系,但是我们没有机会仔细尝试了。下面我们的基础预测方法也是基于以上对预测方法的)

在选取基础模型方面我们是基于一下流程图:

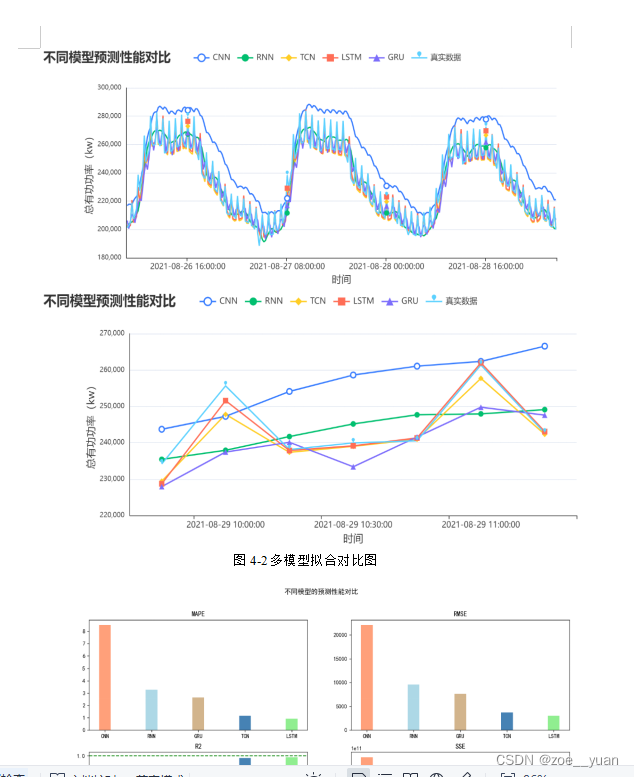
将五个常用的预测模型进行多次尝试对比,选出最优化的LSTM模型:

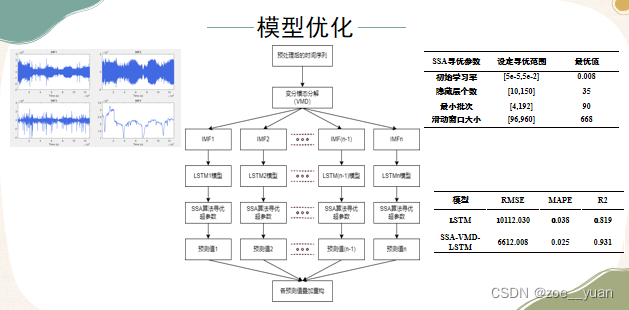
再对其进行SSA—VMD优化,SSA和VMD是什么就大家去自己了解吧。
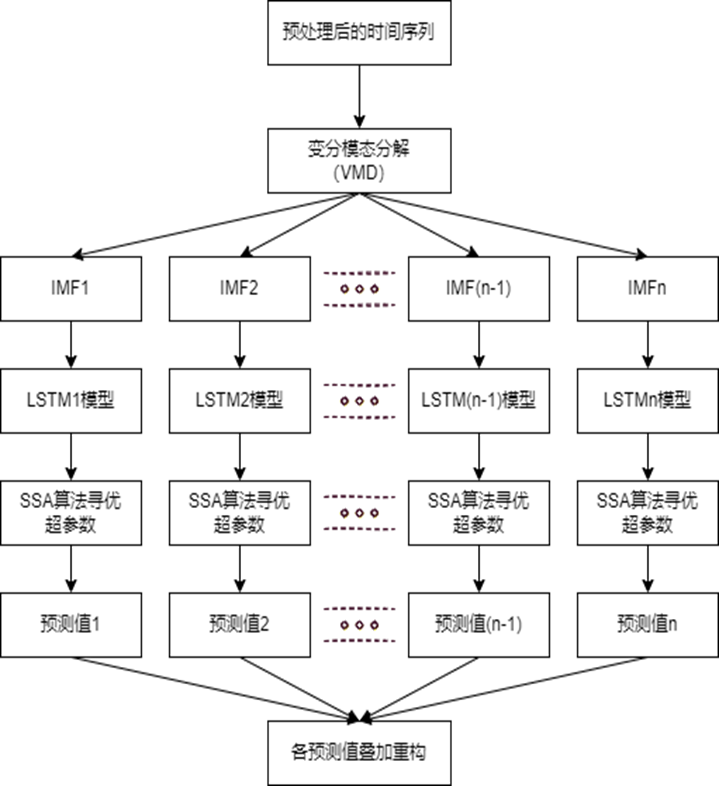
以上基本可以很好的完成短期预测:

而中期的地区和行业预测,也难解决,而我认为题目的难点也正是我们对模型数据输入格式的选取以及数据的选用,所以每一问,我们都选取了四种不同的数据输入格式,并做出评委易懂的原理图,分别尝试每一种情况的好坏,并分析每一种方法的适用情况。因为当时我们很多人都有一个疑问就是测试集会不会提供未来的天气数据用于预测(事实上提供了),所有我们队就准备了各种方式到时候来解决问题,这部分就不放到文章里了,介绍起来太复杂了,以后有时间再详细更新吧。总的来说参加泰迪杯的基础解题方式就是以上,做好以上工作才可以对题目的核心问题进行更充分的探索尝试,后面的部分如果有时间,我也会继续更新。突变点检测方面的问题也类似,可以选用统计学的方法,并多种方法结合同时使用,我们归纳了两种“线型”和“谷型”的突变点,两类结合会有更好的效果:
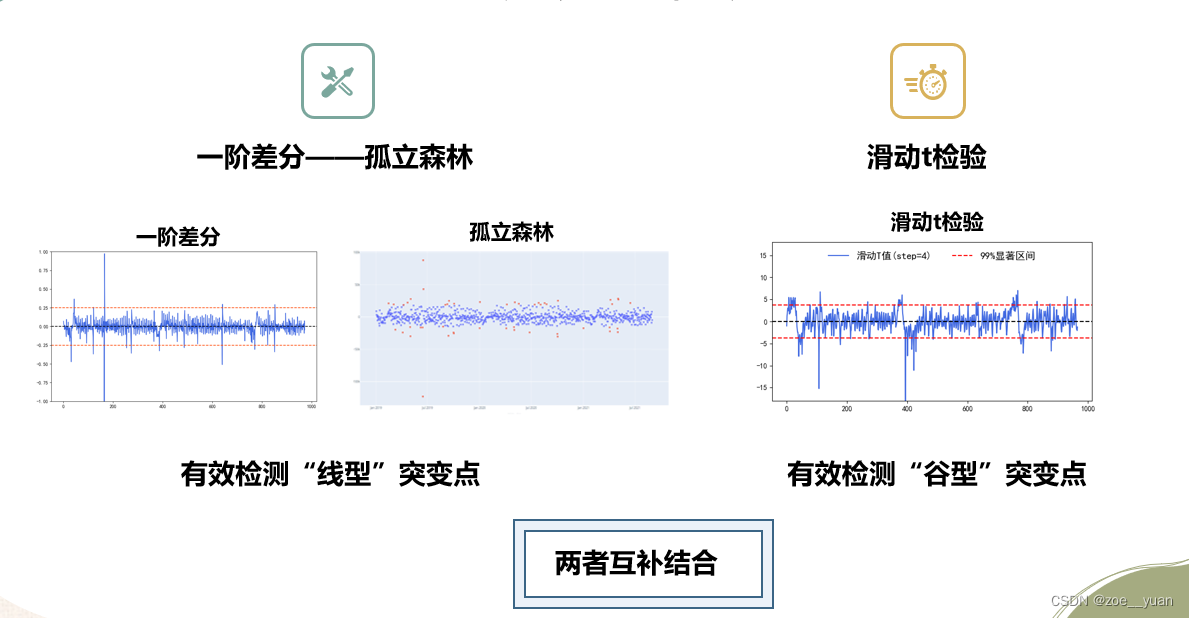
希望对后面参加泰迪杯的同学有所帮助,加油!
2023.4.23
应大家要求,放一些后面论文的图片框架吧





,有需要论文、ppt参考的,私信我一下















 947
947











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









