










requests库爬取汽车之家(get请求)
首先分析网页结构
查看网页源代码发现标题,图片url,福利和购买跳转链接id都在源码里有:


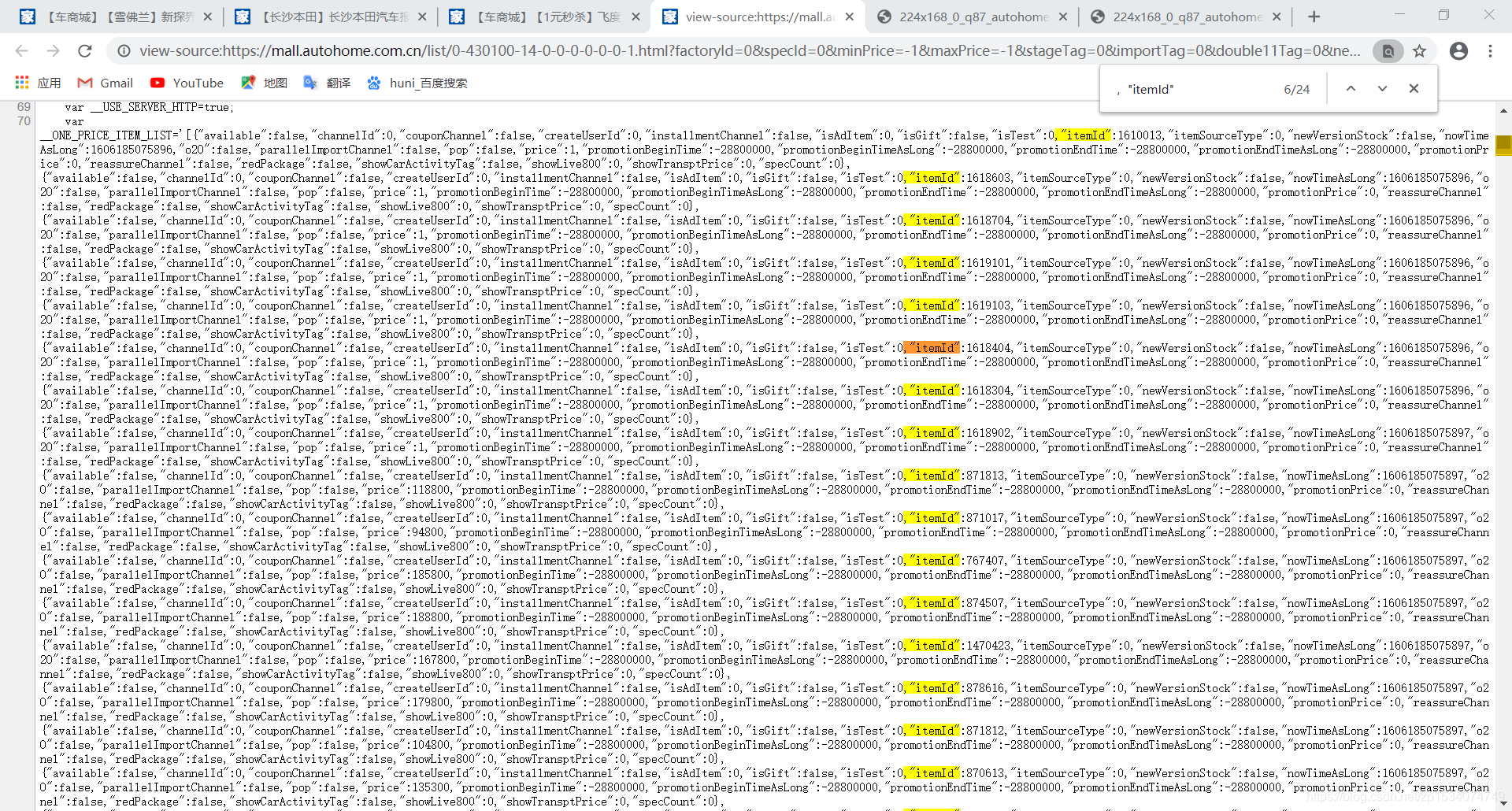
所以对于标题,福利,和图片url都在标签里,我们可以用xpath进行提取,而购买跳转链接id在json形式的字符串里,所以我们用正则表达式提取
代码如下:
title=etree.HTML(req.text).xpath('//*[@id="list"]/ul/li[1]/a/div[4]/text()')
newtitle=title[0].replace('\r\n\t','').replace(' ','')
print('标题:',newtitle)
fl=etree.HTML(req.text).xpath('//*[@id="list"]/ul/li[1]/a/div[5]/text()')
fuli=fl[0].replace('\r\n\t','').replace(' ','')
print('福利:',fuli)
photourl=etree.HTML(req.text).xpath('//*[@id="list"]/ul/li[1]/a/div[2]/img/@data-original')
tpurl='https:{}'.format(photourl[0])
print('图片url:',tpurl)
href=re.findall(',"itemId":(.*?),',req.text)
print('跳转链接id:'href)
接下来我们去拿购买页面的内容,随便打开一个车购买页面

我们来拿这个这辆车的库存数量,和他所有车型的参数配置
通过分析,分析数据都是json形式存在接口里



又发现不同型号的车型的参数配置都放在两个接口里,且不同的只有data[specid]这个参数


所以我们通过改变这个参数就可以拿到这辆车里面的所有车型的参数配置了
通过分析,发现data[specid]的值在源码里能找到,所有我们就拿xpath去提取就好了
newdata=etree.HTML(rsp.text).xpath('//*[@id="detailParameter"]/div[1]/dl/dd/div/div[2]/ul/li/a/@data-value')
print(newdata)
这样就可以拿到所有的data[specid]的值了
然后在遍历,就可以拿到这个车所有车型的参数配置了
拿到自己需要的数据后,再存入csv格式:
完整代码如下:
import requests
import re
import json
from lxml import etree
def get_data(page):
with open('qczj.csv', 'a', encoding='utf-8') as f:
f.write('标题' + ',' + '福利' + ',' + '图片url' + ',' + '购买url' + ',' + '库存' + ',' + '参数配置' + '\n')
for j in range(1,page+1):
url='https://mall.autohome.com.cn/list/0-430100-0-0-0-0-0-0-0-{}.html?factoryId=0&specId=0&providerId=&prefix= '.format(j)
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
req=requests.get(url,headers=headers)
''''标题、福利好礼、库存、成交量、所有参数配置、图片URL、购买URL'''
title=etree.HTML(req.text).xpath('//*[@id="list"]/ul/li[1]/a/div[4]/text()')
newtitle=title[0].replace('\r\n\t','').replace(' ','')
print('标题:',newtitle)
fl=etree.HTML(req.text).xpath('//*[@id="list"]/ul/li[1]/a/div[5]/text()')
fuli=fl[0].replace('\r\n\t','').replace(' ','')
print('福利:',fuli)
photourl=etree.HTML(req.text).xpath('//*[@id="list"]/ul/li[1]/a/div[2]/img/@data-original')
tpurl='https:{}'.format(photourl[0])
print('图片url:',tpurl)
href=re.findall(',"itemId":(.*?),',req.text)
for k in range(0,len(href)):
baseurl='https://mall.autohome.com.cn/detail/{}-430100-0.html?'.format(href[k])
print('购买url:',baseurl)
rsp=requests.get(baseurl,headers=headers)
specid=etree.HTML(rsp.text).xpath('//*[@id="detailParameter"]/div[1]/dl/dd/div/div[2]/ul/li/a/@data-value')
kcurl='https://mall.autohome.com.cn/http/data.html?data%5B_host%5D=%2F%2Fmall.api.autohome.com.cn%2Fitem%2Fstock%2FgetList&data%5B_appid%5D=mall&data%5BitemId%5D={}'.format(href[k])
rsp1=requests.get(kcurl,headers=headers)
kc=json.loads(rsp1.text)['result'][0]['sellableStock']
print('库存:',kc)
cspz = ''
for i in specid:
baseurl2 = 'https://mall.autohome.com.cn/http/data.html?data%5B_host%5D=%2F%2Fcar.api.autohome.com.cn%2Fv1%2Fcarprice%2Fspec_paramsinglebyspecid.ashx&data%5B_appid%5D=mall&data%5Bspecid%5D={}&data%5BconfigPath%5D=%2F%2Fcar.api.autohome.com.cn%2Fv3%2FCarPrice%2FConfig_GetListBySpecId.ashx&data%5BparamPath%5D=%2F%2Fcar.api.autohome.com.cn%2Fv1%2Fcarprice%2Fspec_paramsinglebyspecid.ashx'.format(i)
baseurl3='https://mall.autohome.com.cn/http/data.html?data%5B_host%5D=%2F%2Fcar.api.autohome.com.cn%2Fv3%2FCarPrice%2FConfig_GetListBySpecId.ashx&data%5B_appid%5D=mall&data%5Bspecid%5D={}&data%5BconfigPath%5D=%2F%2Fcar.api.autohome.com.cn%2Fv3%2FCarPrice%2FConfig_GetListBySpecId.ashx&data%5BparamPath%5D=%2F%2Fcar.api.autohome.com.cn%2Fv1%2Fcarprice%2Fspec_paramsinglebyspecid.ashx'.format(i)
rsp2=requests.get(baseurl2,headers=headers)
rsp3=requests.get(baseurl3,headers=headers)
print(rsp2.text)
print(rsp3.text)
cspz+=rsp2.text
cspz+=rsp3.text
print('=='*20)
print(cspz)
print('=='*20,'第{}辆车信息爬取完毕'.format(k),'=='*20)
stra=newtitle+','+fuli+','+tpurl+','+baseurl+','+str(kc)+','+cspz+'\n'
f.write(stra)
print('==' * 20, '第{}页爬取完毕'.format(j), '==' * 20)
if __name__ == '__main__':
page=int(input('请输入爬取页数:'))
get_data(page)
说明:车辆的参数配置拿到的是json字符串,我这里存入的也是json字符串,没有经过处理,如果需要完整数据,只需要for循环遍历取值处理一下就好了,码字不已,希望各位看完小伙伴给我来个一键三连,谢谢。
注:本文章仅供参考学习















 1481
1481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









