







吴恩达老师Coursera《Machien Learing》
机器学习的模型表达
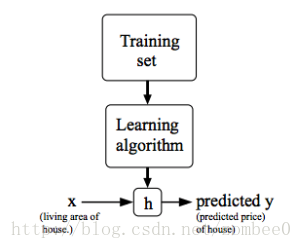
线性模型
h(x)=θ0+θ1x1 h ( x ) = θ 0 + θ 1 x 1
误差函数
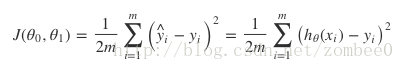
线性回归的过程就是通过对训练集数据的学习,选择使得误差函数最小化的
θ
θ

实现这一过程主要有两种方法:梯度下降和Normal Equation
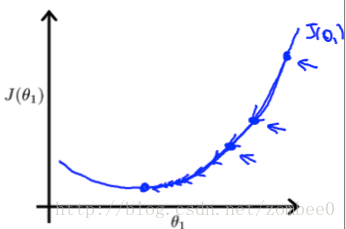
梯度下降
梯度下降的思想是选取导数的相反方向更新
θ
θ
,如图所示:
注意参数更新的时机:

α
α
的选取决定了误差函数收敛的速度,决定了学习的时间。
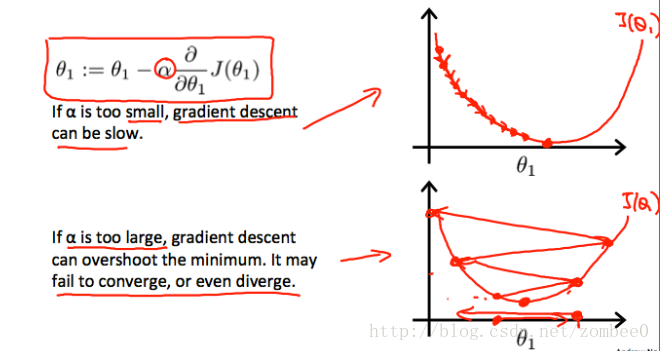
选择
α
α
尝试如下方法:
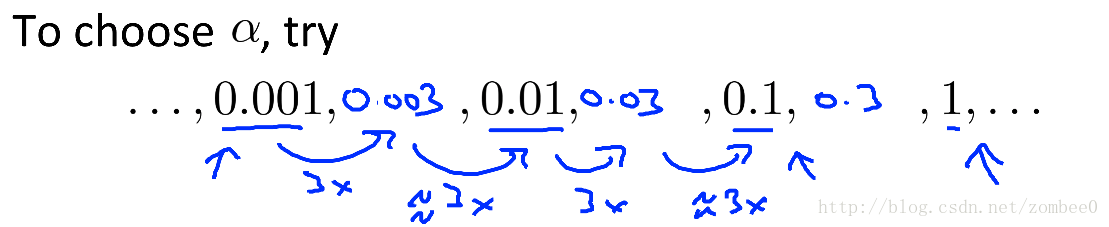
计算中误差函数的导数是这样的:
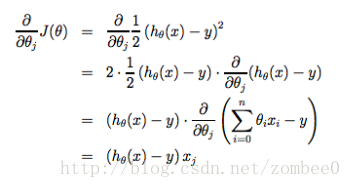
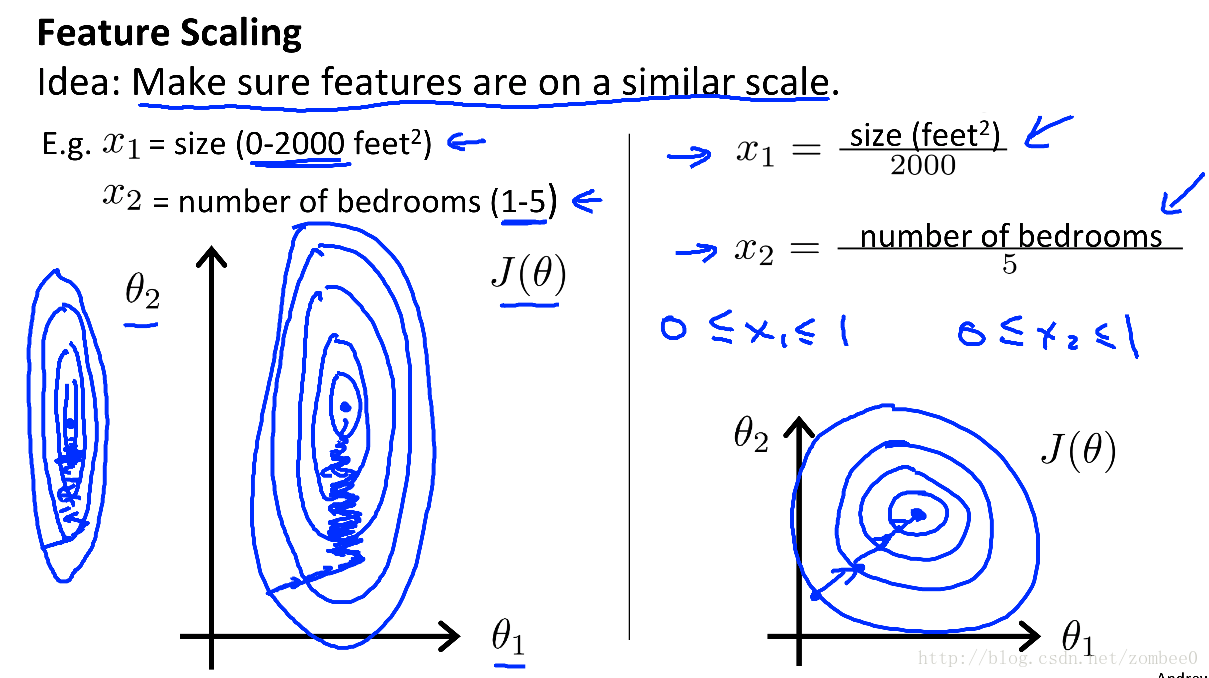
实际应用中可以通过对特征值进行Feature Scaling和Mean Normalization来加速梯度下降其原理示意图如下:
其方法是
xi=xi−mean(x)max(x)−min(x)
x
i
=
x
i
−
m
e
a
n
(
x
)
m
a
x
(
x
)
−
m
i
n
(
x
)
Normal Equation
这是第二种优化误差函数的方法,直接令误差函数对
θ0
θ
0
导数等于0,进而可以求得
θ
θ
表达式:
θ=(XTX)−1XTy
θ
=
(
X
T
X
)
−
1
X
T
y
与梯度下降法相比,Normarl Equation无需选择
α
α
,无需多次迭代,但是计算
(XTX)−1
(
X
T
X
)
−
1
为
O(n3)
O
(
n
3
)
计算量较大,因而更适于特征规模较小的情况,通常10000以下可以考虑。
上述讨论了线性回归的模型、误差函数、参数训练方法,训练方法中还讨论了梯度下降法和Normal Equation两种方法,以及训练过程中需要注意的问题,想要探究内部机理的同学可以仔细研究。然而使用scikit-learn实现线性回归,根本无需考虑这么多问题,请看下文。
scikit-learn实现
最小二乘法
线性模型,最小化方差,求解时采用梯度下降法。
sklearn线性回归非常简单,如下所示:
>>> from sklearn import linear_model
>>> reg = linear_model.LinearRegression()
>>> reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
>>> reg.coef_
array([ 0.5, 0.5])Ridge回归
线性模型的一种优化,主要是为了降低数据敏感性,通过减小||w||实现,在优化目标上添加2范数 α α ||w||2。
>>> from sklearn import linear_model
>>> reg = linear_model.Ridge (alpha = .5)
>>> reg.fit ([[0, 0], [0, 0], [1, 1]], [0, .1, 1])
Ridge(alpha=0.5, copy_X=True, fit_intercept=True, max_iter=None,
normalize=False, random_state=None, solver='auto', tol=0.001)
>>> reg.coef_
array([ 0.34545455, 0.34545455])
>>> reg.intercept_
0.13636...sklearn提供RidgeCV通过交叉验证的方式选择最好的 α α
>>> from sklearn import linear_model
>>> reg = linear_model.RidgeCV(alphas=[0.1, 1.0, 10.0])
>>> reg.fit([[0, 0], [0, 0], [1, 1]], [0, .1, 1])
RidgeCV(alphas=[0.1, 1.0, 10.0], cv=None, fit_intercept=True, scoring=None,
normalize=False)
>>> reg.alpha_
0.1Lasso回归
目的与上述的Ridge回归一样,只是优化目标是方差+|w|,添加的是1范数
>>> from sklearn import linear_model
>>> reg = linear_model.Lasso(alpha = 0.1)
>>> reg.fit([[0, 0], [1, 1]], [0, 1])
Lasso(alpha=0.1, copy_X=True, fit_intercept=True, max_iter=1000,
normalize=False, positive=False, precompute=False, random_state=None,
selection='cyclic', tol=0.0001, warm_start=False)
>>> reg.predict([[1, 1]])
array([ 0.8])sklearn中有Lasso的多种交叉验证方法。
Elastic Net
优化目标添加既有1范数又有2范数
欢迎关注微信公众号“翰墨知道”,获取最新更新。
















 2801
2801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









