







SparkSQL的前身是Shark,它抛弃原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-Memory Columnar Storage)、Hive兼容性等,重新开发了SparkSQL代码;由于摆脱了对Hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便。
1、Spark SQL性能
Spark SQL比hive快10-100倍,原因:
①内存列存储( In- Memory Columnar Storage )
基于Row的Java Object存储:
内存开销大,且容易FULL GC,按列查询比较慢。

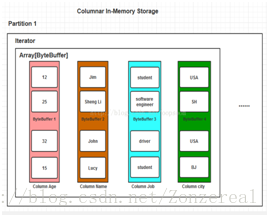
基于Column的ByteBuf f er存储( Spark SQL ) :
内存开销小,按列查询速度较快。
SparkSQL内存列式储方式无论在空间占用量和读取吞吐率上都占有很大优势。
对于原生态的JVM对象存储方式,每个对象通常要增加12-16字节的额外开销,对于一个270MB的TPC-H lineitem table数据,使用这种方式读入内存,要使用970MB左右的内存空间(通常是2~5倍于原生数据空间);另外,使用这种方式,每个数据记录产生一个JVM对象,如果是大小为200B的数据记录,32G的堆栈将产生1.6亿个对象,这么多的对象,对于GC来说,可能要消耗几分钟的时间来处理(JVM的垃圾收集时间与堆栈中的对象数量呈线性相关)。显然这种内存存储方式对于基于内存计算的Spark来说,很昂贵也负担不起。
对于内存列存储来说,将所有原生数据类型的列采用原生数组来存储,将Hive支持的复杂数据类型(如array、map等)先序化后并接成一个字节数组来存储。这样,每个列创建一个JVM对象,从而导致可以快速的GC和紧凑的数据存储;额外的,还可以使用低廉CPU开销的高效压缩方法(如字典编码、行长度编码等压缩方法)降低内存开销;更有趣的是,对于分析查询中频繁使用的聚合特定列,性能会得到很大的提高,原因就是这些列的数据放在一起,更容易读入内存进行计算。
②字节码生成技术( bytecode generation ,即 CG )
③Scala 代码优化
SparkSQL在使用Scala编写代码的时候,尽量避免低效的、容易GC的代码;尽管增加了编写代码的难度,但对于用户来说,还是使用统一的接口,没受到使用上的困难。
2、Spark SQL运行架构
类似于关系型数据库,SparkSQL也是语句也是由Projection(a1,a2,a3)、DataSource(tableA)、Filter(condition)组成,分别对应sql查询过程中的Result、Data Source、Operation,也就是说SQL语句按Result-->Data Source-->Operation的次序来描述的。
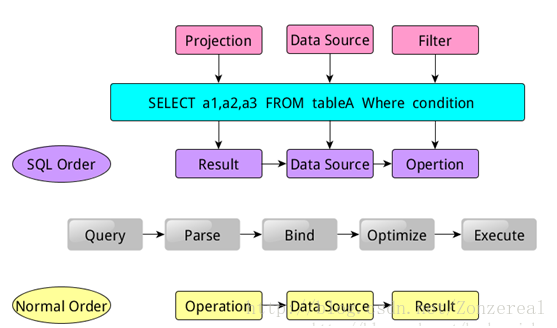
①数据库系统先将读入的SQL语句(Query)先进行解析(Parse),分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source等等。这一步就可以判断SQL语句是否规范,不规范就报错,规范就继续下一步过程绑定(Bind),
②将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定,如果相关的Projection、Data Source等等都是存在的话,就表示这个SQL语句是可以执行的;
③而在执行前,一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划(Optimize),
④最终执行该计划(Execute),并返回结果。当然在实际的执行过程中,是按Operation-->Data Source-->Result的次序来进行的,和SQL语句的次序刚好相反;在执行过程有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运行过的SQL语句,可能直接从数据库的缓冲池中获取返回结果。
以上过程看上去非常简单,但实际上会包含很多复杂的操作细节在里面。而这些操作细节都和Tree有关,在数据库解析(Parse)SQL语句的时候,会将SQL语句转换成一个树型结构来进行处理,如下面一个查询,会形成一个含有多个节点(TreeNode)的Tree,然后在后续的处理过程中对该Tree进行一系列的操作。

3、Spark SQL的代码实现---需要一个DataFream
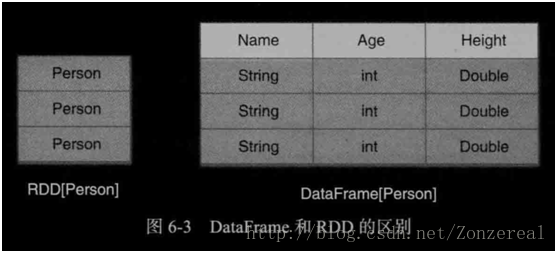
DataFream是以指定列组织的分布式数据集合,相当于关系数据库中的一个表。
DF和RDD的区别:DF是一种以RDD为基础的分布式数据集,带有Schema元信息,每一列都在有名称和类型,如下图所示。















 1414
1414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









