







一、选择题(本大题共 10 小题,每小题2分,共20分)
1、下列查找方法中,( )适用于查找有序单链表。
A.分块查找; B.哈希查找; C.顺序查找; D.二分查找;
线性表的查找有顺序查找和二分法查找两种。由于链表不能随机访问,要访问某个结点,必须从它的直接前驱的指针域出发才能找到。因此,链式存储的线性表,即使是有序表,也只能使用顺序查找。
2、在有n个结点的二叉树的二叉链表表示中,空指针数为( )。
A.不定; B.n+1; C.n; D.n-1;
3、在下列排序方法中,( )方法所有情况下时间复杂度均为O(nlogn)。
A.希尔排序; B.堆排序; C.快速排序; D.直接插入排序;
希尔排序的时间复杂度——O(n^(3/2))
堆排序的时间复杂度——O(nlogn)
快速排序的时间复杂度——最好情况O(nlog2n) 最坏情况O(n^2/2) 平均O(nlog2n)
直接插入排序的复杂度——O(n^2)
4、设有一个n^n的对称矩阵A,将其下三角部分按行存放在一个一维数组B中,A[0][0]存放于B[0]中,那么对角元素A[i][i]存放于B中( )处。
A. (i+3)*i/2 B. (i+1)*i/2
C. (2n-i+1)*i/2 D. (2n-i-1)*i/2
首先,我们要知道什么是下三角。题目要求按行存放,第一行有一个元素,第二行有两个元素,第三行有三个元素……A[0][0]->B[0],A[1][0]->B[1],A[1][1]->B[2],A[2][0]->B[3],A[2][1]->B[4],A[2][2]->B[5]……就这么列几个其实就可以得到答案了,直接硬算就好。

5、已知一组待排序的记录关键字初始排列如下:45,34,87,25,67,43,11,66,27,78。快速排序法一趟排序的结果为( )。
A.34,45,25,67,43,11,66,27,78,87 B.87,45,11,25,34,78,27,66,67,43
C.27,34,11,25,43,45,67,66,87,78 D.34,11,27,25,43,78,45,67,66,87
快排的步骤可参考scau 8642 快速排序_zqihm的博客-CSDN博客
6、若某二叉树有15个叶子结点,有15个结点仅有一个孩子,则该二叉树的总结点数是( )。
A. 42 B. 44 C. 45 D. 46
设度为0的结点个数为N0=15,度为1的结点个数为N1=15,度为2的结点个数为N2
总度和=结点个数-1(这是解题关键,详情自行搜索)
由此可得 15*0+15*1+N2*2=15+15+N2-1
解 得 N2=14
7、设n个元素进栈序列是x1,x2,x3,…,xn,其输出序列是1,2,3,…,n,若x3=3,则x1的值( )。
A. 可能是2 B. 不可能是1 C. 一定是2 D. 一定是1
8、在一个单链表中,若要在当前由指针p指向的结点后面插入一个由q指向的结点,则执行如下( )语句序列。
A. p=q; p->next=q; B. p->next=q; q->next=p;
C. p->next=q->next; p=q; D. q->next=p->next; p->next=q;
9、串"aababaabacab"的next数组为( )
A. 011212345123 B. 012112345123
C. 012121234512 D. 012341123412
10、对下图所示的无向图,从顶点1开始进行深度优先遍历;可得到顶点访问序列是( )

A.1 2 4 3 5 7 6 B.1 2 4 3 5 6 7 C.1 2 4 5 6 3 7 D.1 2 3 4 5 7 6
不参考也行,这题不难
二、应用题(本大题共 5 小题,每小题6分,共30分,要求写出解题过程)
1、假设一棵二叉树的层次遍历序列为ABCDEFG,中序遍历序列为DBGEACF。(1)请画出这棵二叉树;(2)请写出这棵二叉树的后序遍历序列。
层次遍历——一层一层的
中序遍历——先左再根再右
A为根结点,DBGE为左子树,CF为右子树……
元素不多,自己挨个演算就行
答案:
2、对于如下的连通图,请给出从顶点0出发,利用普里姆(Prim)算法得到它的最小生成树,画出所得到的最小生成树,并求出最小生成树的权。

普里姆算法——课本上有详细说明(P160)
每次找权值最小的边即可

3、设哈希函数为H(key)=key MOD 13, 散列地址为0–14,用线性探测再散列的方法处理冲突。(1) 请画出依次插入元素23,34,56,24,75,12,49, 52,36,92,06,55后,该哈希表的状态(即,将各元素插入下表的对应地址);(2) 假设查找每个元素的概率相同,求出查找成功时的平均查找长度。 
哈希表——课本P216
key MOD 13,其中MOD为取模运算——m MOD n=m-n[m/n] (中括号为取整函数,向下取整,即取不大于、最接近m/n的整数)
若散列地址发生冲突,后面冲突的地址加1;若取模运算得到负值,该负值加上表的最大下标即可(这里最大下标为14)
4、有一份电文中共使用了七种字符:A、B、C、D、E、F、G,它们出现的次数分别为12,7,20,9,14,17,21,试构造一棵哈夫曼树(请按左子树根结点的权小于等于右子树根结点的权的次序构造),并给出哈夫曼编码。
答案: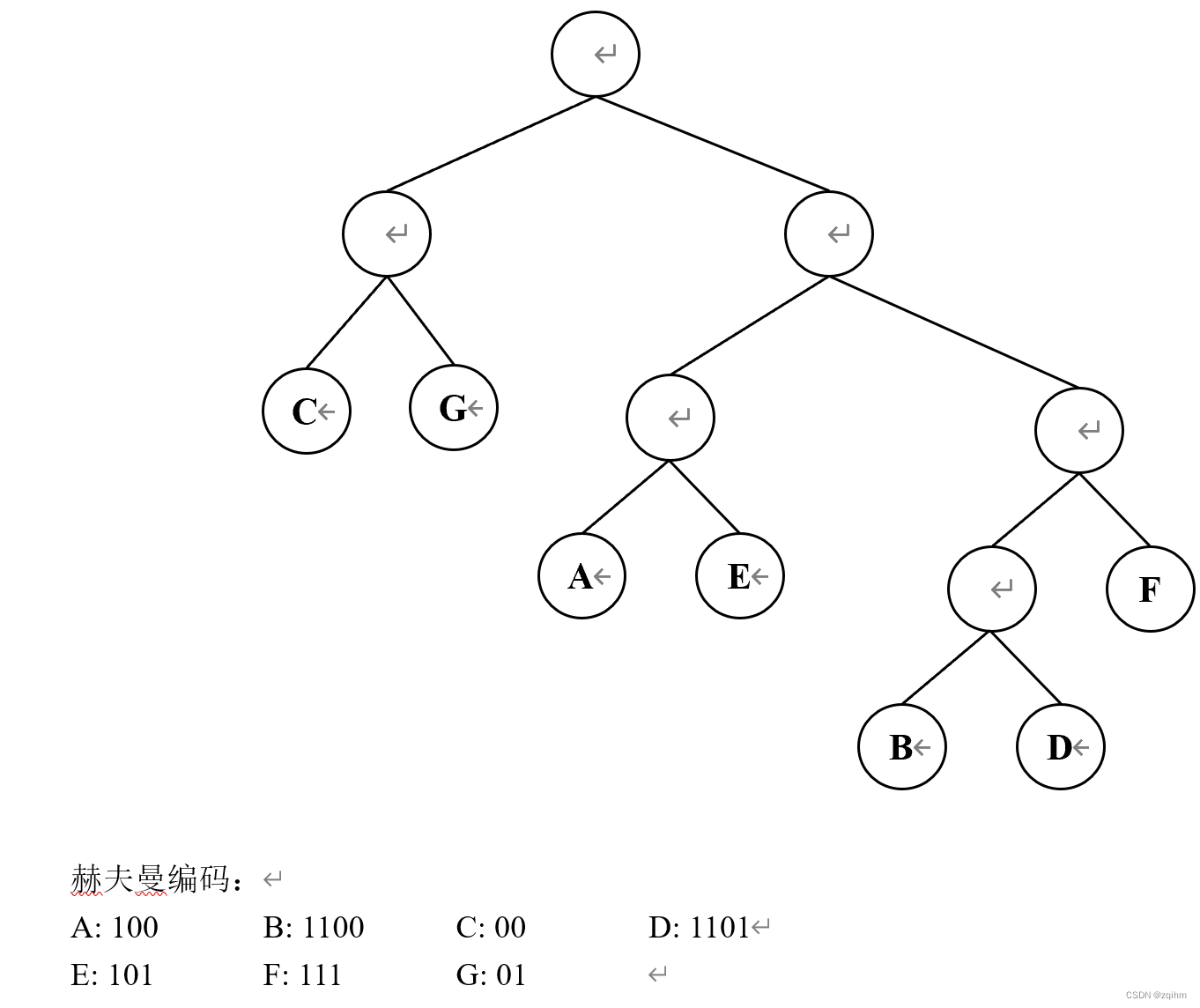
5、已知某有向图的邻接表存储结构如图所示。
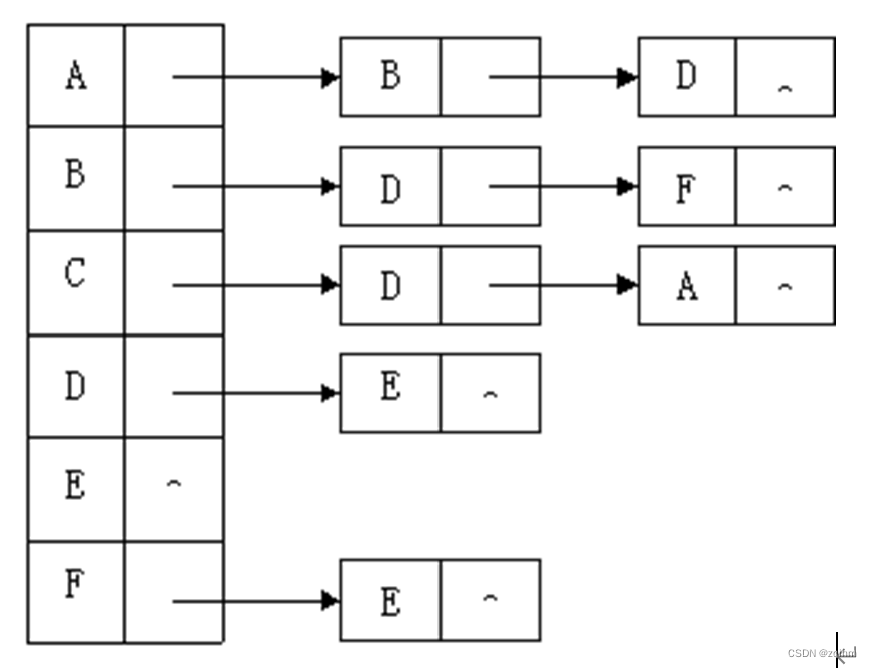
(1).请画出该图。
(2).根据存储结构给出其深度优先遍历序列及广度优先遍历序列(从结点C出发)。
答案: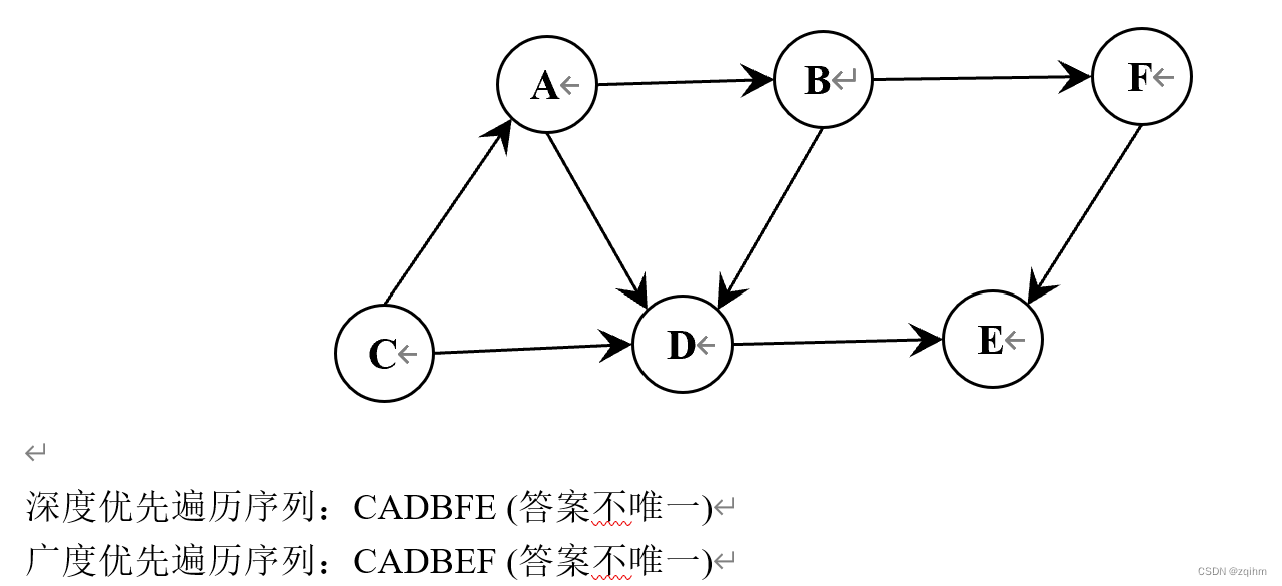
四、算法设计题(本大题共 2小题,每小题10分,共20分。请先简要说明算法思想,然后写出算法的C语言源代码实现)
1、设计一个算法deleteMinNode(LinkList &L),在带头结点的单链表L中删除所有结点值最小的结点(可能有多个结点值最小的结点)。
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode, *LinkList;答案:
用p从头至尾扫描单链表,pre指向*p结点的前驱,用minp保存
值最小的结点指针,minpre指向*minp结点的前驱。一面扫描,
一面比较,将最小值的结点放到*minp中。算法如下:
void deleteMinNode (LinkList &L)
{
LinkList pre=L, p=pre->next, minp=p, minpre=pre;
ElemType mindata=p->data;
while (p!=NULL && p->data<mindata)
{ mindata=p->data;
p=p->next;
}
p=pre->next;
while (p!=NULL)
{
if (p->data==mindata)
{ pre->next=p->next;
free(p);
}
pre=pre->next;
p=pre->next;
}
}2、二叉树用二叉链表存储表示。
typedef struct BiTNode
{
TelemType data;
Struct BiTNode *lchild, *rchild;
} BiTNode, *BiTree;
编写一个复制一棵二叉树的递归算法。
统一使用如下函数名:BiTree CopyTree(BiTree T)答案:
BiTree CopyTree(BiTree T) {
if (!T ) return NULL;
if (!(newT = (BiTNode*)malloc(sizeof(BiTNode))))
exit(Overflow);
newT-> data = T-> data;
newT-> lchild = CopyTree(T-> lchild);
newT-> rchild = CopyTree(T-> rchild);
return newT;
}
别担心~本人刚开始做的时候也很懵,做多两套卷子就不会懵啦,基本的规律套路在这儿呢,期末加油~















 3699
3699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









