









在《给一句 SQL 就能做多维分析》中我们介绍了润乾报表可以基于一句 SQL 来做数据库数据分析,今天我们来继续说道说道,看看下面这个例子:
这个分析数据集来自回款单,由回款单 ID,回款日期,金额,销售 ID 四个字段组成。
对应的 sql 为:select 回款单 ID, 回款日期, 金额, 销售 ID from 回款单
下图左边的报表就是按照销售 ID 这个维度分组,对回款金额进行汇总分析的结果:
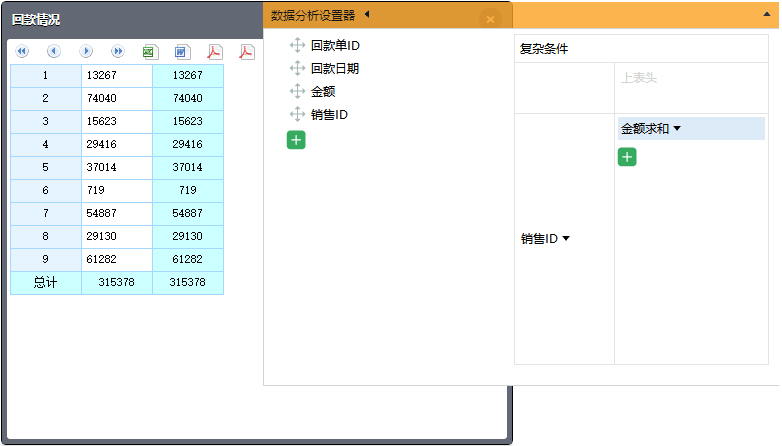
多维分析就是这么简单,写一条 sql 语句,拖拖拽拽就出炉了。像上面这个例子,如果列名是英文的,需要显示中文名,可以修改 sql 语句,通过 as 给每个字段取别名;如果分析结果显示的是销售 ID,希望显示销售名字,可以修改一下 sql,回款表 left join 雇员表就能解决!相信看过了《给一句 SQL 就能做多维分析》,对这些小技巧一定都记忆犹新。
但是,这样就完美了吗?你的多维分析就止步这里了吗?当然不能,我来帮你分析一下:
1,as 确实能解决列名亲民显示的目的,但如果数据库里的字段全是英文的呢?这是有可能的,而且是大大可能的,那每个 sql,就需要你吭哧吭哧挨个写 as,是不是不太爽?而且同一个列名,在不同的 sql 里可能会取不同的别名,感觉是不是乱糟糟的?
2,通过 left join 跟代码表关联,就可以不通过 ID,直接通过名称分组汇总,但试想一下,如果名字有同名的,如何分开统计呢?再想想,和代码表关联,总要知道两表之间的亲戚关系吧,这对前端分析人员要求是不是过分了点?
所以啊,如果只是简单的,个别的数据库数据分析,写个 sql 能搞定也就作罢了,但现实往往给我们提出了更高的要求,那如何迎战呢?这就是我们今天要给大家隆重介绍的多维分析中的元数据和字典,简单来说,就是基于预先定义好的语义层来进行多维分析,前端分析人员不需要了解,只管拖就行。我们先来体验一把:
还是从回款单里取数:

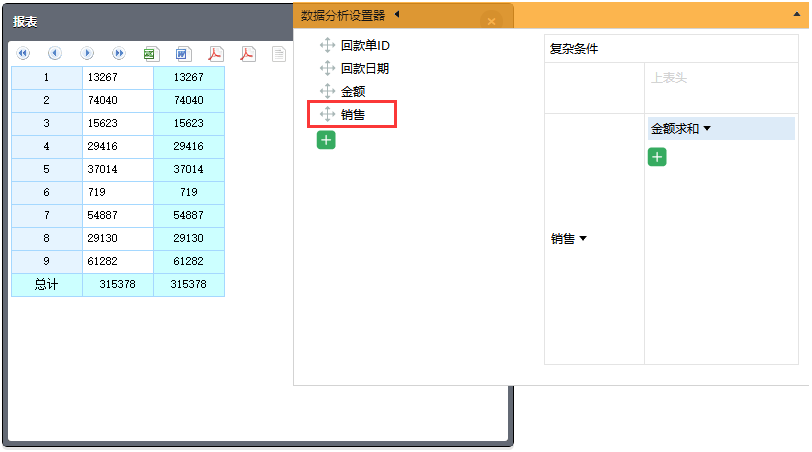
分析数据集直接显示别名“销售”,而不是“销售 ID”,查询语句并未因此而变复杂!
继续往下看,如何将分析结果中的销售 ID 显示为销售名称?
销售列点【显示值】菜单,选择销售的代码表
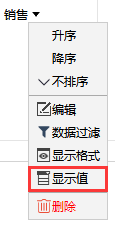
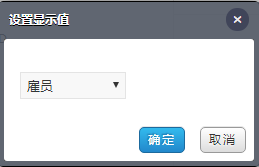
销售 ID 秒变成大名:
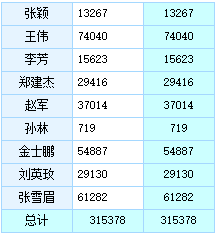
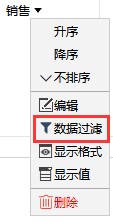
如果只想看部分销售的回款情况呢?销售列点【数据过滤】菜单,设置过滤条件:
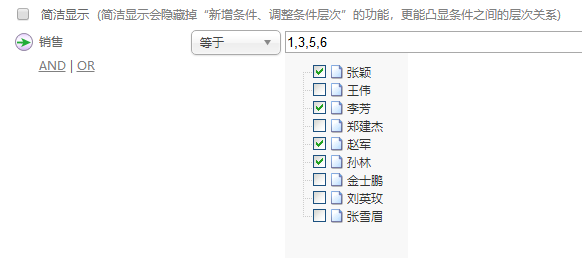
下拉菜单直接显示销售名字,而不是 ID, 过滤结果如下:
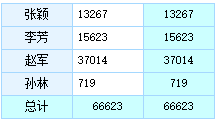
大家是不是发现,整个过程,都没有修改查询语句,而且我们分析的数据集里也没有出现销售姓名列,这就是预定义语义层的功劳,这样是不是让前端分析人员轻便了不少?下面我们就来介绍一下如何让前端分析人员用上多维分析的语义层:
第一步:打开元数据层设计器,系统菜单下选择【数据源】,配置好数据源并连接,连接之前,当然要保证所连接数据源已启动哦。
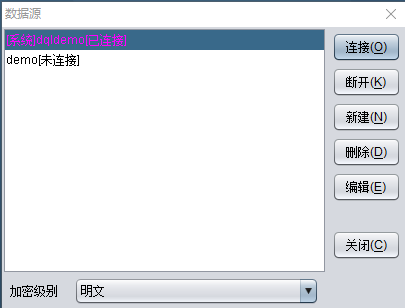
演示数据用的是润乾自带的 dqldemo 数据库,所以该数据库不用配置,通过【服务 - 启动示例数据库】菜单启动数据库后,在上图所示对话框中直接连接就 OK 了。
第二步:创建元数据文件
文件菜单栏下选择【新建】,选择元数据:
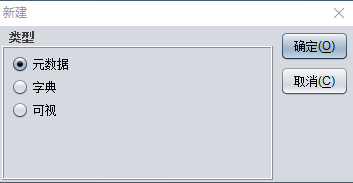
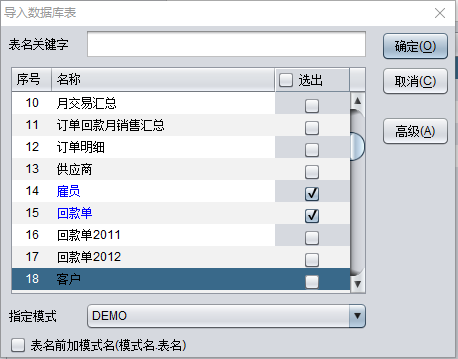
系统菜单下选择【导入数据库表】,选中需要的物理表,导入表结构:
给导入的表设置主键,给字段设置别名,这样就可以直接用别名写查询语句,而不用重复用 as 了:
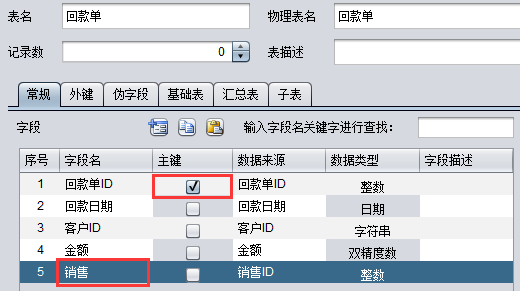
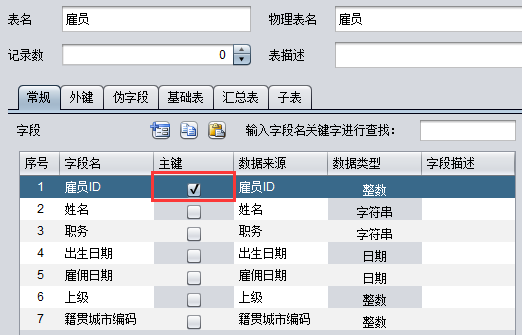
给维字段设置更直观的维名,这样页面显示值下拉列表显示会更友好:
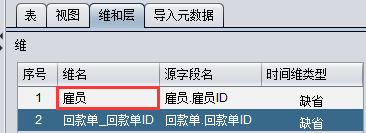
制作好的元数据文件保存为后缀为 lmd 的文件。
第三步,定义字典文件
打开前一步做好的元数据文件,系统菜单下选择【生成字典】,一个字典文件就自动生成了。
在字典文件里设置雇员的显示列字段,销售名字就可以用于分析结果和过滤条件的下拉显示:

制作好的字典文件保存为后缀为 dct 的文件。
到此,语义层定义就做完了,下面就是如何把语义文件部署到我们的应用中,能在页面上玩转起来!如果你还没有自己的应用,那可以直接在润乾报表内置的 demo 应用里直接发布,过程很简单,一起了解一下:
第一步,启动 DQL 服务
因为有了元数据文件,所以需要有 DQLServer 服务器来进行语义的解析,点击【** 服务 - 启动 DQL 服务】** 菜单,在随后弹出的 DQL 服务器控制台中启动 DQL 服务即可:
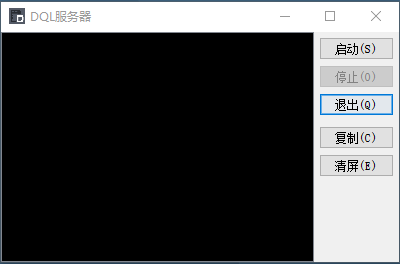
当然,如果你用的是你自己的数据库,此刻数据库保持启动状态是必须的哈!
细心的读者可能已经发现,DQL 这个词在界面中出现过多次,它到底是什么东西吗?嗯,现在先不去管它,用起来再说,以后我们还会有专门文章来讲到底什么是 DQL,以及为什么会出现它。
第二步,发布
通过【服务 - 发布并浏览 DQL 分组分析】菜单打开发布对话框,选择前面制作好的元数据文件和字典文件:
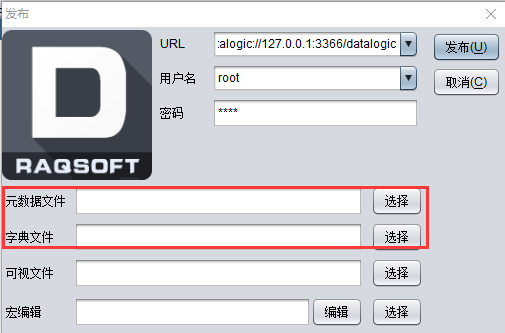
点击【发布】按钮,后台程序会自动启动内置的 tomcat 服务,并打开分组分析页面:

点击数据集,编辑一条最简单的查询语句,正如我们开篇所演示的,就可以开始语义多维分析的美妙之旅啦!
是不是感觉内置环境的发布相当简单?但如果有了自己的应用,元数据文件和字典文件的部署还是需要进一步深入学习,并根据需求灵活处理的,有兴趣深挖的,可以按以下路线去探探——
元数据文件需要部署到 DQLServer 服务器,如果您希望部署独立的 DQLServer,可以到《分析教程》中查看关于 DQL 服务器部署集成的专题;
字典文件是部署到 web 应用目录下,并在发布分析控件的页面里通过 JS API 去灵活设置,关于这部分的介绍,可以到《分析教程》JS API 相关主题中查看。
关于有语义的多维分析,今天我们就先唠五毛钱的,有木有觉得,虽然语义层需要预先定义,还需要部署服务,但却是一劳永逸的,管理井然有序,前端分析灵活方便。其实语义还能帮您做更多,要不要这么夸张?不信就赶紧下载亲自用用啰!
链接:http://c.raqsoft.com.cn/article/1535687623119?r=javasun1990
来源:乾学院














 2287
2287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









