






文章信息
**原文:**BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
文章链接:
https://arxiv.org/abs/1810.04805
源码:
GitHub - google-research/bert: TensorFlow code and pre-trained models for BERT
摘要
Bert :Bidirectional Encoder Representiaions from Transformers.
目的:旨在通过大量无标签文本训练,从中获取到语义信息。用户只需在预训练好的模型后面加上相应输出层,即可完成相应任务。
结果:该模型的提出,在11个自然语言任务上,获得了很不错的结果。
模型训练方式(MLM、NSP)
MLM :
a) 类似于英语中的完型填空。给定一个文本,随机遮掩住(Mask)一些词,通过反复训练使得模型能够理解文本语义,从而正确预测出Mask掉的词。
b) 在实际模型训练中,对于单样本, 首先随机选取15%的词(token)作为Mask备选,其次对于这备选词,在随机选取80%的词进行Mask,10%的词保持不变,10%的词随机替换为词库中的词。
NSP:
给定一篇文章中的两句华,判断第二句话是否紧跟着第一句话后面。
模型
只用到了Transformer的编码部分:
单个编码块包括:多头注意力、残差链接并LayerNormalization、两层全连接层(其中第一层主要用于将输入特征映射到高维表示,进一步提取相关信息。第二层则用于降维至原始维度)加残差连接并LayerNormalization。

输入层:
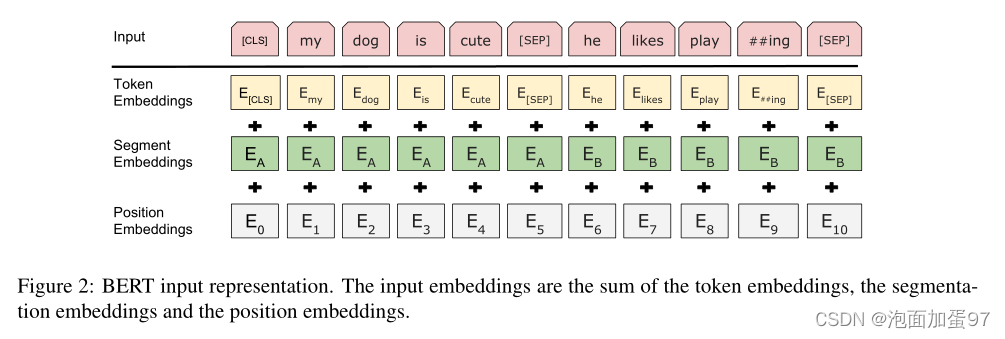
模型输入=Position Embedding + Segment Embeddings + Token Embeddings
Position Embedding

位置嵌入采用正弦、余弦相混合的方式,其中pos代表词的位置,而 d 表示嵌入的维度,2i 表示嵌入维度的偶数维,2i+1则为奇数维。(2i<=d, 2i+1<=d)
预训练运行走向
1、数据处理:对输入样本进行Mask,并记住Mask掉的内容作为Label。
2、模型训练:将预处理后的数据进行相应Embedding,随后送入Bert模型进行训练。
3、模型保存:设置模型训练断点,保存模型。用于后续微调。















 1366
1366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









