









欢迎访问我的blog http://www.codinglemon.cn/
立个flag,8月20日前整理出所有面试常见问题,包括有:
Java基础、JVM、多线程、Spring、Redis、MySQL、Zookeeper、Dubbo、RokectMQ、分布式锁、算法。
14. 算法篇
文章目录
终于到最后一篇了,也算没有打脸,哈哈,算法篇目前可能只会对常问的算法的原理进行总结,后面会更新每个算法的套路模板。
当然,了解了算法的原理,知道这道题考什么也不一定就能写出算法题,0 0,就跟你知道这道数学题考勾股定理,但是你不画辅助线,不拆分图形,你也算不出最终结果。所以算法题最终还是要多写多练,做的多了,心里就不慌了。
14.1 贪心算法
所谓贪心算法是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,它所做出的仅仅是在某种意义上的局部最优解。
贪心算法没有固定的算法框架,算法设计的关键是贪心策略的选择。必须注意的是,贪心算法不是对所有问题都能得到整体最优解,选择的贪心策略必须具备无后效性(即某个状态以后的过程不会影响以前的状态,只与当前状态有关。)
所以,对所采用的贪心策略一定要仔细分析其是否满足无后效性(即对某一条件,当前的情况不满足,则后面的也不会满足)。
总结:从局部最优推全局,将问题尽量最简化,然后向复杂推广。
相关题:
leetcode_455.分发饼干
14.2 分治算法
分治策略是:对于一个规模为n的问题,若该问题可以容易地解决(比如说规模n较小)则直接解决,否则将其分解为k个规模较小的子问题,这些子问题互相独立且与原问题形式相同,递归地解这些子问题,然后将各子问题的解合并得到原问题的解。这种算法设计策略叫做分治法。
分治法所能解决的问题一般具有以下几个特征:
- 该问题的规模缩小到一定的程度就可以容易地解决
- 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质。
- 利用该问题分解出的子问题的解可以合并为该问题的解;
- 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子子问题。
总结:从将整体拆分为n个子问题,递归的解决每个子问题,一般来说每个子问题的解决方式都是相同的。
相关题:
241. 为运算表达式设计优先级
14.3 动态规划
首先,动态规划问题的一般形式就是求最值。动态规划其实是运筹学的一种最优化方法,只不过在计算机问题上应用比较多,比如说让你求最长递增子序列呀,最小编辑距离呀等等。
既然是要求最值,核心问题是什么呢?求解动态规划的核心问题是穷举。因为要求最值,肯定要把所有可行的答案穷举出来,然后在其中找最值呗。
动态规划这么简单,就是穷举就完事了?我看到的动态规划问题都很难啊!
首先,动态规划的穷举有点特别,因为这类问题存在 「重叠子问题」 ,如果暴力穷举的话效率会极其低下,所以需要 「备忘录」 或者 「DP table」 来优化穷举过程,避免不必要的计算。
而且,动态规划问题一定会具备 「最优子结构」 ,才能通过子问题的最值得到原问题的最值。
另外,虽然动态规划的核心思想就是穷举求最值,但是问题可以千变万化,穷举所有可行解其实并不是一件容易的事,只有列出正确的 「状态转移方程」 ,才能正确地穷举。
以上提到的重叠子问题、最优子结构、状态转移方程就是动态规划三要素。但是在实际的算法问题中,写出状态转移方程是最困难的。
总结:动态规划从根本上讲就是穷举,但是为了优化穷举过程,需要进行剪枝,也就是利用DP table记录计算过的值。动态规划的重点和难点也是如何穷举所有可能的结果。
14.4 快排
我们从一个数组来逐步逐步说明快速排序的方法和思路。
- 假设我们对数组{7, 1, 3, 5, 13, 9, 3, 6, 11}进行快速排序。
- 首先在这个序列中找一个数作为基准数,为了方便可以取第一个数。
- 遍历数组,将小于基准数的放置于基准数左边,大于基准数的放置于基准数右边。
- 此时得到类似于这种排序的数组{3, 1, 3, 5, 6, 7, 9, 13, 11}。
- 在初始状态下7是第一个位置,现在需要把7挪到中间的某个位置k,也即k位置是两边数的分界点。
- 那如何做到把小于和大于基准数7的值分别放置于两边呢,我们采用双指针法,从数组的两端分别进行比对。
- 先从最右位置往左开始找直到找到一个小于基准数的值,记录下该值的位置(记作 i)。
- 再从最左位置往右找直到找到一个大于基准数的值,记录下该值的位置(记作 j)。
- 如果位置i<j,则交换i和j两个位置上的值,然后继续从(j-1)的位置往前和(i+1)的位置往后重复上面比对基准数然后交换的步骤。
- 如果执行到i==j,表示本次比对已经结束,将最后i的位置的值与基准数做交换,此时基准数就找到了临界点的位置k,位置k两边的数组都比当前位置k上的基准值或都更小或都更大。
- 上一次的基准值7已经把数组分为了两半,基准值7算是已归位(找到排序后的位置)。
- 通过相同的排序思想,分别对7两边的数组进行快速排序,左边对[left, k-1]子数组排序,右边则是[k+1, right]子数组排序。
- 利用递归算法,对分治后的子数组进行排序。
快速排序基于分治思想,它的时间平均复杂度很容易计算得到为O(NlogN)。
总结:快排的思想是指定基准数后,一次遍历保证基准数左边的数都比基准数小,右边的数都比基准数大。然后递归的对基准数左右序列进行再排序,直到排序结束。
模板代码:
/**
* 快速排序
* @param array
*/
public static void quickSort(int[] array) {
int len;
if(array == null
|| (len = array.length) == 0
|| len == 1) {
return ;
}
sort(array, 0, len - 1);
}
/**
* 快排核心算法,递归实现
* @param array
* @param left
* @param right
*/
public static void sort(int[] array, int left, int right) {
if(left > right) {
return;
}
// base中存放基准数
int base = array[left];
int i = left, j = right;
while(i != j) {
// 顺序很重要,先从右边开始往左找,直到找到比base值小的数
while(array[j] >= base && i < j) {
j--;
}
// 再从左往右边找,直到找到比base值大的数
while(array[i] <= base && i < j) {
i++;
}
// 上面的循环结束表示找到了位置或者(i>=j)了,交换两个数在数组中的位置
if(i < j) {
int tmp = array[i];
array[i] = array[j];
array[j] = tmp;
}
}
// 将基准数放到中间的位置(基准数归位)
array[left] = array[i];
array[i] = base;
// 递归,继续向基准的左右两边执行和上面同样的操作
// i的索引处为上面已确定好的基准值的位置,无需再处理
sort(array, left, i - 1);
sort(array, i + 1, right);
}
相关题:所有基于排序的题一般都可以用快排解决。
14.5 堆排
堆是一个近似完全二叉树的结构,并同时满足堆的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。如下图:
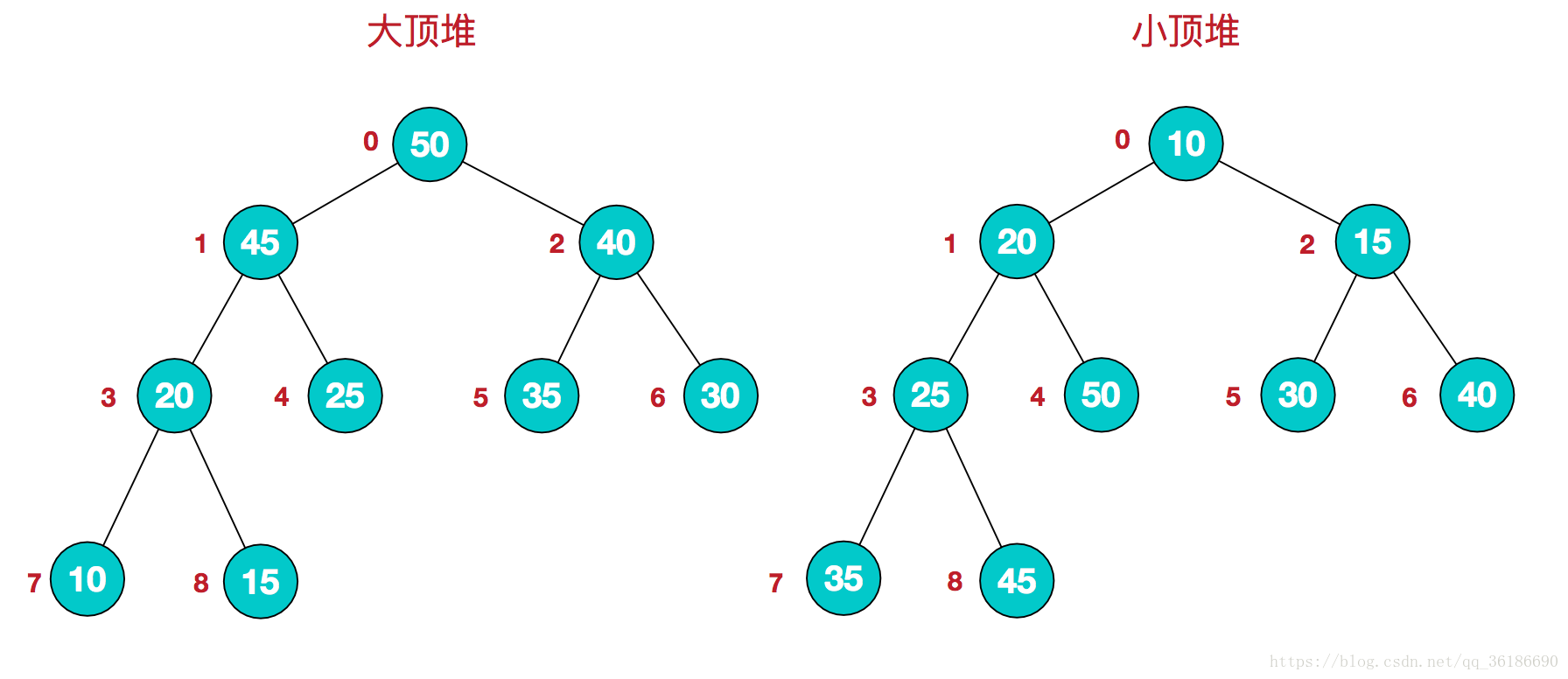
同时,我们对堆中的结点按层进行编号,将这种逻辑结构映射到数组中就是下面这个样子:

堆排序的基本思想是:将待排序序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了
模板代码:
public class ArrayHeap {
private int[] arr;
public ArrayHeap(int[] arr) {
this.arr = arr;
}
private int getParentIndex(int child) {
return (child - 1) / 2;
}
private int getLeftChildIndex(int parent) {
return 2 * parent + 1;
}
private void swap(int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
/**
* 调整堆。
*/
private void adjustHeap(int i, int len) {
int left, right, j;
left = getLeftChildIndex(i);
while (left <= len) {
right = left + 1;
j = left;
if (j < len && arr[left] < arr[right]) {
j++;
}
if (arr[i] < arr[j]) {
swap(array, i, j);
i = j;
left = getLeftChildIndex(i);
} else {
break; // 停止筛选
}
}
}
/**
* 堆排序。
* */
public void sort() {
int last = arr.length - 1;
// 初始化最大堆
for (int i = getParentIndex(last); i >= 0; --i) {
adjustHeap(i, last);
}
// 堆调整
while (last >= 0) {
swap(0, last--);
adjustHeap(0, last);
}
}
}
14.6 二叉树
关于二叉树的内容很多很广很深,后面会慢慢总结,这里先总结两个模板代码。
14.6.1 遍历二叉树
/**
* @author zry
* @date 2021-7-24 16:58
*/
public class Tree {
//中序遍历
public List<Integer> inorderTraversal(TreeNode root){
List list = new ArrayList();
findNode(root,list);
return list;
}
public void findNode(TreeNode node, List<Integer> list){
if(node == null){
return;
}
findNode(node.left,list);
list.add(node.val);
findNode(node.right,list);
}
//Definition for a binary tree node.
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {}
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
}
相关题目:
94.二叉树的中序遍历
104.二叉树的最大深度
14.6.2 比较两个树
class Tree{
public boolean isSameTree(TreeNode p, TreeNode q) {
return findNode(p,q);
}
private boolean findNode(TreeNode p, TreeNode q){
if(p == null && q== null){
return true;
}else if(p==null || q == null){
return false;
}
return p.val == q.val && findNode(p.left,q.left)&&findNode(p.right,q.right);
}
}
14.7 广度优先遍历(BFS)
深度优先遍历和广度优先遍历都是二叉树相关的内容,但是比较重要所以单独拿出来说。
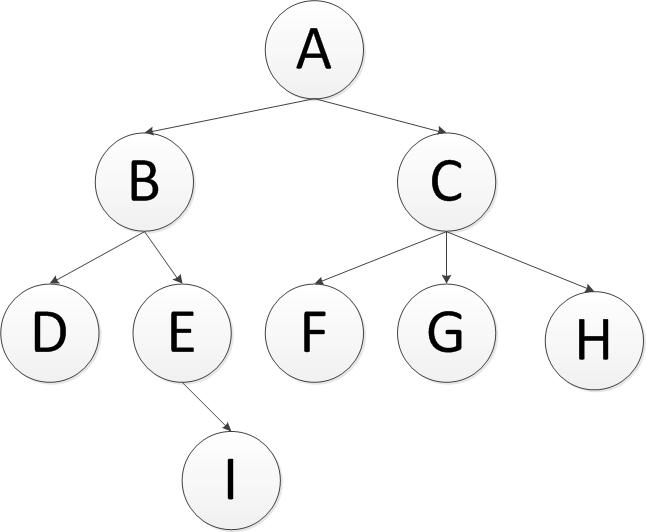
英文缩写为BFS即Breadth FirstSearch。其过程检验来说是对每一层节点依次访问,访问完一层进入下一层,而且每个节点只能访问一次。对于上面的例子来说,广度优先遍历的 结果是:A,B,C,D,E,F,G,H,I(假设每层节点从左到右访问)。
先往队列中插入左节点,再插右节点,这样出队就是先左节点后右节点了。
广度优先遍历树,需要用到队列(Queue)来存储节点对象,队列的特点就是先进先出。例如,上面这颗树的访问如下:
-
首先将A节点插入队列中,队列中有元素(A);
-
将A节点弹出,同时将A节点的左、右节点依次插入队列,B在队首,C在队尾,(B,C),此时得到A节点;
-
继续弹出队首元素,即弹出B,并将B的左、右节点插入队列,C在队首,E在队尾(C,D,E),此时得到B节点;
-
继续弹出,即弹出C,并将C节点的左、中、右节点依次插入队列,(D,E,F,G,H),此时得到C节点;
-
将D弹出,此时D没有子节点,队列中元素为(E,F,G,H),得到D节点;
-
依此类推…
代码模板:
/**
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
*/
public class Solution {
public ArrayList<Integer> PrintFromTopToBottom(TreeNode root) {
ArrayList<Integer> lists=new ArrayList<Integer>();
if(root==null)
return lists;
Queue<TreeNode> queue=new LinkedList<TreeNode>();
queue.offer(root);
while(!queue.isEmpty()){
TreeNode tree=queue.poll();
if(tree.left!=null)
queue.offer(tree.left);
if(tree.right!=null)
queue.offer(tree.right);
lists.add(tree.val);
}
return lists;
}
}
14.8 深度优先遍历(DFS)
英文缩写为DFS即Depth First Search.其过程简要来说是对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次。对于上面的例子来说深度优先遍历的结果就是:A,B,D,E,I,C,F,G,H.(假设先走子节点的的左侧)。
深度优先遍历各个节点,需要使用到栈(Stack)这种数据结构。stack的特点是是先进后出。整个遍历过程如下:
先往栈中压入右节点,再压左节点,这样出栈就是先左节点后右节点了。
-
首先将A节点压入栈中,stack(A);
-
将A节点弹出,同时将A的子节点C,B压入栈中,此时B在栈的顶部,stack(B,C);
-
将B节点弹出,同时将B的子节点E,D压入栈中,此时D在栈的顶部,stack(D,E,C);
-
将D节点弹出,没有子节点压入,此时E在栈的顶部,stack(E,C);
-
将E节点弹出,同时将E的子节点I压入,stack(I,C);
-
依次往下,最终遍历完成。
模板代码:
非递归实现:
/**
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
*/
public class Solution {
public ArrayList<Integer> PrintFromTopToBottom(TreeNode root) {
ArrayList<Integer> lists=new ArrayList<Integer>();
if(root==null)
return lists;
Stack<TreeNode> stack=new Stack<TreeNode>();
stack.push(root);
while(!stack.isEmpty()){
//先往栈中压入右节点,再压左节点,这样出栈就是先左节点后右节点了。
TreeNode tree=stack.pop();
if(tree.right!=null)
stack.push(tree.right);
if(tree.left!=null)
stack.push(tree.left);
lists.add(tree.val);
}
return lists;
}
}
递归实现:
public void depthOrderTraversalWithRecursive()
{
depthTraversal(root);
}
private void depthTraversal(TreeNode tn)
{
if (tn!=null)
{
System.out.print(tn.value+" ");
depthTraversal(tn.left);
depthTraversal(tn.right);
}
}
14.9 说在最后
当然,算法部分肯定远不止这些,目前总结的是比较主流的算法题的考察内容,后面会不断补充,也许会单独开一个专栏来介绍本部分内容。
以上,完结,撒花!0.0















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









