







首先说明
是在 mysql innodb 下比较
count(*) count(1) count(id) 三种类型的区别
创建表
CREATE TABLE `t_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` tinyint(4) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`testchar` varchar(100) DEFAULT NULL COMMENT '102102301230120300213010230102312301203012301230',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=665396 DEFAULT CHARSET=utf8
CREATE TABLE `t_user_2` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`id_2` bigint(20) NOT NULL DEFAULT '1',
`name` varchar(255) DEFAULT NULL,
`age` tinyint(4) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`testchar` varchar(100) DEFAULT NULL COMMENT '102102301230120300213010230102312301203012301230',
PRIMARY KEY (`id`),
KEY `idx_2` (`id_2`),
) ENGINE=InnoDB AUTO_INCREMENT=690409 DEFAULT CHARSET=utf81表对比 2表 只是多了 一个id_2 字段和索引
写入 60w数据后
看下 count(*) count(1) count(id) 执行情况
在 t_user 表执行



在 t_user_2 表执行


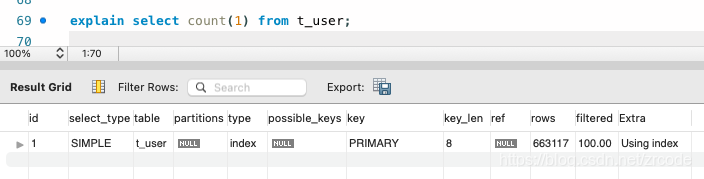
再两个表中的执行计划中 可以看到 count(*) count(1) count(id) 效果是一样的
唯一不同的是 mysql innodb 会优化查询 优先找二级索引去查 数据 表里没有二级索引 那就走主键索引
为什么会有这样优化呢?
主键索引 和 二级索引的区别在于 叶子节点有没有数据
主键索引有数据 所以每个 page 页 存储的数据就少 那么 就需要更多的IO















 372
372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









