







论文下载(带笔记和注释的版本): https://download.csdn.net/download/zongza/10698950
关键词: glottal closure instants (声门闭合时刻) , pitch mark(基音标注), convolutional neural network(卷积神经网络), classification(分类)
零、基础概念
小波变换: 作用类似于傅里叶变换,点击查看参考
声门闭合时刻(GCI): 语音信号中相邻的声门闭合时刻的间隔可以表示一个基音周期,其原理可在发声机理中窥见:点击查看参考1 参考2
当发浊音的时候 ,声带不断地张开 、闭合 , 形成一串周期性的脉冲气流送人声道。这一周期性脉冲串的周期称为“ 基音周期” ,其倒数即基音频率 Fo 。由于声带突然闭合, 压力骤然增大 ,在语音信号的波形上该瞬间有一个明显的幅值突变 。声门相邻两次闭合的时间间隔即为基音周期
现有的检测基音的大多数方法都是以分析帧内语音基音周期是常数这样一个假设为前提的.由于这样的假设通常和实际情况不能很好的符合 , 故检测的基音周期只能按帧变化,不仅不能反映语音基音周期的非平稳性, 而且有时会造成较大的检测误差,因此才出现了检测GCI获得基音周期的方法.
声门闭合时刻的优点、重要性 点击查看参考
由声门振动所包含的信息对于语音交互系统来说很重要,可是想利用好这类信息有如下两个难点:
- 振动周期通常由2.5ms(400HZ)到25ms(40hz)不等,非常多变 (the flexibility of vibration period widely varying from 2.5 ms (400Hz) to 25 ms (40Hz) )
- 对声门振动的响应是由声道变化对声波的修改完成的,这个过程很复杂(the complexity of acoustic modification by the vocal track to the speech wave respond of the vibration )
但是,所有声音都有一种公共的物理特征: 声门闭合时会引起气流激变,从而使得语音波形产生明显的奇异点(characteristic transients 或者说 singularity),该点的存在让detect变得容易得多.
一、摘要
传统的GCI检测基于信号处理(signal processing)和候选选择(different GCI candidate selection methods.)方法,本文提出用cnn作为分类器去检测声门闭合时刻. 整个处理过程包含连续的两步:
- 对信号进行低通滤波(whose negative peaks are taken as candidates for GCI placement)
- 用cnn对上述的候选波谷分类得到GCI(超过一定阈值的波谷就是GCI??)
该方法和已有的三种GCI检测算法在两个公开数据集上做了对比,得到了98.23%的F值,此外,补充实验表明如果训练集和测试集的speaker相同,模型的表现会更好.
二、Intro
2.1motivation
直接从语音信号图检测GCI的重要性
- 许多语音处理方法需要用到GCI(GCI已知作为前提条件)
- electroglottograph (EGG,电声门图,如下图c所示)可以可靠地检测GCi,但是EGG设备难得到难使用
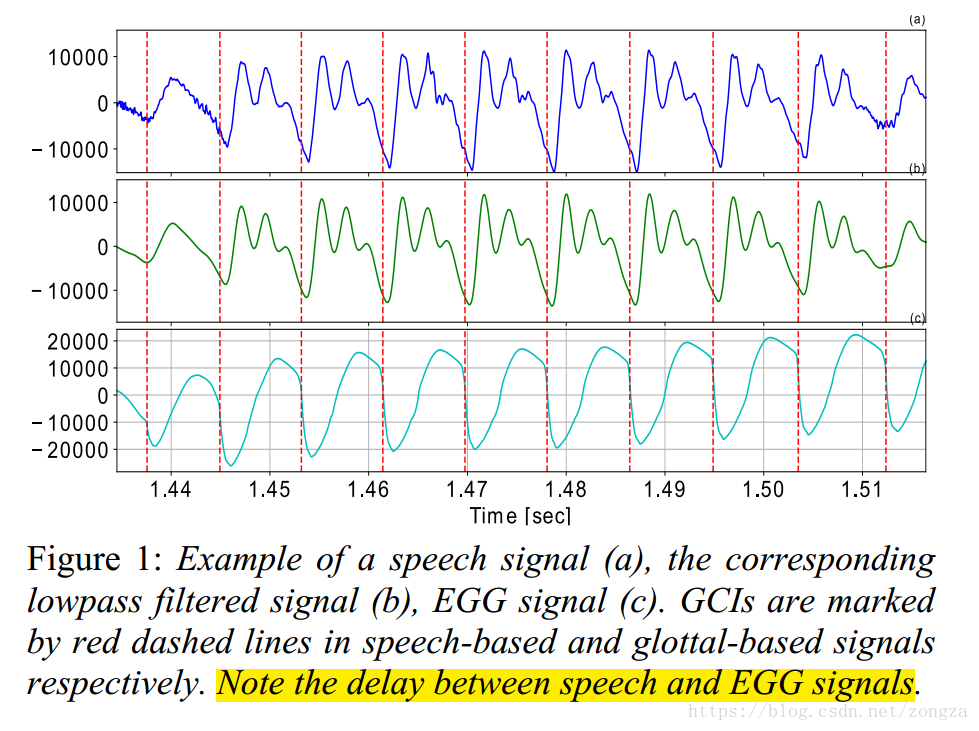
2.2 GCI candidates
语音信号的高频部分对GCI检测没有太大帮助,所以用了低通滤波器(注意:低通滤波信号需要前移1.5ms to fixed the time delay caused by low-pass filtering) ,滤波后的信号波谷作为声门闭合时刻的候选,如下图所示:

2.3 baseline models & features
直接从语音信号检测GCI的传统方法(文中的比较模型):
- DYPSA (The Dynamic Programming Phase Slope Algorithm 动态编程相位斜率算法)
- SEDREAMS (The Speech Event Detection using the Residual Excitation and a Mean-based Signal 基于剩余激励和均值信号的语音事件检测)
- ERT-P3 (extremely randomized trees 随机树) s-o-t-a
方法1,2 缺点: require some manual tuning of parameters (such as window length)
方法3缺点:3虽然和本文模型都是purely data-driven (as the parameters of the classifier are set up automatically based on a training database) ,但是3的feature是人造的:
a set of local descriptors reflecting the position and shape of other 2P neighboring peaks are used as GCI candidate features
这会限制分类器的表现,而CNN方法直接从原始语音信号抓取特征:
Raw waveform samples in a window surrounding the negative peak (GCI candidates) were taken as features in our proposed method. For the speech waveform sampled at 16 kHz, if the window length is 30ms (S = 30), 481 samples (one sample representing the current peak plus 240 samples to the left and 240 samples to the right) were taken as features 也就是相当于nn输入是一个1*481的向量
三、实验结果对比
3.1 语音材料
EGG用来评估,CMU的数据作为训练集测试集
3.2 性能评估方法和指标
GCI分类(classification)性能:

GCI检测(detection)性能:

3.3 结果
- 用mix2(混合BDI和JMK数据集)训练CNN,然后用CNN和其他三种模型去测试 SLT和KED的完整数据集
- 用mix4(混合BDI,JMK,SLT和KED数据集)训练CNN,然后用CNN和ERT-P3去测试 余下的SLT和KED数据集
1中四个模型对比说明在detectin方面CNN在三个detection指标(FAR,IDA,A25)上明显好,但是MR最差,分析原因是:

2中四个模型对比同样得出1中的结果(detection方面),同时2与1对比(2中训练集的speaker也在测试集中,比如SLT和KED的说话人)可得: 在classification方面,如果training set includes utterances from speakers in the test set,那么CNN的PRF都能s-o-t-a(1中CNN只在P值做到最高)
四、总结和个人思考
- 作者对模型的描述(CNN结构)很清晰,值得学习(写作上)
- 作者试验环节设计的很巧妙如mix2数据集和说话人对比.如果是我的话可能直接先用mix4数据集训练CNN,然后用四个模型分别test四个数据集(实验2),能想到用mix2的做对比真的很巧妙.














 7558
7558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









