







 本文深入解析Quartz定时任务框架,涵盖Scheduler、Job、Trigger等核心组件,详细讲解SimpleTrigger和CronTrigger的触发规则,以及任务超时后的处理策略。
本文深入解析Quartz定时任务框架,涵盖Scheduler、Job、Trigger等核心组件,详细讲解SimpleTrigger和CronTrigger的触发规则,以及任务超时后的处理策略。
一、基本组件介绍
- Scheduler 任务调度器,按照特定的触发规则,自动执行任务。
- Job 接口,定义需要执行的任务。
- JobDetail 包含job的基本信息。
- Trigger 描述Job执行的时间触发规则。
- JobStore 存放Job、Trigger等信息。
Scheduler
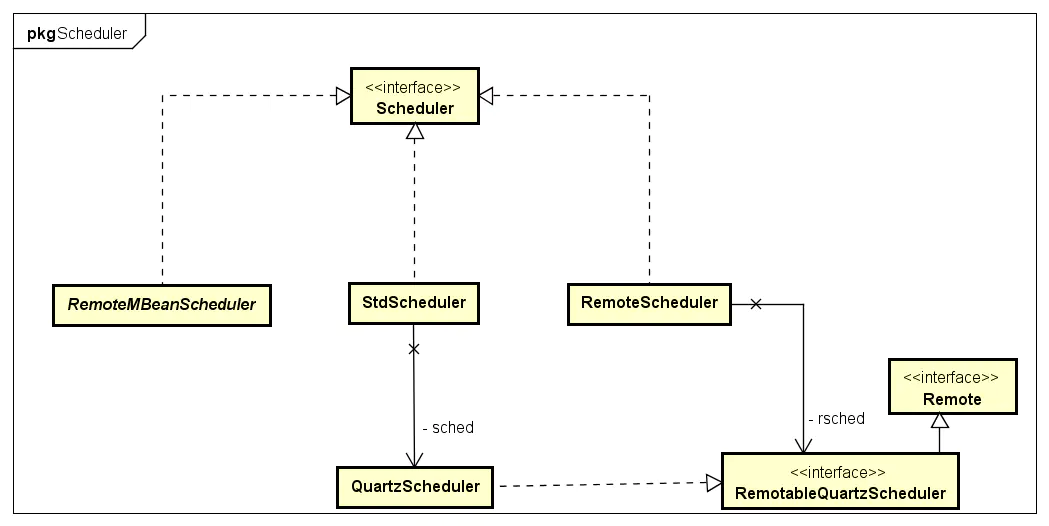
Scheduler是一个任务调度器,保存JobDetail和Trigger的信息。 在Trigger触发时,执行特定任务。
实现了org.quartz.Scheduler接口的StdSchedule实际只是QuartzScheduler的代理,后者实现了Scheduler所有操作。
创建
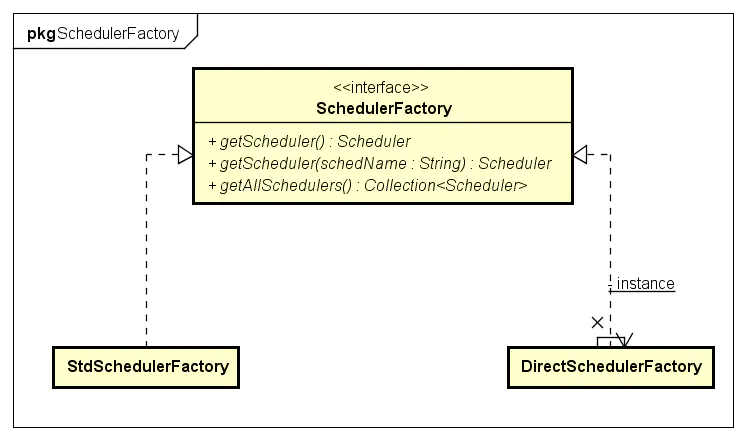
Scheduler由SchedulerFactory创建。
SchedulerFactory有两个默认实现StdSchedulerFactory和DirectSchedulerFactory。
Scheduler的创建过程包括:
- 读取配置文件, 配置文件中需要配置scheduler、线程池、jobStore、jobListener、triggerListenner、插件等。
- 配置文件的读取过程如下:
- 读取参数系统参数System中配置的org.quartz.properties指定的文件
- 如果找不到则读取项目Classpath目录下的quartz.properties配置文件
- 如果找不到则读取quartz jar包中默认的配置文件quartz.properties
- 从SchedulerRepository中根据名称读取已经创建的scheduler,
- 如果没有则重新创建一个,并保存在SchedulerRepository中。
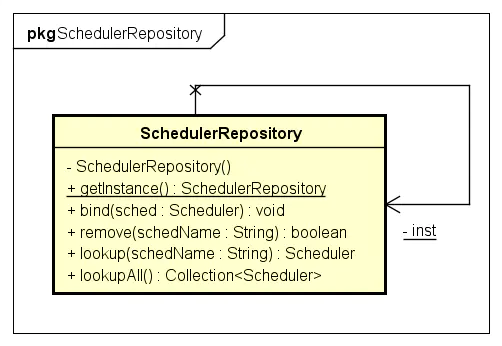
存储
Scheduler存储在单例的SchedulerRepository中。
生命周期
Scheduler的生命周期开始于其被创建时,结束于shutdown()方法调用。一旦对象创建完成,就可以用来操作Jobs和Triggers,包括添加、删除、查询等。但只有在Scheduler start()被调用后,才会按照Trigger定义的触发规则执行Job的内容。

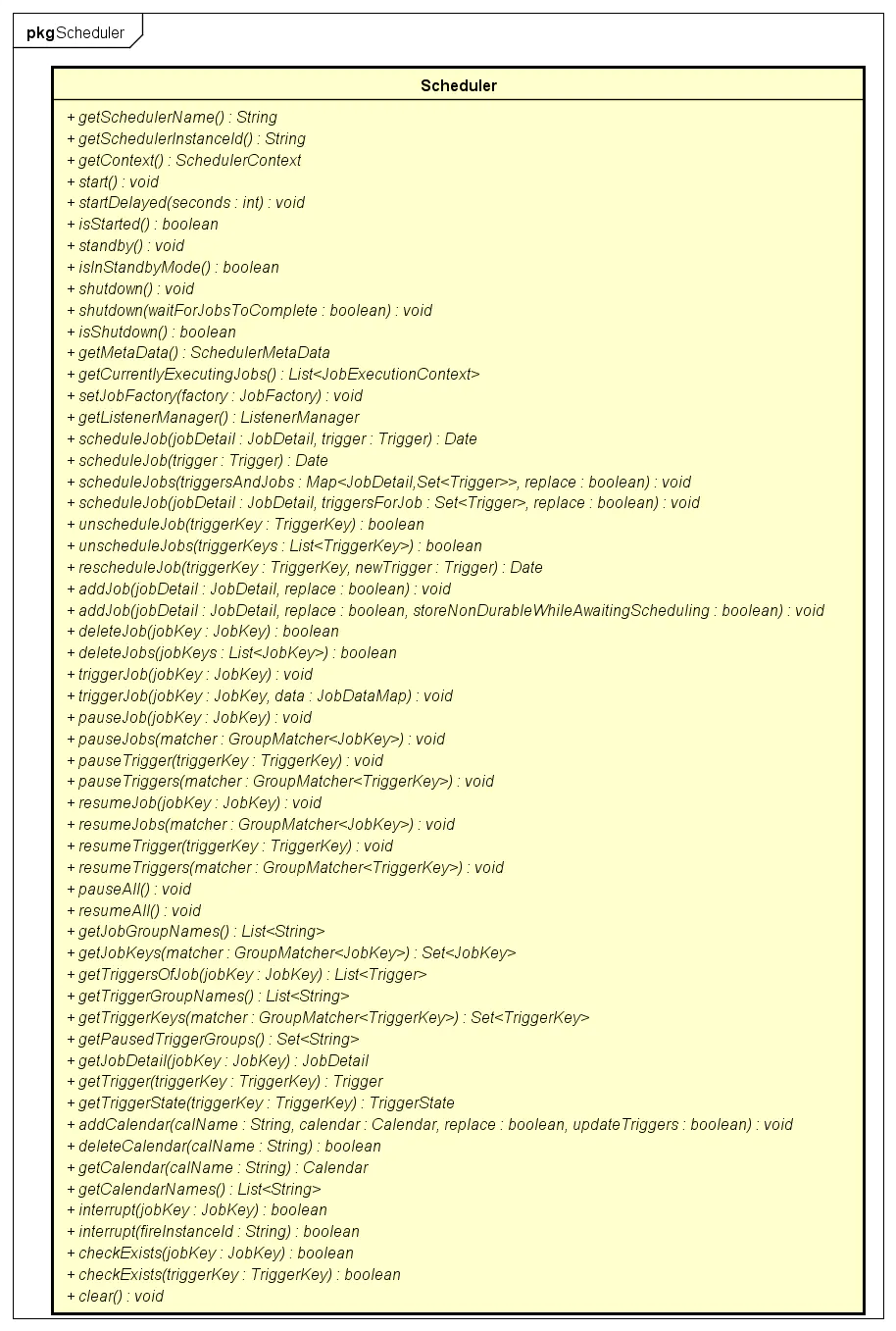
核心方法
Scheduler的核心功能就是操作Job、Trigger、Calendar、Listener等。包括addXXX、deleteXXX、pauseXXX、resumeXXX等。
Job
Job接口简介
Job就是定时任务实实在在执行的内容,足够单纯,仅仅包含一个执行方法。
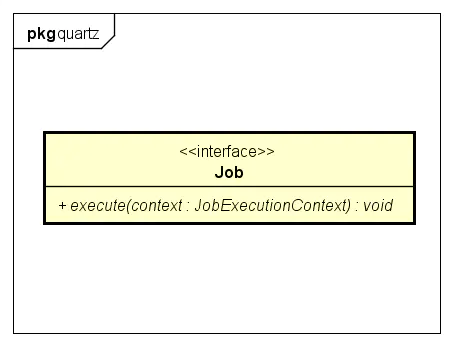
Job
JobExecutionContext对象包含了当前任务执行的上下文环境,包括JobDetail、Trigger以及jobDataMap等。

Job运行时环境
Job的执行并不是孤立封闭的,需用与外界交互。JobDataMap是一种扩展的Map<String,Object>结构,就是用来在任务调度器与任务执行之间传递数据。如果Job中包含了与JobDataMap中key值相对应的setter方法,那么Scheduler容器将会在当前Job创建后自动调用该setter方法,完成数据传递,而不用hardcode的从map中取值。
Scheduler控制在每次Trigger触发时创建Job实例。因此JobExecutionContext.JobDataMap只是外部Scheduler容器中JobDataMap的一个拷贝,即便修改Job中的JobDataMap也只是在当前Job执行的环境中生效,并不会对外部产生任何影响。
Job的派生
Job下面又派生出两个子接口:InterruptableJob和StatefulJob
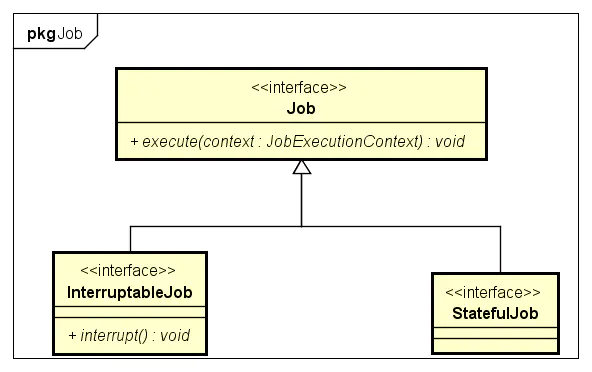
Job体系结构
InterruptableJob:可被阻断的Job,InterruptableJob收到Scheduler.interrupt请求,停止任务
StatefulJob:有状态Job,标识性接口,没有操作方法。StatefulJob与普通的Job(无状态Job)从根本上有两点不同:
1. JobDataMap是共享的,即在Job中对JobDataMap的操作,将会被保存下来,其他Job拿到的将是被修改过的JobDataMap。
2. 基于第一条原因,StatefulJob是不允许并发执行的。
StatefulJob已被DisallowConcurrentExecution/PersistJobDataAfterExecution注解取代
Job的创建
Job的创建由专门的工厂来完成
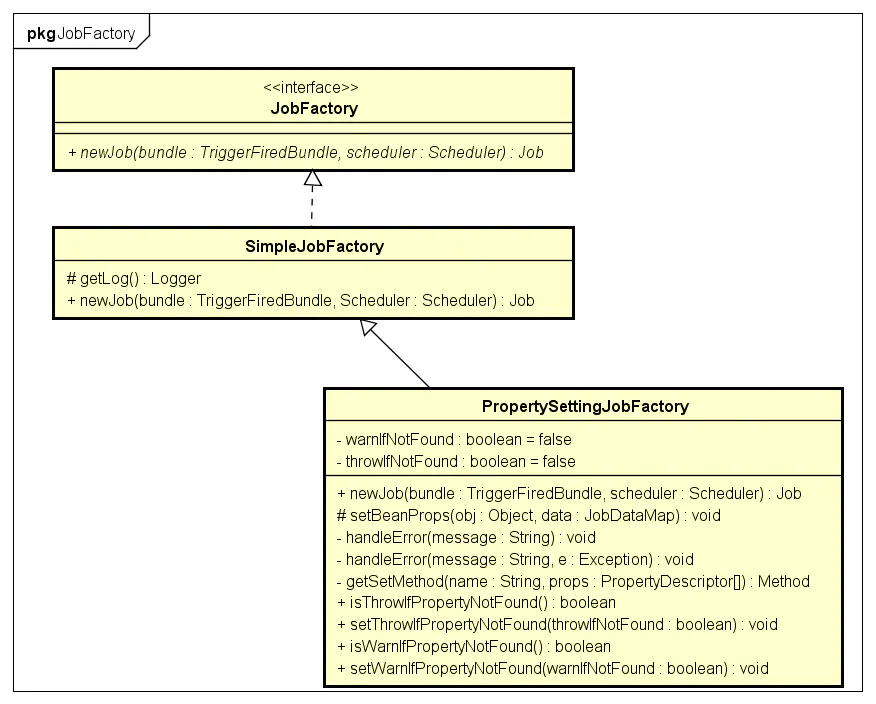
Job Factory结构
Job是在Quartz内部创建,受Scheduler控制,因此不需要外部参与。
JobDetail
JobDetail用于保存Job相关的属性信息
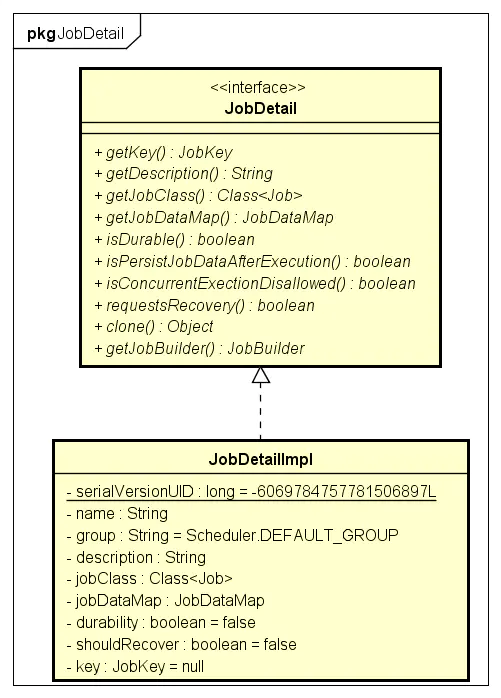
JobDetail结构
- JobKey唯一确定了一个Job
- JobDataMap用于存储Job执行时必要的业务信息
- JobDetail保存的仅仅是Job接口的Class对象,而非具体的实例。
JobBuilder负责JobDetail实例的创建,并且JobBuilder提供了链式操作,可以方便的为JobDetail添加额外的信息。
JobDetail job = JobBuilder.newJob(HelloJob.class)
.withIdentity(jobKey)
.build();
Trigger
Trigger描述了Job的触发规则。

Trigger
- TriggerKey(group,name)唯一标识了Scheduler中的Trigger
- JobKey指向了该Trigger作用的Job
- 一个Trigger仅能对应一个Job,而一个Job可以对应多个Trigger
- 同样的,Trigger也拥有一个JobDataMap
- Priority:当多个trigger拥有相同的触发时间,根据该属性来确定先后顺序,数值越大越靠前,默认5,可为正负数
- Misfire Instructions:没来得及执行的机制。同一时间trigger数量过多超过可获得的线程资源,导致部分trigger无法执行。不同类型的Trigger拥有不同的机制。当Scheduler启动时候,首先找到没来得及执行的trigger,再根据不同类型trigger各自的处理策略处理
- Calendar:Quartz Calendar类型而不是java.util.Calendar类型。用于排除Trigger日程表中的特定时间范围,比如原本每天执行的任务,排除非工作日
Trigger的几种状态
- STATE_WAITING(默认): 等待触发
- STATE_ACQUIRED:
- STATE_COMPLETE:
- STATE_PAUSED:
- STATE_BLOCKED:
- STATE_PAUSED_BLOCKED:
- STATE_ERROR:
Trigger的分类
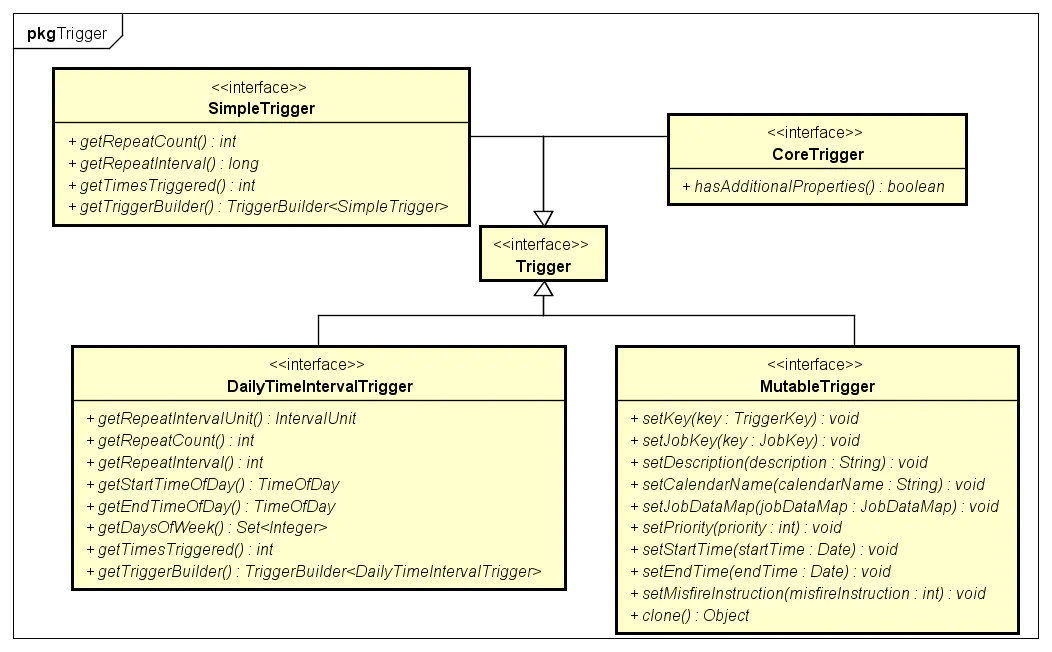
Trigger的分类
常见的两种Trigger为SimpleTrigger和CronTrigger.
SimpleTrigger
SimpleTrigger支持在特定时间点一次性执行或延迟执行N次,使用TriggerBuilder和SimpleScheduleBuilder创建
SimpleTrigger包含的属性为:
- startTime 开始时间
- endTime 如果指定的话,将会覆盖repeat count
- repeat count 重复次数 >=0 int
- repeat interval 时间间隔(毫秒) >=0 long
CronTrigger
CronTrigger支持多次重复性复杂情况,支持Cron表达式,使用TriggerBuilder和CronScheduleBuilder创建。
Cron表达式由7部分组成,分别是秒 分 时 日期 月份 星期 年(可选),空格间隔。
| 字段 | 允许值 | 允许的特殊字符 |
|---|---|---|
| 秒 | 0-59 | , - * / |
| 分 | 0-59 | , - * / |
| 小时 | 0-23 | , - * / |
| 日期 | 1-31 | , - * ? / L W C |
| 月份 | 1-12,JAN-DEC | , - * / |
| 星期 | 1-7,SUN-SAT | , - * ? / L C # |
| 年(可选) | 留空,1970-2099 | , - * / |
特殊字符含义
- "*": 代表所有可能的值
- "/": 用来指定数值的增量, 在子表达式(分钟)里的0/15表示从第0分钟开始,每15分钟;在子表达式(分钟)里的"3/20"表示从第3分钟开始,每20分钟(它和"3,23,43")的含义一样
- "?": 仅被用于天和星期两个子表达式,表示不指定值。当2个子表达式其中之一被指定了值以后,为了避免冲突,需要将另一个子表达式的值设为"?"
- "L": 仅被用于天和星期两个子表达式,它是单词"last"的缩写。如果在“L”前有具体的内容,它就具有其他的含义了。例如:"6L"表示这个月的倒数第6天,"FRI L"表示这个月的最后一个星期五
- 'W' 可用于“日”字段。用来指定历给定日期最近的工作日(周一到周五) 。比如你将“日”字段设为"15W",意为: "离该月15号最近的工作日"。因此如果15号为周六,触发器会在14号即周五调用。如果15号为周日, 触发器会在16号也就是周一触发。如果15号为周二,那么当天就会触发。然而如果你将“日”字段设为"1W", 而一号又是周六, 触发器会于下周一也就是当月的3号触发,因为它不会越过当月的值的范围边界。'W'字符只能用于“日”字段的值为单独的一天而不是一系列值的时候
- 'L'和'W'可以组合用于“日”字段表示为'LW',意为"该月最后一个工作日"。
- '#' 字符可用于“周几”字段。该字符表示“该月第几个周×”,比如"6#3"表示该月第三个周五( 6表示周五而"#3"该月第三个)。再比如: "2#1" = 表示该月第一个周一而 "4#5" = 该月第五个周三。注意如果你指定"#5"该月没有第五个“周×”,该月是不会触发的。
- 'C' 字符可用于“日”和“周几”字段,它是"calendar"的缩写。 它表示为基于相关的日历所计算出的值(如果有的话)。如果没有关联的日历, 那它等同于包含全部日历。“日”字段值为"5C"表示"日历中的第一天或者5号以后",“周几”字段值为"1C"则表示"日历中的第一天或者周日以后"。
表达式举例 - "0 0 12 * * ?" 每天中午12点触发
- "0 15 10 ? * *" 每天上午10:15触发
- "0 15 10 * * ?" 每天上午10:15触发
- "0 15 10 * * ? *" 每天上午10:15触发
- "0 15 10 * * ? 2005" 2005年的每天上午10:15触发
- "0 * 14 * * ?" 在每天下午2点到下午2:59期间的每1分钟触发
- "0 0/5 14 * * ?" 在每天下午2点到下午2:55期间的每5分钟触发
- "0 0/5 14,18 * * ?" 在每天下午2点到2:55期间和下午6点到6:55期间的每5分钟触发
- "0 0-5 14 * * ?" 在每天下午2点到下午2:05期间的每1分钟触发
- "0 10,44 14 ? 3 WED" 每年三月的星期三的下午2:10和2:44触发
- "0 15 10 ? * MON-FRI" 周一至周五的上午10:15触发
- "0 15 10 15 * ?" 每月15日上午10:15触发
- "0 15 10 L * ?" 每月最后一日的上午10:15触发
- "0 15 10 ? * 6L" 每月的最后一个星期五上午10:15触发
- "0 15 10 ? * 6L 2002-2005" 2002年至2005年的每月的最后一个星期五上午10:15触发
- "0 15 10 ? * 6#3" 每月的第三个星期五上午10:15触发
定时器正则表达式验证
秒:^(\\*|[0-5]?[0-9]([,|\\-|\\/][0-5]?[0-9])*)$
分:^(\\*|[0-5]?[0-9]([,|\\-|\\/][0-5]?[0-9])*)$
时:^(\\*|([0-1]?[0-9]?|2[0-3])([,|\\-|\\/]([0-1]?[0-9]|2[0-3]))*)$
日期:^(\\*|\\?|(([1-9]|[1-2][0-9]|3[0-1])([,|\-|\/]([1-9]|[1-2][0-9]|3[0-1]))*)[CLW]?|[CLW]|LW)$
月份:^((\\*|[1-9]|(1[0-2]))([,|\-|\/]([1-9]|(1[0-2])))*)$
星期:^(\\*|L|\\?|[1-7](([,|\-|\/|\#][1-7])*|[LC]))$
年:^(\\*?|2[0-9]{3}([,|\-|\/]2[0-9]{3})*)$
Job Store
Job Store用于保存jobs, triggers等对应数据。JobStore的配置应在Quartz的配置文件中配置,代码中应该避免直接操作JobStore实例
JobStroe的实现包括:
- RAMJobStore:把所有数据保存在内容中,速度快但不能持久化。配置org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore
- JobStoreSupport:通过jdbc,以数据库作为存储媒介
- JobStoreCMT: 使用应用服务器提供事务管理机制
- JobStoreTX: 不依赖与外部容器,可以自己提交、回滚事务

JobStore
RAMJobStore
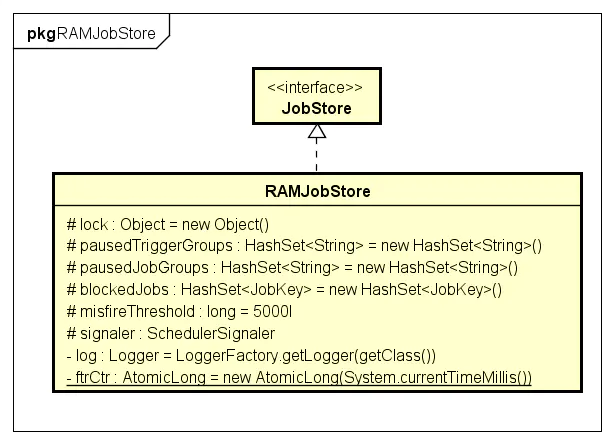
RAMJobStore
JobDetail的存储载体
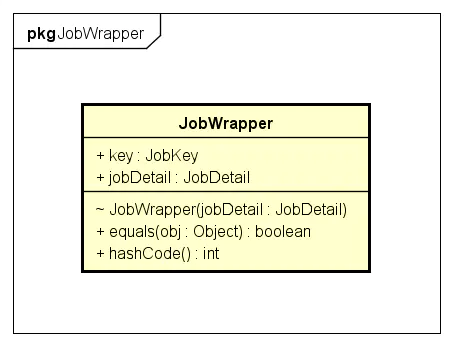
JobWrapper
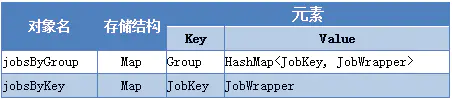
JobWrapper
Trigger的存储载体

TriggerWrapper
// 存储所有的TriggerWrapper
ArrayList<TriggerWrapper> triggers
// 以Trigger的group为key,存储TriggerKey<->TriggerWrapper形式的Map结构的Map
HashMap<String, HashMap<TriggerKey, TriggerWrapper>> triggersByGroup
// 以TriggerKey为Key,存储TriggerWrapper
HashMap<TriggerKey, TriggerWrapper> triggersByKey
// 即将被触发的Trigger
TreeSet<TriggerWrapper> timeTriggers

TriggerWrapper
二、触发器超时后的处理策略
2.1 背景
调度框架不能保证任务的百分百定时执行,所有经过某些原因,任务错过默认的触发时间时,需要有一定的策略去处理。
2.2 关键属性misfireThreshold
在配置quartz.properties有这么一个属性就是misfireThreshold,用来指定调度引擎设置触发器超时的"临界值"。
要弄清楚触发器超时临界值的意义,那么就要先弄清楚什么是触发器超时?打个比方:比如调度引擎中有5个线程,然后在某天的下午2点 有6个任务需要执行,那么由于调度引擎中只有5个线程,所以在2点的时候会有5个任务会按照之前设定的时间正常执行,有1个任务因为没有线程资源而被延迟执行,这个就叫触发器超时。
那么超时的时间又是如何计算的呢?还接着上面的例子说,比如一个(任务A)应该在2点的时候执行,但是在2点的时候调度引擎中的可用线程都在忙碌状态中,或者调度引擎挂了,这都有可能发生,然后再2点05秒的时候恢复(有可用线程或者服务器重新启动),也就是说(任务A)应该在2点执行 但现在晚了5秒钟。那么这5秒钟就是任务超时时间,或者叫做触发器(Trigger)超时时间。
理解了上面的内容再来看misfireThreshold值的意义,misfireThreshold是用来设置调度引擎对触发器超时的忍耐时间,简单来说 假设misfireThreshold=6000(单位毫秒)。
那么它的意思说当一个触发器超时时间如果大于misfireThreshold的值 就认为这个触发器真正的超时(也叫Misfires)。
如果一个触发器超时时间 小于misfireThreshold的值, 那么调度引擎则不认为触发器超时。也就是说调度引擎可以忍受这个超时的时间。
还是 任务A 比它应该正常的执行时间晚了5秒 那么misfireThreshold的值是6秒,那么调度引擎认为这个延迟时间可以忍受,所以不算超时(Misfires),那么引擎会按照正常情况执行该任务。 但是如果 任务A 比它应该正常的执行时间晚了7秒 或者是6.5秒 只要大于misfireThreshold 那么调度引擎就会认为这个任务的触发器超时。
2.3 触发器超时后的处理策略
2.3.1我们在定义一个任务的触发器时 最常用的就是俩种触发器:1、SimpleTrigger 2、CronTrigger。
1、SimpleTrigger 默认的策略是 Trigger.MISFIRE_INSTRUCTION_SMART_POLICY 官方的解释如下:
Instructs the Scheduler that upon a mis-fire situation, the updateAfterMisfire() method will be called on the Trigger to determine the mis-fire instruction, which logic will be trigger-implementation-dependent.
大意是:指示调度引擎在MisFire的状态下,会去调用触发器的updateAfterMisfire的方法来确定它的超时处理策略,里面的逻辑取决于具体的实现类。
那我们在看一下updateAfterMisfire方法的说明:
If the misfire instruction is set to MISFIRE_INSTRUCTION_SMART_POLICY, then the following scheme will be used: If the Repeat Count is 0, then the instruction will be interpreted as MISFIRE_INSTRUCTION_FIRE_NOW. If the Repeat Count is REPEAT_INDEFINITELY, then the instruction will be interpreted as MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT. WARNING: using MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT with a trigger that has a non-null end-time may cause the trigger to never fire again if the end-time arrived during the misfire time span. If the Repeat Count is > 0, then the instruction will be interpreted as MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT.
大意是:
1、如果触发器的重复执行数(Repeat Count)等于0,那么会按这个(MISFIRE_INSTRUCTION_FIRE_NOW)策略执行。
2、如果触发器的重复执行次数是 SimpleTrigger.REPEAT_INDEFINITELY (常量值为-1,意思是重复无限次) ,那么会按照MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT策略执行。
3、如果触发器的重复执行次数大于0,那么按照 MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT执行。
既然是这样,那就让我们依次看一下每种处理策略都是啥意思!
1、MISFIRE_INSTRUCTION_FIRE_NOW
Instructs the
that upon a mis-fire situation, theSchedulerwants to be fired now bySimpleTriggerScheduler.NOTE: This instruction should typically only be used for 'one-shot' (non-repeating) Triggers. If it is used on a trigger with a repeat count > 0 then it is equivalent to the instruction
.MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_REPEAT_COUNT
指示调度引擎在MisFire的情况下,将任务(JOB)马上执行一次。
需要注意的是 这个指令通常被用做只执行一次的Triggers,也就是没有重复的情况(non-repeating),如果这个Triggers的被安排的执行次数大于0
那么这个执行与 (4)MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_REPEAT_COUNT 相同
2、MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT
|
|
|
指示调度引擎重新调度该任务,repeat count保持不变,并且服从trigger定义时的endTime,如果现在的时间,如果当前时间已经晚于 end-time,那么这个触发器将不会在被激发。
注意:这个状态会导致触发器忘记最初设置的 start-time 和 repeat-count,为什么这个说呢,看源代码片段:updateAfterMisfire方法中
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
getTimesTriggered的是获取这个触发器已经被触发了多少次,那么用原来的次数 减掉 已经触发的次数就是还要触发多少次
接下来就是判断一下触发器是否到了结束时间,如果到了的话,触发器就不会在被触发。
然后就是重新设置触发器的开始实现是 “现在” 并且立即运行。
3、MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT
| 1 2 3 |
|
这个策略跟上面的2策略一样,唯一的区别就是设置触发器的时间 不是“现在” 而是下一个 scheduled time。解释起来比较费劲,举个例子就能说清楚了。
比如一个触发器设置的时间是 10:00 执行 时间间隔10秒 重复10次。那么当10:07秒的时候调度引擎可以执行这个触发器的任务。那么如果是策略(2),那么任务会立即运行。
那么触发器的触发时间就变成了 10:07 10:17 10:27 10:37 .....
那么如果是策略(3),那么触发器会被安排在下一个scheduled time。 也就是10:20触发。 然后10:30 10:40 10:50。这回知道啥意思了吧。
4、MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_REPEAT_COUNT
这个策略跟上面的策略(2)比较类似,指示调度引擎重新调度该任务,repeat count 是剩余应该执行的次数,也就是说本来这个任务应该执行10次,但是已经错过了3次,那么这个任务就还会执行7次。
下面是这个策略的源码,主要看红色的地方就能看到与策略(2)的区别,这个任务的repeat count 已经减掉了错过的次数。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|
5、MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT
| 1 2 3 |
|
这个策略与上面的策略3比较类似,区别就是repeat count 是剩余应该执行的次数而不是全部的执行次数。比如一个任务应该在2:00执行,repeat count=5,时间间隔5秒, 但是在2:07才获得执行的机会,那任务不会立即执行,而是按照机会在2点10秒执行。
6、MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY
|
|
|
这个策略是忽略所有的超时状态,和最上面讲到的 (第二种情况) 一致。
举个例子,一个SimpleTrigger 每个15秒钟触发, 但是超时了5分钟才获得执行的机会,那么这个触发器会被快速连续调用20次, 追上前面落下的执行次数。
2.3.2、CronTrigger 的默认策略也是Trigger.MISFIRE_INSTRUCTION_SMART_POLICY
官方解释如下,也就是说不指定的话默认为:MISFIRE_INSTRUCTION_FIRE_ONCE_NOW。
| 1 2 3 4 |
|
1、MISFIRE_INSTRUCTION_FIRE_ONCE_NOW
| 1 |
|
这个策略指示触发器超时后会被立即安排执行,看源码,红色标记的地方。也就是说不管这个触发器是否超过结束时间(endTime) 首选执行一次,然后就按照正常的计划执行。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
2、MISFIRE_INSTRUCTION_DO_NOTHING
这个策略与策略(1)正好相反,它不会被立即触发,而是获取下一个被触发的时间,并且如果下一个被触发的时间超出了end-time 那么触发器就不会被执行。
上面绿色标记的地方是源码
补充几个方法的说明:
1、getFireTimeAfter 返回触发器下一次将要触发的时间,如果在给定(参数)的时间之后,触发器不会在被触发,那么返回null。
| 1 2 |
|
2、isTimeIncluded 判断给定的时间是否包含在quartz的日历当中,因为quartz是可以自定义日历的,设置哪些日子是节假日什么的。
| 1 2 |
|
三、踩坑记录
Scheduler不要使用@Autowired自动注入,要使用创建StdSchedulerFactory类对象进行获取,因为自动注入的Scheduler的misfireThreshold默认是5000ms,而通过StdSchedulerFactory类对象获取的Scheduler,misfireThreshold的值是60000ms。


















 1526
1526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











