







为了更好地使用Scrapy这个爬虫框架,首先要对这个框架做一个简单的了解,下图显示了Scrapy的基本组件以及组件间的联系:
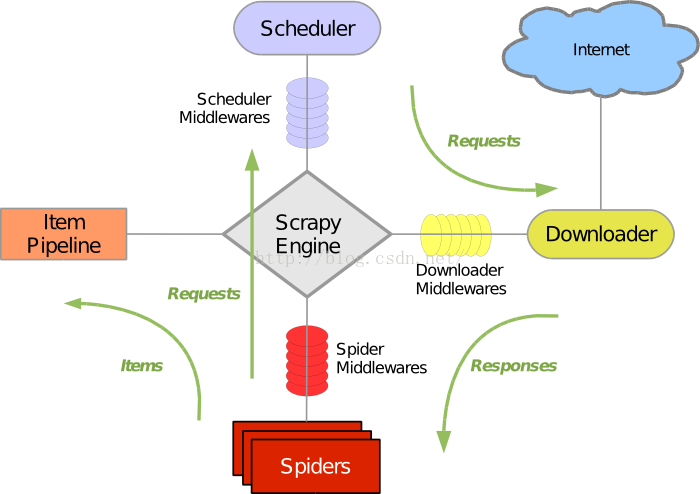
下面解释下Scrapy各组件的作用:
1、Scrapy Engine(Scrapy引擎)
Scrapy引擎是用来控制整个系统的数据处理流程,并进行事务处理的触发。也就是说,Scrapy引擎将各个组件联系在一起,是Scrapy的核心部分。
2、Scheduler(调度器)
调度程序从Scrapy引擎接受请求并排序列入队列,并在Scrapy引擎发出请求后返还给他们。调
 本文介绍了Scrapy爬虫框架的基本组件,包括Scrapy引擎、调度器、下载器、蜘蛛、项目管道、下载器中间件、蜘蛛中间件和调度中间件。Scrapy引擎控制数据处理流程,调度器管理请求队列,下载器负责网页抓取,蜘蛛解析网页内容,项目管道处理和存储数据,中间件则提供了自定义功能扩展。Scrapy的工作流程包括种子URL到数据的转换,通过各个组件协同完成网页爬取和数据提取。
本文介绍了Scrapy爬虫框架的基本组件,包括Scrapy引擎、调度器、下载器、蜘蛛、项目管道、下载器中间件、蜘蛛中间件和调度中间件。Scrapy引擎控制数据处理流程,调度器管理请求队列,下载器负责网页抓取,蜘蛛解析网页内容,项目管道处理和存储数据,中间件则提供了自定义功能扩展。Scrapy的工作流程包括种子URL到数据的转换,通过各个组件协同完成网页爬取和数据提取。
为了更好地使用Scrapy这个爬虫框架,首先要对这个框架做一个简单的了解,下图显示了Scrapy的基本组件以及组件间的联系:
下面解释下Scrapy各组件的作用:
1、Scrapy Engine(Scrapy引擎)
Scrapy引擎是用来控制整个系统的数据处理流程,并进行事务处理的触发。也就是说,Scrapy引擎将各个组件联系在一起,是Scrapy的核心部分。
2、Scheduler(调度器)
调度程序从Scrapy引擎接受请求并排序列入队列,并在Scrapy引擎发出请求后返还给他们。调

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















