







 本文介绍了在爬取租房网站时遇到的数字加密问题,通过F12查看源码,发现字体加密。借助Python,引用包和字体包进行base64二进制解码,解析字体映射关系,成功解密并编写爬虫代码抓取详细内容,最终以JSON格式保存数据。
本文介绍了在爬取租房网站时遇到的数字加密问题,通过F12查看源码,发现字体加密。借助Python,引用包和字体包进行base64二进制解码,解析字体映射关系,成功解密并编写爬虫代码抓取详细内容,最终以JSON格式保存数据。
前两天做到爬取租房网站的一个爬虫题目诈一看还挺简单(之前从来没有爬过租房网站)下一刻我就后悔了里面的数字竟然是乱码瞬间不知所措(奔溃边缘徘徊)就是这个东西这是个嘛
也没学过类似于这种解码的东东然后就疯狂的找博客(写的是不少,能用的却没几个)最终在昨天寻找到了一篇还算比较靠谱的博客(大神)https://blog.csdn.net/qq_38105596/article/details/90177458对没错就是他,然后我就将大佬写的尝试着与我写的结合(结果脑子都停转了去这是个啥)好在皇天不负有心人,对没错就在此刻我终于成了(啊哈哈哈)
然后我就来分享我的喜悦来了(哦哈哈哈)我自己也总结了一下
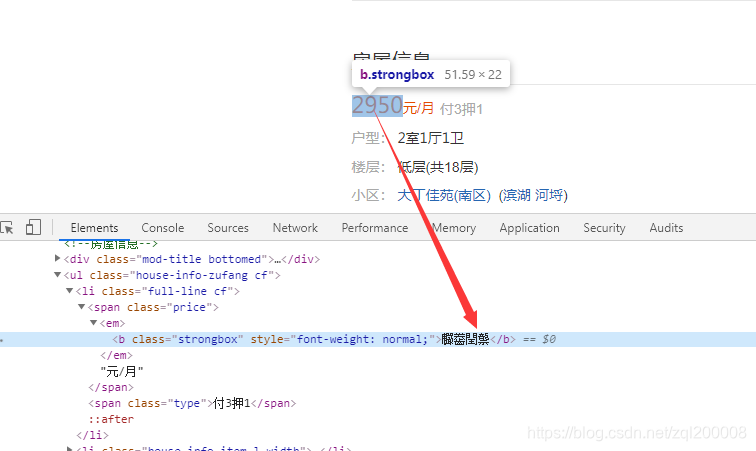
F12查看那个价格在最右边看到了fangchan-secret对没错就是它在捣乱(好气的有木有)

我们复制它然后就右键查看网页源代码然后F3开始进行搜索咯就到了下面那个红框框里面的内容(没错就是它)这就是它的字体
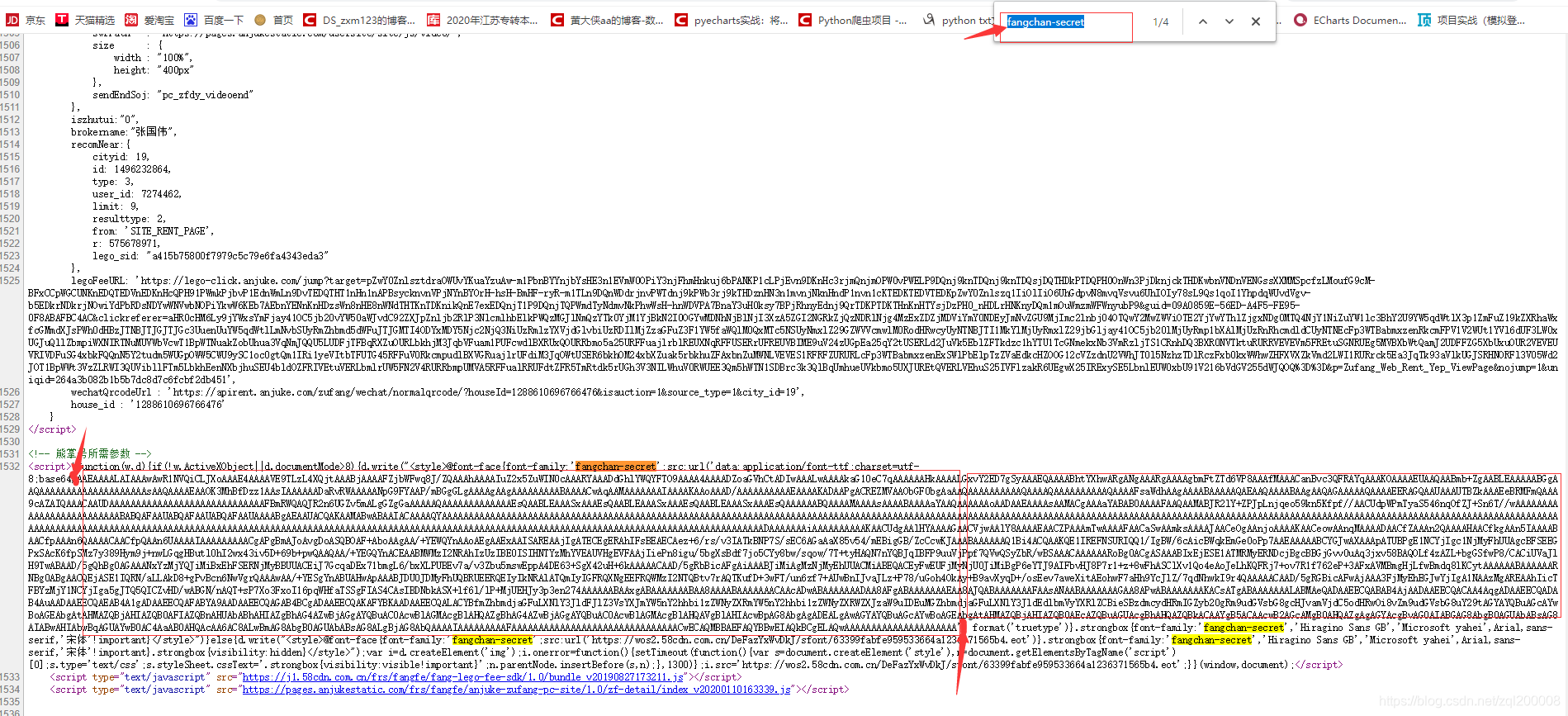
现在我们做的就是要用正则表达式将它里面的内容取出来(因为会随着网页变化里面内容也会变化,之前不知道就直接复制过来然后数字飞到了天上8080年56月78日运行它就知道什么是绝望https://blog.csdn.net/zql200008/article/details/103973085)
base64_str = re.findall(";src:url\('(data.*)'\)\sformat\('truetype'\)")
引用包base64和字体包进行base64二进制解码,将字体文件写入了ttf字体文件和xml文件中
import base64
from fontTools.ttLib import TTFont
from io import BytesIO
然后解析映射关系出来一大堆这样的东西(看了一大堆博客终于知道了glyph00000没有意义,glyph00001对应0,glyph00001对应2以此类推)
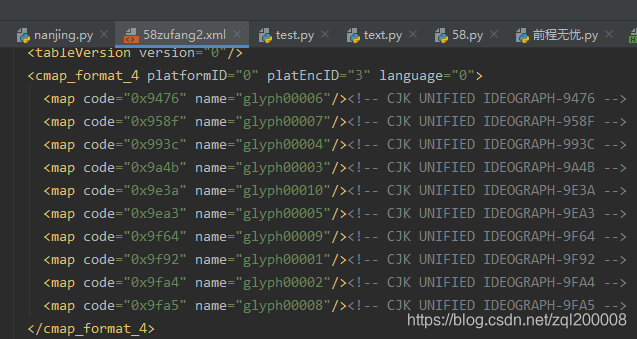
知道这些过后就可以开始写我的爬虫代码了(我需要的是详细页面中的详细内容)确定找到全部的list列表
all_list = selector.xpath('//*[@class="zu-itemmod"]') #当页中全部数据列表
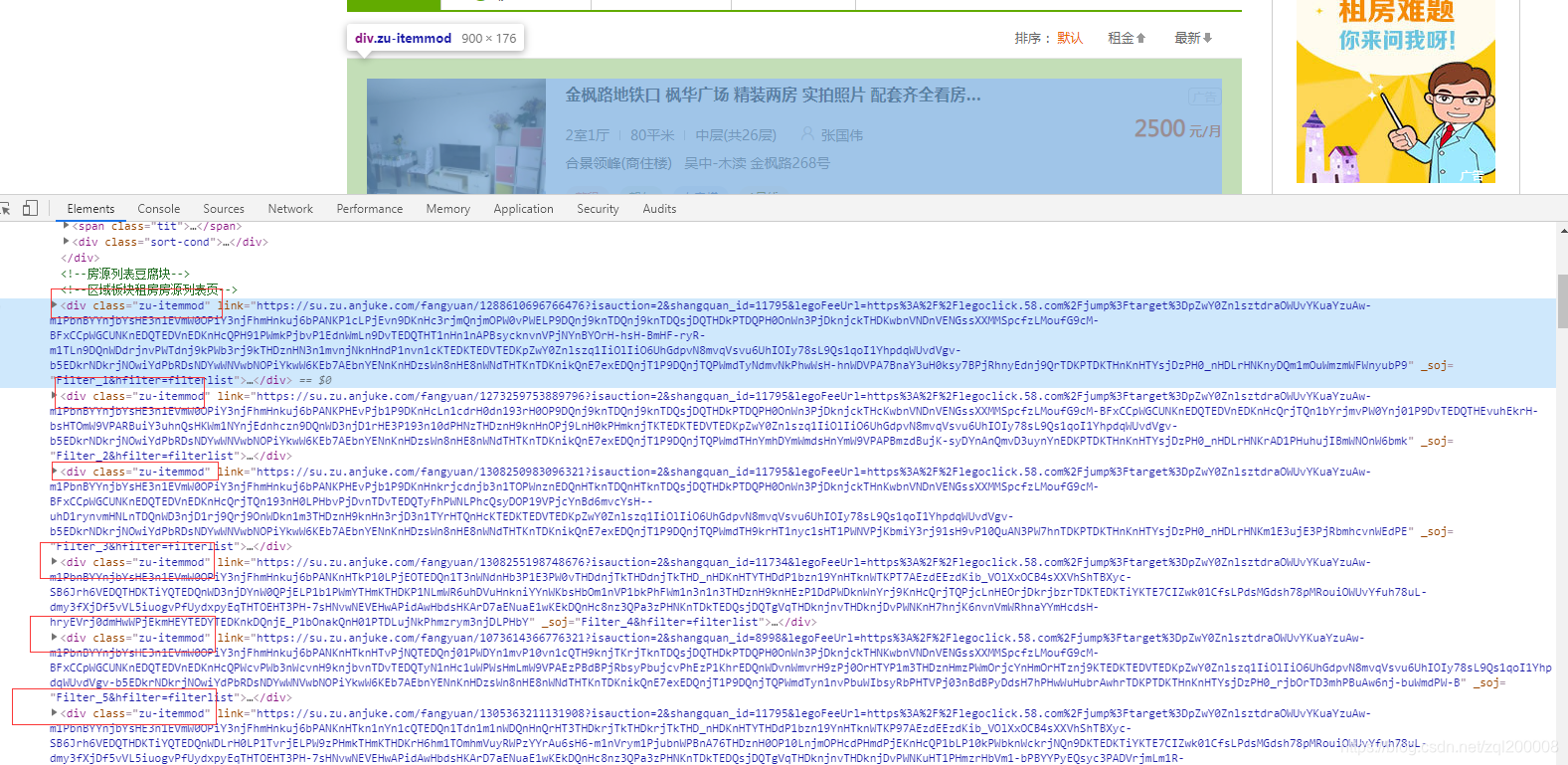
为了找到每一个的详细内容我们需要知道每一个的URL(就是它)
all_list = selector.xpath('//*[@class="zu-itemmod"]') #当页中全部数据列表
for sel in all_list:
url_a = sel.xpath('div[1]/h3/a/@href')[0] #获取到每一页的URL
parse_id_detail(url_a) #这是为下面的def
这样我们就得到了全部的listURL
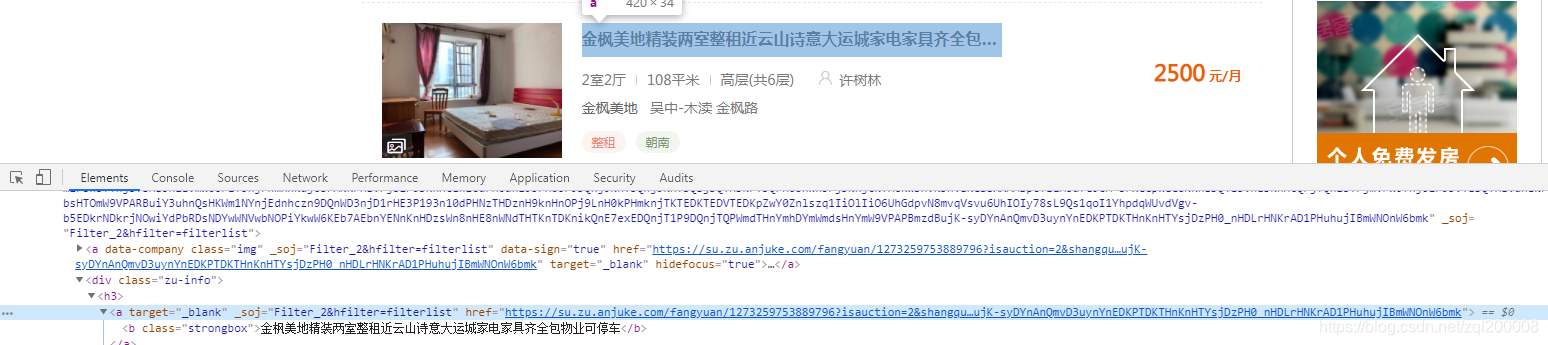
进入到每一页的URL中寻找我们需要的内容(呐就是这些)
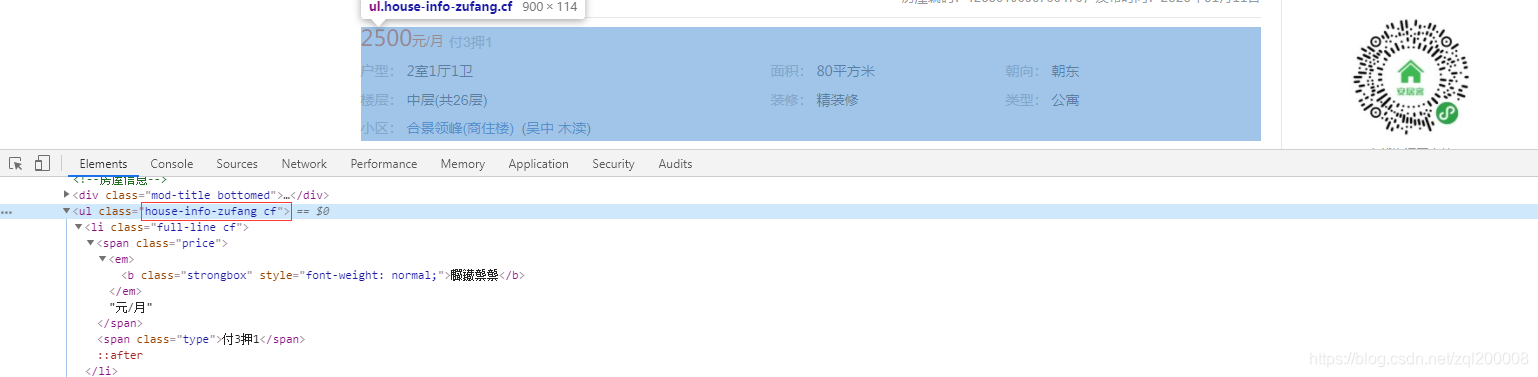
写一个函数确保我们需要的每个URL都可以获取内容
def parse_id_detail(url_a):
alls = requests.get(url_a,headers=headers)
alls.encoding='utf-8'
selector = etree.HTML(alls.text)
time.sleep(random.randint(0,1)) #0~1秒爬取一次
items=[]
item = {
}
#房间价格(像这样的列子可以将其他的都提取)
price = selector.xpath('string(//*[@class="house-info-zufang cf"]/li[1]/span)')
item['price'] = price
items.append(item) # 最后的数据整合
最后就要将获取的数据保存咯(这里我的题目要求是json形式保存,你们也可以用其他类型)
# 将数据已json数据存储
with open('all.json','a',encoding='utf-8')as fp:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









