






实验目标
1、选取3-5个代表性的新闻网站(比如新浪新闻、网易新闻等,或者某个垂直领域权威性的网站比如经济领域的雪球财经、东方财富等,或者体育领域的腾讯体育、虎扑体育等等)建立爬虫,针对不同网站的新闻页面进行分析,爬取出编码、标题、作者、时间、关键词、摘要、内容、来源等结构化信息,存储在数据库中。
2、建立网站提供对爬取内容的分项全文搜索,给出所查关键词的时间热度分析。
实验内容
本项目实现了一个新闻检索与可视化网页,利用node.js爬取了四大主流的新闻网站,并构建了数据库,利用express+vue3构建了一个简明的新闻展示网页。
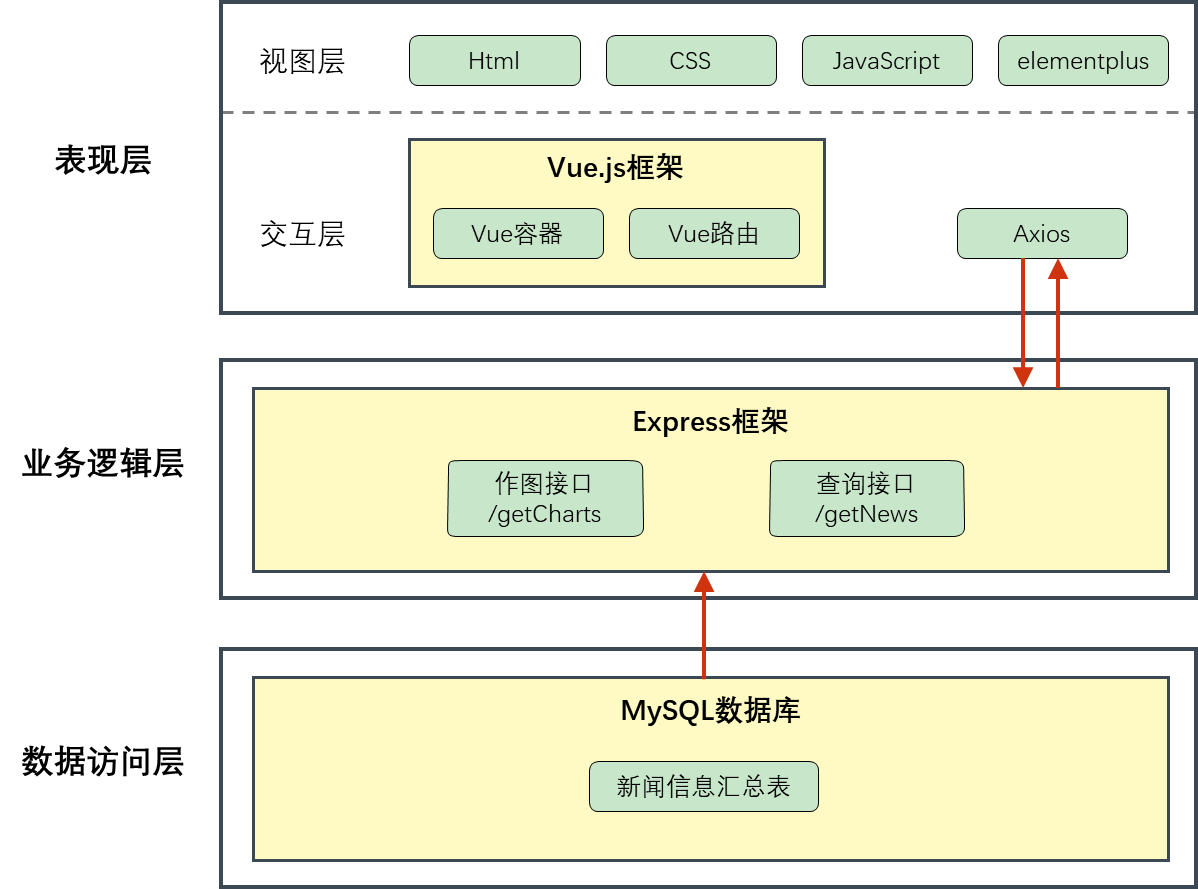
本项目的系统架构主要分为三层,分别为表现层、业务逻辑层、数据访问层。从下往上,数据访问层主要是由node.js爬取出的新闻信息汇总成的mysql信息表,业务逻辑层是由Express框架组成的,包含作图接口和查询接口,表现层的视图层由三剑客和elementplus构成,交互层由vue.js框架中的vue容器和vue路由构成。当由查询或者作图的请求到来时,表现层通过Axios将相应的参数传给后端,由不同的接口生成不同的命令从数据库里获取想要的信息,最后通过axois传回给前端。
实验步骤
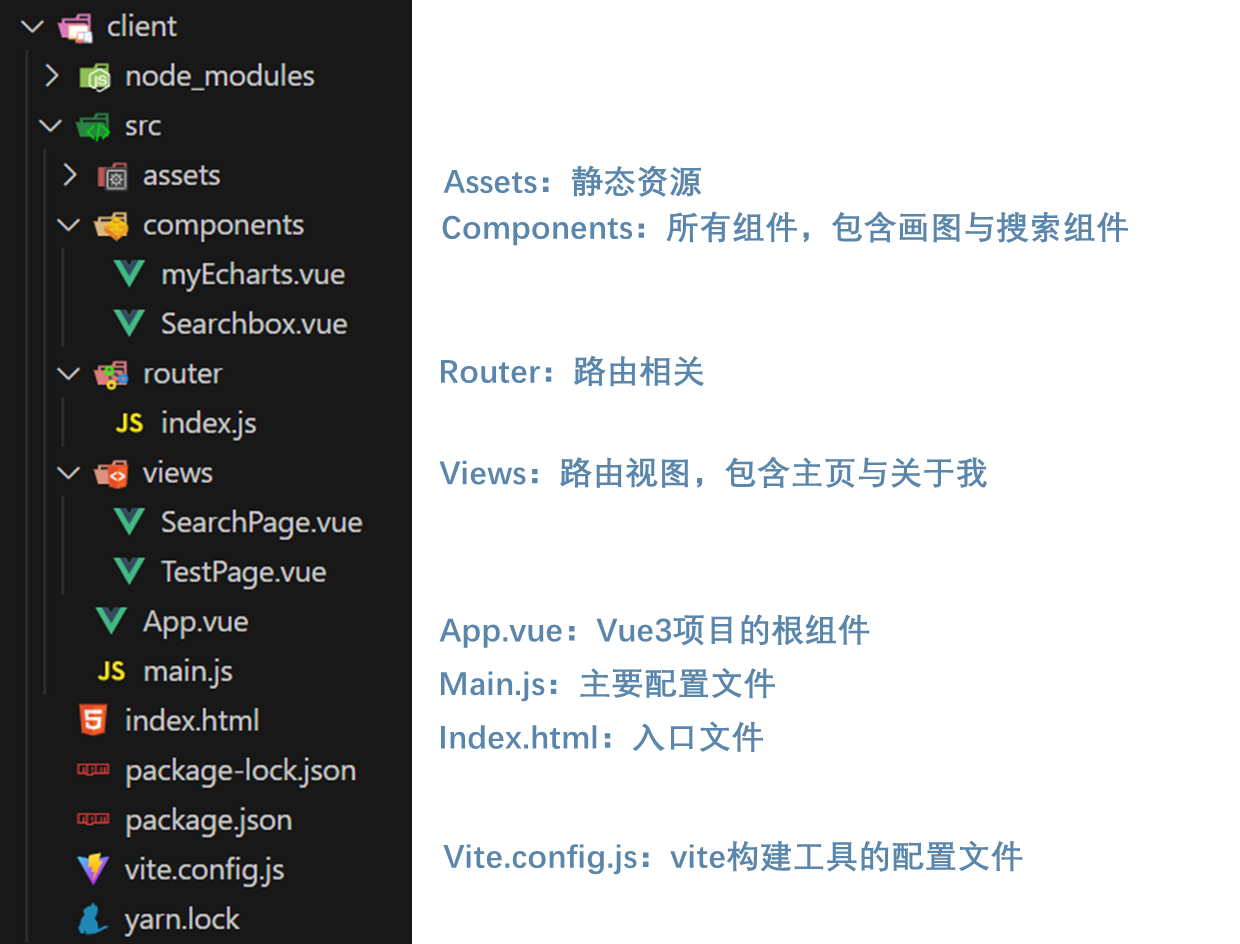
项目文件结构如下,client为前端,sever为后端,crawler为爬虫。
node.js爬虫
爬虫部分爬取了中国新闻网、腾讯新闻、网易新闻、新浪新闻四个主流的新闻网站中的URL、来源、编码、标题、关键词、原作者、发布日期、爬取时间、正文等信息,并存入MySQL数据库。
静态网页——以中国新闻网为例
中国新闻网和新浪新闻网这类静态加载的网页,它们首页上的全部新闻是一开始就加载在页面中的,因此,只需要爬取首页中所有的超链接
a
a
a。

但要注意的是,网页中存在下图这样的非新闻内容,因此,我们需要对爬取到的url进行筛选,筛序出符合一定规则的url。

因此,代码部分如下:
首先需要对request函数进行包装,使之包含timeout和timeout等信息
//request模块异步fetch url
var myRequest = require('request'); // 发送HTTP请求
function request(url, callback) {
var options = {
url: url,
encoding: null,
//proxy: 'http://x.x.x.x:8080',
headers: headers,
timeout: 2000 //
}
myRequest(options, callback)
};
主函数seedget()首先使用request模块发送一个HTTP请求,读取种子页面的内容。然后,使用iconv模块将字节流转换为指定的编码格式。接下来,使用cheerio模块解析HTML内容。之后,调用newsGet(myurl)爬取分页面信息,并存入数据库。
function seedget() {
request(seedURL, function(err, res, body) { //读取种子页面
if (typeof body=='undefined') return
try {
//用iconv转换编码,原本body为字节流
var html = myIconv.decode(body, myEncoding);
//准备用cheerio解析html
var $ = myCheerio.load(html, { decodeEntities: true });
} catch (e) {
console.log('读种子页面并转码出错:' + e)
}
var seedurl_news;
try {
seedurl_news = eval(seedURL_format);
} catch (e) {
console.log('url列表所处的html块识别出错:' + e)
};
seedurl_news.each(function(i, e) { //遍历种子页面里所有的a链接
var myURL = "";
try {
//得到具体新闻url
var href = "";
href = $(e).attr("href");
if (href == undefined) return;
if (href.toLowerCase().indexOf('http://') >= 0 || href.toLowerCase().indexOf('https://') >= 0) myURL = href; //http://开头的
else if (href.startsWith('//')) myURL = 'http:' + href; // //开头的
else myURL = seedURL.substr(0, seedURL.lastIndexOf('/') + 1) + href; //其他
} catch (e) { console.log('识别种子页面中的新闻链接出错:' + e) }
if (!url_reg.test(myURL)) return; //检验是否符合新闻url的正则表达式
if (myURL.indexOf("/tp/")>=0) return
console.log(myURL)
var fetch_url_Sql = 'select url from fetches where url=?';
var fetch_url_Sql_Params = [myURL];
mysql.query(fetch_url_Sql, fetch_url_Sql_Params, function(qerr, vals, fields) {
if (vals.length > 0) {
console.log('URL duplicate!')
return
}
else {
newsGet(myURL); //读取新闻页面
}
});
newsGet(myURL)
});
});
};
seedget()和newsGet(myURL)仅在课程代码的基础上进行了较少的修改,主要是修改cheerio选择器,因此不多赘述。
var seedURL_format = "$('a')";
var keywords_format = " $('meta[name=\"keywords\"]').eq(0).attr(\"content\")"; //
var title_format = "$('title').text()";
var date_format = "$('#pubtime_baidu').text();";
var data_format1 = "$('#newsdate').attr(\"value\")"; // 增加匹配方式
var author_format = "$('#editor_baidu').text()";
var author_format1="$('p.editor').eq(0).text()" // 增加匹配方式
var content_format = "$('div.left_zw > p').text()";
动态网页——以网易为例
动态加载的网页页面中的元素并不是一开始就加载在页面上的。

通过点击加载更多或者是向下滑动滚轮时,能捕捉到一个写有此次加载内容的数据包,其中包含包含title、URL、keywords等我们想要的信息。


通过这个我们抓到的包中的url,我们可以以一种较为曲折的方式得到分页面的URL。
由于使用我们一开始的爬虫的话会出现很多爬虫并发的情况,不便于观察每个爬虫可能出现的问题,而动态加载的页面又比较复杂容易出错,所以,我们改进了爬虫以每个数据包中的新闻为一批,一批爬完后再开始下一批。
具体的做法是在seedNews函数中,将原来解析HTML内容的功能放进函数getURL(err, res, body),将主体改为递归的形式:
function seedget() {
var i=0
function getURL(err, res, body){
...
}
function requestNews(seedURL){
console.log(i+1,"----------------------------------------")
if (i!=0 && (i+1).toString()==1){
seedURL = 'https://news.163.com/special/cm_yaowen20200213_0'+(i+1).toString()+'/?callback=data_callback';
console.log(seedURL)
}
else if (i!=0 && (i+1).toString()==2){
seedURL = 'https://news.163.com/special/cm_yaowen20200213_'+(i+1).toString()+'/?callback=data_callback';
console.log(seedURL)
}
request(seedURL, getURL);
}
requestNews(seedURL)
};
Exress后端
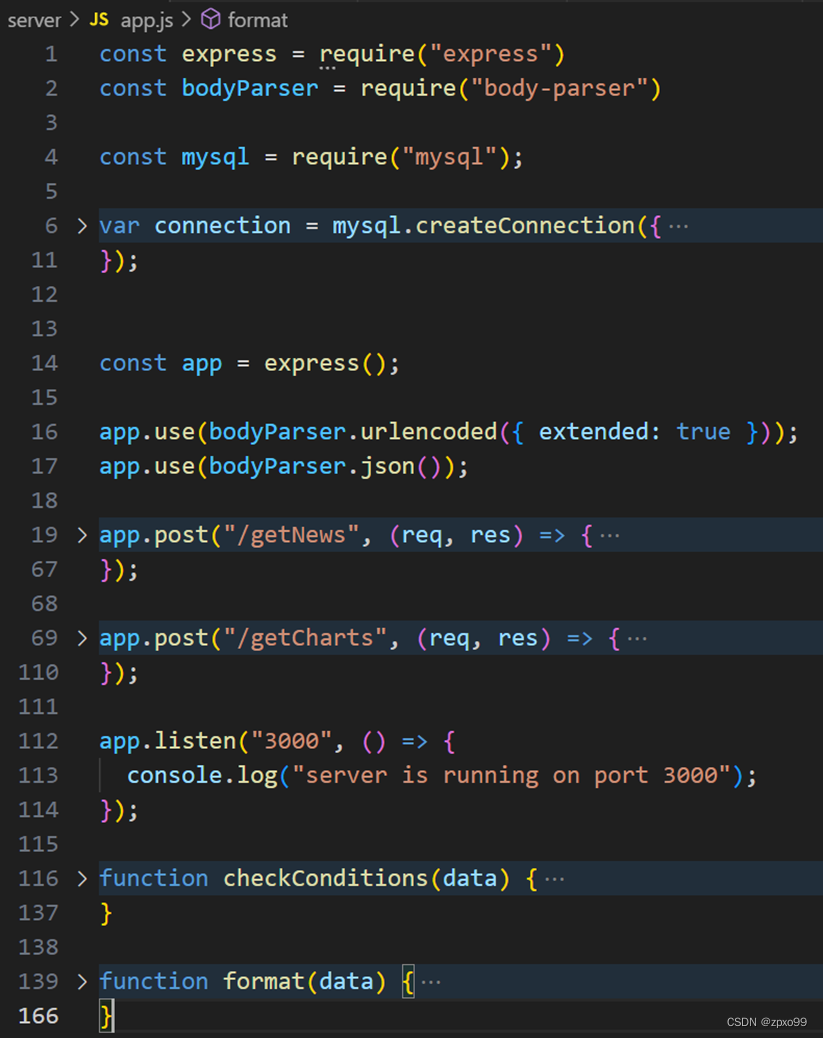
后端的主要代码在./server/app.js中:
- 创建了一个服务器,监听在3000端口上
- 两个路由,分别是/getNews和/getCharts。
在**/getNews**路由中,接收一个POST请求,请求体中包含一些条件。首先将这些条件转换为一个SQL查询语句,然后通过连接到MySQL数据库执行查询。如果查询结果为空,则返回一个包含错误信息的JSON响应;否则,返回一个包含查询结果的JSON响应。
/getNews路由中,需要处理标题、关键字、原作者等字段中以空格分隔的请求,将其解析为多条要求,以此实现多关键词的搜索,整理出形似下面的SQL命令。

app.post("/getNews", (req, res) => {
var fetchSQL = "SELECT * FROM fetches WHERE ";
var conditions = Object.values(eval(req.body));
conditions = checkConditions(conditions);
if (conditions.length <= 0) {
res.send({
errorNo: 1001,
errorMsg: "Conditions Error",
});
return;
}
fetchSQL+=(format(conditions[0])+' ')
if (conditions.length > 1) {
for (let i = 1; i < conditions.length; i++) {
fetchSQL+=(' AND '+format(conditions[i])+' ')
}
}
fetchSQL += ";";
console.log(fetchSQL);
connection.query(fetchSQL, function (err, result) {
if (result.length <= 0) {
res.send({
errorNo: 1002,
errorMsg: "No Data",
});
return;
} else {
res.send({
errorNo: 0,
data: result,
});
}
});
});
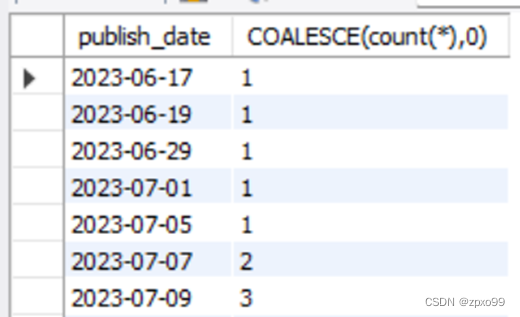
在**/getCharts**路由中,执行类似的操作,但是查询的结果是按照publish_date字段进行分组和排序的。

app.post("/getCharts", (req, res) => {
var fetchSQL = "SELECT publish_date,count(*) FROM fetches WHERE ";
var conditions = Object.values(eval(req.body));
conditions = checkConditions(conditions);
if (conditions.length <= 0) {
res.send({
errorNo: 1001,
errorMsg: "Conditions Error",
});
return;
}
console.log(conditions)
fetchSQL+=(format(conditions[0])+' ')
if (conditions.length > 1) {
for (let i = 1; i < conditions.length; i++) {
fetchSQL+=(' AND '+format(conditions[i])+' ')
}
}
fetchSQL+='group by publish_date order by publish_date;'
console.log(fetchSQL);
connection.query(fetchSQL, function (err, result) {
if (result.length <= 0) {
res.send({
errorNo: 1002,
errorMsg: "No Data",
});
return;
} else {
res.send({
errorNo: 0,
data: result,
});
}
});
});
Vue前端
前端架构如下:
vite.config.js中设置提供后端服务的url:
import { defineConfig } from "vite";
import vue from '@vitejs/plugin-vue'
export default defineConfig({
plugins:[vue()],
resolve:{
extensions:['.vue','.js','.jsx','.ts','.tsx'],
},
server:{
proxy:{
'/api':{
target:'http://localhost:3000',
changeOrigin:true,
rewrite: path=>path.replace(/^\/api/,'')
}
}
}
});
./src/App.js中写有共用的菜单组件与背景,并且还包含相应的路由逻辑:
<template>
<div>
<el-header>
<el-menu
:default-active="activeIndex"
class="el-menu-demo"
mode="horizontal"
@select="handleSelect">
<el-menu-item index="1" style="font-size: 20px">新闻搜索与可视化分析</el-menu-item>
<el-menu-item index="2" style="font-size: 20px">关于我</el-menu-item>
</el-menu>
</el-header>
<div id="wrap">
<div style="background-color:rgba(255,255,255,0.85); height: 100%;overflow: scroll; width: 100%">
<router-view> </router-view>
</div>
</div>
</div>
<!-- 路由导向的vue渲染标签 -->
</template>
<script setup>
import { ref } from "vue";
import { useRouter } from "vue-router";
const router=useRouter()
const activeIndex = ref('1');
const handleSelect = (index) => {
if(index=='1'){
router.push({
name:'home',
})
}
if(index=='2'){
router.push({
name:'test',
})
}
}
</script>
./src/router/index.js中写的是路由逻辑,用于实现路径的跳转和组件的加载。
import { createRouter,createWebHistory ,useRouter} from "vue-router";
// 编写路由函数,路径的跳转
const router=createRouter({
history: createWebHistory(),
routes:[
{
name:'home',
path:'/',
component:()=>import('../views/SearchPage.vue')
},
{
name:'test',
path:'/test',
component:()=>import('../views/TestPage.vue')
}
]
})
export default router
./views中是两个路由视图
SearchPage是主页面,包含Searchbox子组件、table组件、pagination组件和myEcharts组件。
<div>
<searchbox @searchChange="handlequery" @adChange="handladequery" @getChart="handlecharts"></searchbox>
<div v-if="!isDraw">
<el-table :v-show="isShow.value && isDraw.value" :data="tableData" stripe style="width: 80%" class="searchtable"...
</el-table>
<el-pagination :current-page="page.pageNum" :page-size="page.pageSize" :page-sizes="[5, 10, 20]"
layout="sizes, prev, pager, next, jumper" :total="total" @size-change="handleSizeChange"
@current-change="handleCurrentChange" class="pag" />
</div>
<div v-if="isDraw">
<myEcharts :echartsdata="echartsdata"></myEcharts>
</div>
</div>
</template>
SearchPage还包含一些辅助函数:
- handleSizeChange(val), handleCurrentChange(val), getpage():分页
- handlequery(query):处理简单搜索
- handladequery(query):处理高级搜索
- handlecharts(query):处理作图请求
- formatechartsdata(data):处理并补全时间序列
功能
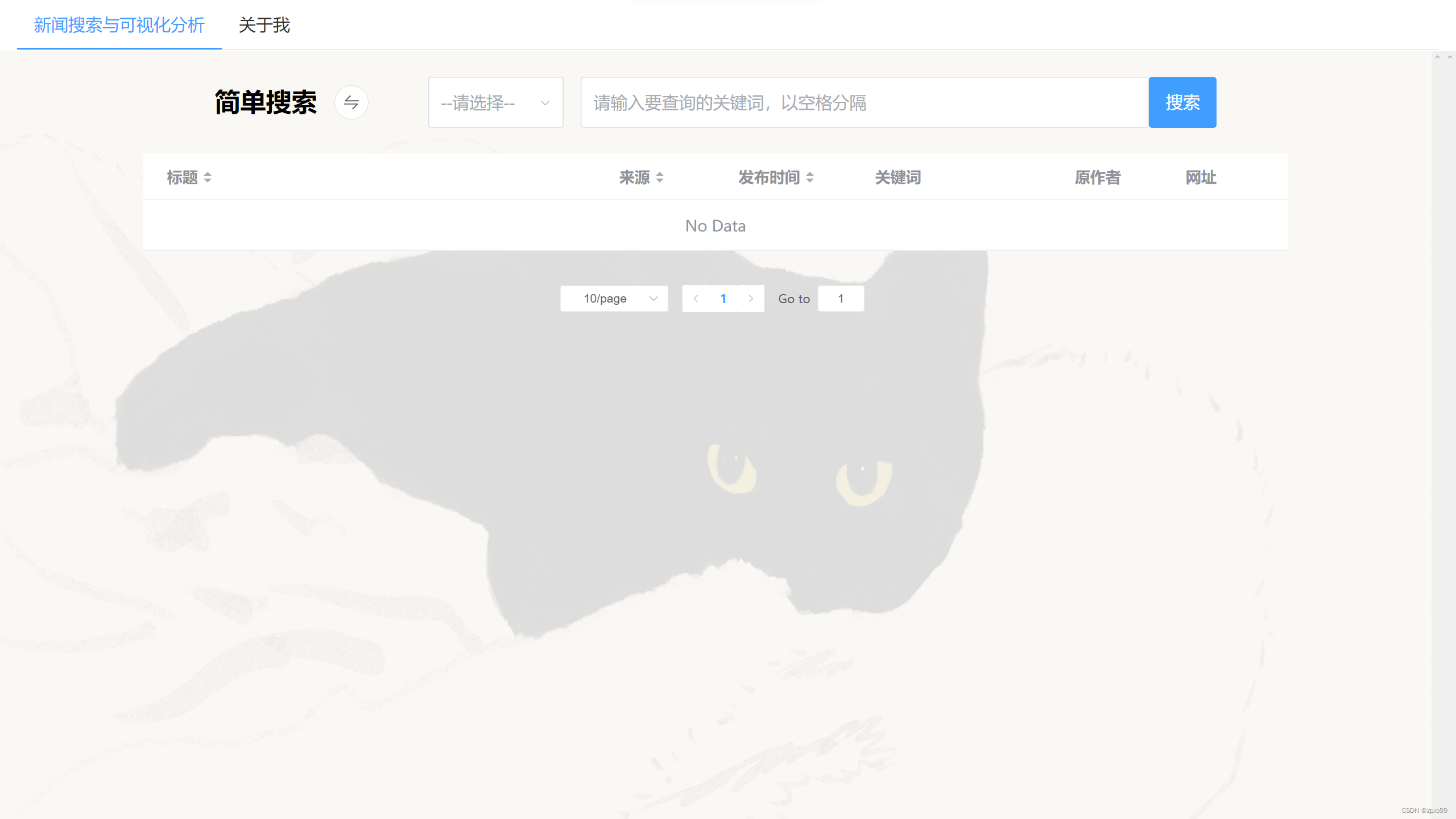
运行前后端,可以进入简单搜索,初始网页如下,显示的是No Data:
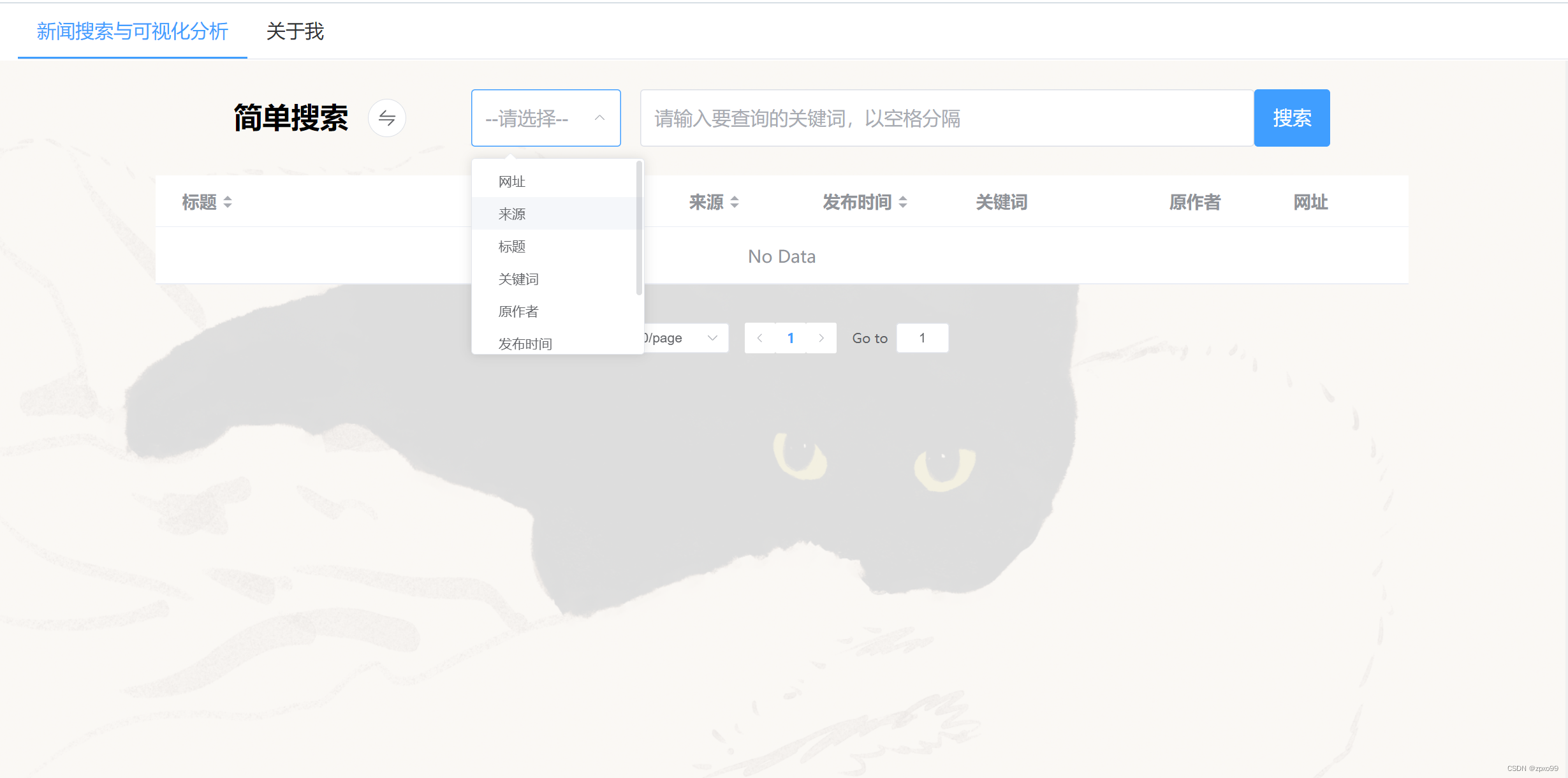
可以选择就任一选项进行搜索
点击搜索,搜到如下结果:

图表中包含标题、来源、发布时间、关键词、原作者等信息,点击跳转可以跳转到源网页,点击右边的三角可以收放原文。此外,还可以根据标题、来源、发布时间等排序。

在页面下方可以选择每页新闻的条数,并跳转到相应的页。

点击上方的转换按钮可以切换到高级搜索,可以进行复合搜索
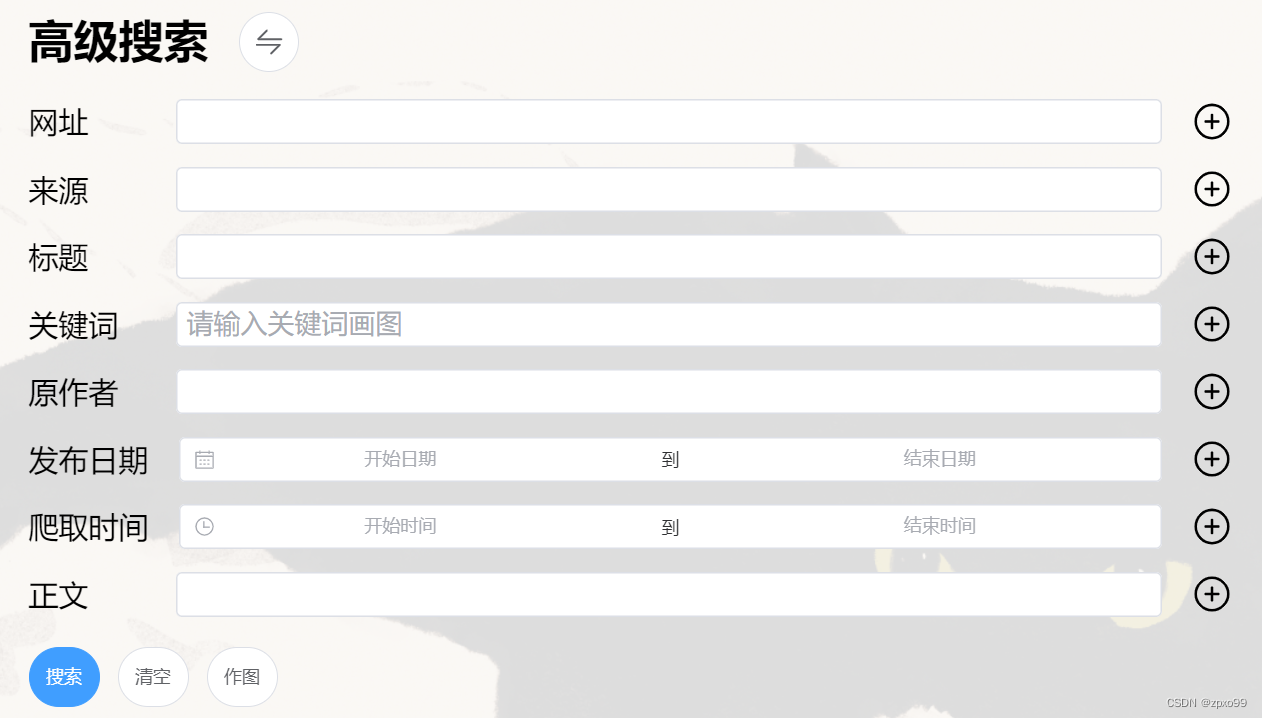
输入关键词,点击加号可以添加标签。

发布时间与爬取时间等条目还支持时间范围搜索。

点击搜索可以搜索到以下结果:

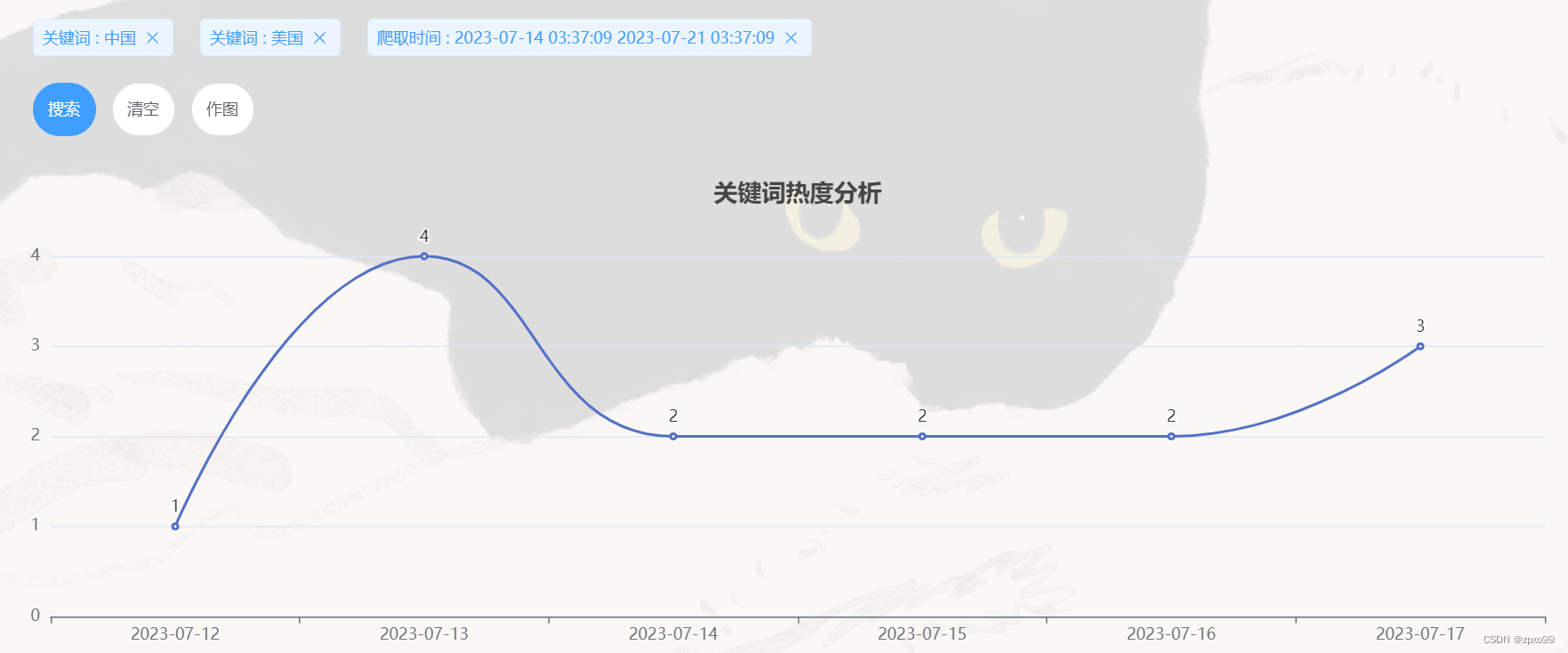
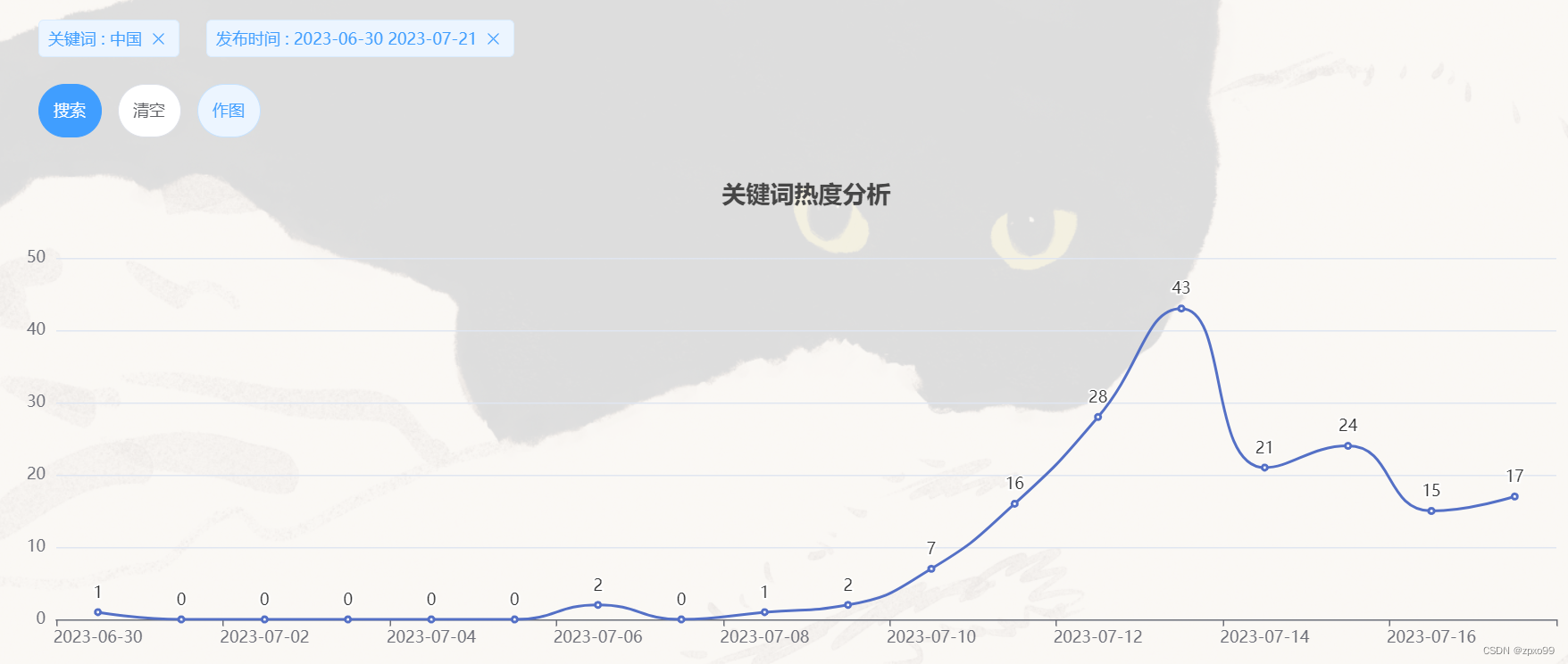
点击作图可以得到以下结果:
最后是关于我界面,有可爱的猫娘哦!!

最后的最后
在做这个项目的时候,@tuziTZ给了我很多陪伴和帮助,真的非常感谢喵~o( =∩ω∩= )m,希望大家也去看看她的喵=>(传送门)















 729
729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









