







逻辑回归
首先说明一下,本人不是学数学的。本篇不会涉及太复杂的公式推导。只是一些朴素的理解,不严谨(我觉得更重要)。
特征量有 x1x2...xn 这些n个。
那么线性回归函数形式:
这个可以理解吧。我们现在要求的是该回归函数(二维的情况下可以简单理解为一条直线),分割成俩部分(也就是分类)而 c1c2...cn 就是所谓的回归系数了。 能满足z>0则是“分类1”,z<0则表示“分类0”。,那么如何来求g(z)满足z上述条件呢?接下来就引入Sigmoid函数。
Sigmoid函数

关于为什么需要用到Sigmoid函数?其实严格的我也不清楚。
Sigmoid 函数在有个很漂亮的“S”形,如下图所示:
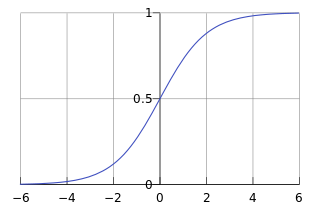
看到上面到图形,是不是会心一笑(有木有),很容易联想到(能满足z>0则是“分类1”,z<0则表示“分类0”)。如果把回归函数带入进去,g(z)表示:
为了实现Logistic回归分类器,我们可以在每个特征上都乘以一个回归系数,然后把 所有的结果值相加,将这个总和代人函数中,进而得到一个范围在0〜1之间的数值。任何函数值大于0.5的数据被分人1类 ,小于0.5即被归人0类 。所以 ,Sigmoid函数也可以被看成是一种概率估计。
上面就是很朴素的思考过程。不严谨希望大家见谅哈。
其实现在我们需要根据训练数据集得到的就所谓的回归系数。
那么用所谓的梯度递减法来获取吧,其实就是每次移动一个梯度,逼近真实系数。
那么假设初始回归系数都为1
# alpha:步长,maxCycles:迭代次数,可以调整
# 这个是梯度递增,其实一样的alpha里面的值有正有负
def gradAscent(dataArray, labelArray, alpha, maxCycles):
dataMat = mat(dataArray) # size:m*n
labelMat = mat(labelArray).transpose() # size:m*1
m, n = shape(dataMat)
weigh = ones((n, 1)) #初始回归系数都为1
for i in range(maxCycles):
h = sigmoid(dataMat * weigh) #可以看成为分类1的概率
error = labelMat - h # size:m*1 差值
#labelMat分类1的概率要么为0,要么为1
#如果差值越小,说明拟合的越好。(最大似然)
weigh = weigh + alpha * dataMat.transpose() * error
#通过最大似然,用梯度递减进行逼近 这个地方有点不好理解。
#关于梯度的方向问题,我的大体理解是,方向是求导得到的方向。
#每个特征方向上都变化一些(当然有推导过程,讲道理有点复杂)
return weigh #就是回归系数最大似然估计:现在已经拿到了很多个样本(训练集),这些样本值已经知道了,最大似然估计就是去找到那组参数估计值,使得前面已经实现的样本值发生概率最大。因为你手头上的样本已经实现了,其发生概率最大才符合逻辑。
其实我不想推导的。没办法,最后那一步很难直观去理解。
以下推导过程主要参考了
里面好多公式图呀,逻辑清晰,大神66666。
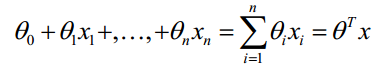
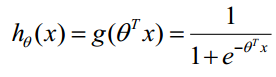
上面好理解吧,函数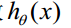
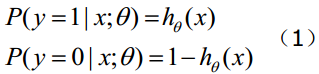
综合起来可以写成:
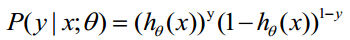
通过最大似然估计,那么似然函数为
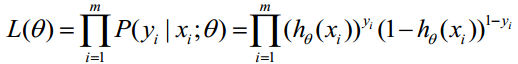
就是说训练集里面,每一组数据(包含结果)的概率的乘积就是整个训练集发生的概率。ok?
也就是求上述式子的最大值。理解?
取对数就变成相加了:

最大似然估计就是求使 取最大值时的θ。对吧?
取最大值时的θ。对吧?
再来一波
但是,在Andrew Ng的课程中转换了一下即:

因为乘了前面-1/m系数,那么取 最小值时的θ为要求的最佳参数。
最小值时的θ为要求的最佳参数。
梯度下降法求的最小值
θ更新过程:


θ更新过程可以写成:















 537
537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









