






hive
1.分区分桶
在Hive中,分区(Partition)和分桶(Bucketing)都是用于数据管理和查询性能优化的技术。它们有不同的用途和特点。
分区(Partition):
- 定义:分区是将数据按照某一列或多列的值划分为不同的子目录,使数据可以按照分区列的值进行组织。例如,可以根据日期将数据分为不同的分区,每个分区对应一个日期值。
- 优点:
- 提高查询性能:分区可以减少需要扫描的数据量,当查询涉及到分区列的筛选条件时,只需扫描相关分区,而不是整个表。
- 管理数据:分区可以使数据更加有组织,便于管理和维护。
- 缺点:
- 需要额外的存储空间:每个分区都需要一个目录,这可能会占用较多的存储空间。
- 分区列的选择:选择合适的分区列很重要,如果选择不当,可能会导致性能问题。
- 使用场景:分区通常用于对大型表进行查询优化,特别是当查询经常根据某些列的特定值进行过滤时,分区是一个不错的选择。
分桶(Bucketing):
- 定义:分桶是将表数据分成固定数量的桶(bucket)或分区,每个桶中包含相等数量的数据,桶是按照表中的某列的值进行分配的。与分区不同,桶的数量是固定的,不是根据数据的实际值而变化的。
- 优点:
- 更均匀的数据分布:分桶可以确保数据分布均匀,避免某些分区过大或过小的问题。
- 改善连接操作:当你需要连接多个表时,如果它们都使用相同的分桶列,连接操作会更加高效。
- 缺点:
- 需要额外的计算和管理:分桶需要在数据加载时进行计算和管理,可能需要更多的维护工作。
- 桶的数量选择:选择合适的桶数量很重要,如果数量太少或太多都可能导致性能问题。
- 使用场景:分桶通常用于较大的表,特别是当你需要进行连接操作或者想要确保数据均匀分布时。
区别:
- 分区是按照列的值来组织数据,而分桶是将数据划分为相等数量的桶。
- 分区的数量和值是根据数据的实际内容而确定的,而分桶的数量是预先定义的。
- 分区通常用于过滤数据以提高查询性能,而分桶更适用于确保数据分布的均匀性和连接操作的优化。
- 分区列通常是数据的关键属性,而分桶列通常是用于确保数据均匀分布的属性。
在实际使用中,通常可以将分区和分桶结合起来以获得更好的性能优化效果,具体的选择取决于数据和查询的特点。
2. 数据倾斜
在Hive中,数据倾斜(Data Skew)是指在数据处理过程中,某些特定数据分区或桶包含的数据量远远超过其他分区或桶,导致不均匀的数据分布。数据倾斜可能会导致查询性能下降,因为某些任务可能需要更长的时间来完成,而其他任务则很快结束。
数据倾斜产生的原因:
- 不均匀的数据分布:有些数据分区或桶包含的数据比其他分区或桶多,这可能是由于数据的不均匀分布或者数据加载时的不均匀分布引起的。
- 查询操作:某些查询操作,特别是聚合操作(如GROUP BY)或连接操作(如JOIN),可能会导致数据倾斜,因为数据分布不均匀的分区或桶需要处理更多的数据。
- 数据倾斜的列:在某些情况下,查询中使用的列可能会导致数据倾斜,因为该列的值分布不均匀,导致某些分区或桶包含更多的数据。
解决数据倾斜的方法:
- 重新分桶或重新分区:如果数据倾斜是由于初始的分桶或分区策略引起的,可以考虑重新分桶或重新分区,以确保数据更均匀地分布。
- 使用随机分桶或分区:在某些情况下,可以使用随机分桶或分区策略,将数据均匀分布到不同的桶或分区中,而不依赖于特定的列值。
- 增加桶或分区数量:增加桶或分区的数量可以使数据更细粒度地分布,减少倾斜问题。
- 使用聚合函数时考虑偏移值:在使用聚合函数时,可以考虑添加一个偏移值来减轻数据倾斜。例如,在GROUP BY操作中,可以添加一个随机值作为偏移来分散数据。
- 使用分布式缓存:对于某些数据倾斜的查询,可以考虑使用分布式缓存来存储中间结果,以减轻数据倾斜带来的性能问题。
- 使用Hive的自动优化特性:Hive提供了一些自动优化特性,如动态分区裁剪和MapJoin优化,可以帮助处理某些数据倾斜情况。
解决数据倾斜通常需要根据具体情况采取不同的策略,可能需要综合考虑数据量、查询操作、数据分布等多个因素来选择合适的解决方法。监控和性能调优是处理数据倾斜的重要一部分,以确保查询在实际场景中能够高效运行。
3. 存储格式orc和parquet
ORC(Optimized Row Columnar)和Parquet是两种在Hive中广泛使用的列式存储格式,它们旨在提供更高的性能和更有效的数据压缩。下面详细讨论一下ORC和Parquet的特点、优点以及如何在Hive中使用它们。
ORC存储格式:
-
特点:
- 列式存储:ORC将数据按列而不是按行进行存储,这意味着只需要读取和解码查询所需的列,从而减少了I/O操作。
- 高度压缩:ORC使用多种压缩技术,如Run Length Encoding(RLE)、Bloom Filters等,以减小数据存储的开销。
- 支持复杂数据类型:ORC支持复杂数据类型,如结构体、数组和映射,使其适用于各种数据类型的存储。
- 谓词下推:ORC能够将查询中的谓词条件下推到存储层,减少了读取不必要数据的开销。
- 极佳的读取性能:ORC通常具有快速的读取性能,特别是在分析查询中,它可以显著提高性能。
-
优点:
- 提供了极高的读取性能,尤其在复杂查询中。
- 高度压缩可以节省存储成本。
- 支持谓词下推,减少了数据的扫描量。
- 适用于大规模数据仓库和分析工作负载。
-
缺点:
- 写入速度较慢:ORC的写入速度通常相对较慢,因为需要进行压缩和列式存储的转换。
-
在Hive中的使用:
- 创建ORC表:在Hive中,可以使用
STORED AS ORC选项来创建ORC格式的表。 - 转换表格格式:可以使用Hive的INSERT OVERWRITE语句将现有表格数据转换为ORC格式。
- 创建ORC表:在Hive中,可以使用
Parquet存储格式:
-
特点:
- 列式存储:Parquet与ORC一样,也采用列式存储,提高了读取性能。
- 高度压缩:Parquet支持多种压缩算法,包括Snappy、Gzip等,以减小存储开销。
- 架构演化:Parquet的文件格式是由Apache Arrow项目支持的,这意味着它具有良好的跨平台支持和持久性。
- 支持多种编程语言:Parquet可以通过多种编程语言进行读写,使其在不同的数据处理框架中具有广泛的应用。
-
优点:
- 提供了快速的读取性能,特别是在多种数据处理工具中。
- 高度压缩可以减少存储成本。
- 支持多种编程语言,易于集成到不同的数据处理生态系统中。
-
缺点:
- 写入速度较慢:与ORC一样,Parquet的写入速度通常较慢。
-
在Hive中的使用:
- 创建Parquet表:在Hive中,可以使用
STORED AS PARQUET选项来创建Parquet格式的表。 - 转换表格格式:可以使用Hive的INSERT OVERWRITE语句将现有表格数据转换为Parquet格式。
- 创建Parquet表:在Hive中,可以使用
ORC和Parquet是在Hive中用于数据存储和查询性能优化的两种主要列式存储格式。它们都具有高度压缩和快速的读取性能,适用于大规模数据仓库和分析工作负载。选择其中一种取决于您的具体需求以及与其他数据处理工具的集成。
ORC(Optimized Row Columnar)和Parquet是两种常见的列式存储格式,用于在大数据处理框架中存储和查询数据。以下是它们之间的主要区别:
-
压缩算法:
- ORC:ORC默认使用Zlib压缩,但它还支持Snappy和LWZ等其他压缩算法。ORC使用多层压缩,使其在存储时可以获得很高的压缩比。
- Parquet:Parquet支持多种压缩算法,包括Snappy、Gzip、LZO、Brotli等。用户可以根据需要选择合适的压缩算法。
-
架构演化:
- ORC:ORC文件格式是为了在Hive中优化查询性能而设计的,并且与Hive生态系统深度集成。
- Parquet:Parquet文件格式的设计源自Apache Arrow项目,它具有广泛的跨平台支持,可以在多种数据处理工具中使用,不仅限于Hive。
-
数据类型支持:
- ORC:ORC支持复杂数据类型,如结构体、数组和映射。这使得它非常适合存储和查询包含嵌套数据结构的数据。
- Parquet:Parquet也支持复杂数据类型,使其在处理半结构化或嵌套数据时非常有用。
-
读取性能:
- ORC:ORC在某些情况下具有更快的读取性能,特别是在Hive中进行复杂的分析查询时。它通过谓词下推和列式存储优化查询性能。
- Parquet:Parquet在许多数据处理框架中都有很好的读取性能,适用于各种工具和查询引擎。
-
跨平台支持:
- ORC:ORC在一定程度上与Hive集成紧密,因此在Hive生态系统中使用较为流畅。
- Parquet:Parquet的跨平台支持更广泛,可以在不同的数据处理工具中轻松读写。
-
社区和生态系统:
- ORC:ORC的生态系统主要围绕Hive和Apache ORC项目构建,因此对于Hive用户而言是一个强大的选择。
- Parquet:Parquet具有更广泛的社区支持,并且在多个大数据处理框架中都有广泛应用,包括Apache Spark、Apache Impala、Apache Drill等。
4. 数据建模模型
在Hive中,数据建模模型通常涉及到维度建模和分层建模两种主要的方法,它们用于设计和组织数据仓库以支持分析和报告需求。以下是维度建模和分层建模的详细介绍,以及它们之间的区别:
维度建模:
-
特点:
- 维度建模是一种以事实表(Fact Table)和维度表(Dimension Table)为核心的建模方法。事实表包含度量数据,而维度表包含描述度量的维度属性。
- 维度表通常包含维度的层次结构,例如,时间维度可以包括年、季度、月等层次。
- 维度建模的关键思想是简化数据模型,使其易于理解和查询。
-
优点:
- 易于理解和维护:维度建模的结构清晰,易于理解和维护,有助于降低复杂性。
- 查询性能高:维度建模通常提供较高的查询性能,因为查询通常不需要多次连接。
-
缺点:
- 不适合复杂业务需求:对于包含复杂的业务关系和多层次维度的情况,维度建模可能变得复杂,并可能需要引入冗余数据。
-
使用场景:
- 适用于大多数OLAP(联机分析处理)查询,例如数据仓库中的报表和分析。
- 适用于需要快速查询性能和简单数据模型的场景。
分层建模:
-
特点:
- 分层建模是一种更复杂的建模方法,通常包含多个层次的数据层,从原始数据层到汇总层,以支持不同层次的分析需求。
- 分层建模强调了数据的历史性,通常包括时间序列数据的跟踪和汇总。
- 分层建模允许数据的多次重复使用,支持不同粒度的查询和汇总。
-
优点:
- 支持复杂业务需求:分层建模更适合处理复杂的业务需求,包括多层次的分析和历史数据跟踪。
- 数据重用:分层建模允许数据的多次重复使用,降低了数据存储和计算的成本。
-
缺点:
- 复杂性增加:分层建模通常比维度建模更复杂,需要更多的工作来设计、维护和查询数据模型。
- 查询性能较低:由于包含多个层次和大量历史数据,查询性能可能较低,特别是在汇总层次较高的情况下。
-
使用场景:
- 适用于需要支持多层次分析和历史数据跟踪的场景,例如金融领域的风险管理和业务智能。
区别:
- 结构:维度建模通常包括事实表和维度表,具有平坦结构。分层建模包括多个层次的数据层,涵盖多个粒度和历史数据。
- 复杂性:维度建模相对简单,易于理解和维护。分层建模通常更复杂,需要更多的设计和维护工作。
- 查询性能:维度建模通常具有更高的查询性能,而分层建模的查询性能可能较低。
- 应用场景:维度建模适用于简单的分析和报表,而分层建模适用于复杂的业务需求、多层次分析和历史数据跟踪。
在选择数据建模模型时,需要根据具体的业务需求、数据复杂性和查询性能要求来决定使用哪种模型。通常情况下,维度建模适用于大多数场景,而分层建模适用于需要处理复杂业务关系和历史数据的特定场景。
5. 数仓分层
在Hive中,数据仓库分层(Data Warehousing Layering)是一种组织和管理数据仓库中数据的方法,旨在提供不同层次的数据访问和处理,以满足不同用户或应用程序的需求。通常,数据仓库可以分为三个主要层次:原始数据层(Raw Data Layer)、汇总数据层(Aggregated Data Layer)和报表/分析层(Reporting/Analytics Layer)。
以下是这些层次的详细描述:
-
原始数据层(Raw Data Layer):
- 原始数据层是数据仓库的底层,通常包含了原始、未加工的数据。这些数据通常以原始格式存储,可能包括来自各种数据源的数据,例如日志、数据库抽取、外部数据等。
- 在原始数据层中,数据通常以最粗粒度的形式存在,不经过任何加工或转换。这有助于保留数据的完整性,以便后续的数据处理和分析。
- 数据在原始数据层中可能以分区和分桶的形式进行组织,以提高查询性能。
-
汇总数据层(Aggregated Data Layer):
- 汇总数据层是数据仓库的中间层,用于存储根据业务需求进行聚合和加工的数据。这些数据通常用于支持常见的查询和报表。
- 在汇总数据层中,数据通常按照不同的粒度进行汇总,以便用户能够更快速地获取结果。例如,可以按天、月或年对数据进行汇总。
- 汇总数据层的数据通常以某种列式存储格式(如ORC或Parquet)存储,以提高查询性能。
-
报表/分析层(Reporting/Analytics Layer):
- 报表/分析层是数据仓库的最上层,用于向用户提供高级查询、分析和报表功能。这是最终用户或业务分析师使用的数据层。
- 在这一层次中,数据通常以维度建模或分层建模的方式组织,以支持复杂的查询和报表需求。
- 用户可以使用各种报表工具、分析工具或编程语言(如SQL、Python、R等)来访问和分析数据。
数仓分层的优点:
-
性能优化:通过在不同层次中存储数据,可以优化查询性能。原始数据层存储粗粒度的数据,而汇总数据层和报表/分析层存储更高级的数据,以便更快速地响应查询。
-
数据质量和一致性:在不同层次中对数据进行加工和清洗可以提高数据的质量和一致性,确保用户访问的数据是可信的。
-
多层次访问控制:不同用户或应用程序可以访问不同层次的数据,以满足安全性和隐私要求。
-
支持多种用例:数仓分层可以满足不同用户和用例的需求,从原始数据的探索到高级分析和报表。
数仓分层的区别:
-
原始数据层包含未经加工的原始数据,通常以最粗粒度的形式存储。这一层的数据保持了数据的完整性,但查询性能相对较差。
-
汇总数据层包含经过部分加工和聚合的数据,以支持常见的查询需求。数据以较高的粒度存储,提供了更好的查询性能。
-
报表/分析层包含最终用户和业务分析师使用的数据,通常以维度建模或分层建模的方式组织,以支持高级查询、分析和报表需求。
选择合适的数据仓库分层策略取决于业务需求、性能要求和数据复杂性。通常,数仓分层策略是为了平衡数据的完整性和性能之间的权衡,并确保数据仓库能够有效地支持各种用例。
6. 优化和sql优化
Hive优化和SQL优化是在大数据处理中非常重要的方面,它们旨在提高查询性能和数据处理效率。以下是有关Hive优化和SQL优化的重要概念和技巧:
Hive优化:
-
查询计划优化:
- Hive使用查询计划(Query Plan)来执行SQL查询。通过检查查询计划,可以识别潜在的性能瓶颈,并采取相应的措施来优化查询计划。
- 使用
EXPLAIN命令查看查询计划,以便理解查询执行的方式。
-
数据分区和桶:
- 在Hive中,数据分区和桶是优化性能的重要机制。合理地选择数据分区和桶可以减少数据扫描的开销。
- 分区可以根据查询过滤条件来选择特定分区,减少不必要的数据扫描。
- 桶可以在分区内进一步细分数据,减少数据的读取量。
-
数据压缩和列式存储:
- Hive支持多种压缩算法和列式存储格式(如ORC和Parquet)。选择适当的压缩和存储格式可以减小数据的存储空间,并提高查询性能。
- 压缩和列式存储可以减少I/O操作和内存占用。
-
数据倾斜处理:
- 数据倾斜是一个常见的性能问题,在Hive中,它可以导致一些任务运行时间过长。
- 解决数据倾斜可以采用随机分桶、增加桶的数量、使用缓存等方法来均衡数据分布。
-
动态分区裁剪:
- Hive支持动态分区裁剪,这意味着只有与查询谓词匹配的分区数据会被扫描,从而减少不必要的数据读取。
-
MapJoin和BucketMapJoin:
- MapJoin和BucketMapJoin是针对小表和大表连接的优化技术,它们可以减少数据重分布和网络传输开销。
SQL优化:
-
合理使用索引:
- 对于关系型数据库,索引是提高查询性能的关键。确保表的关键列上有索引,同时避免过多的索引,因为它们可能增加写入操作的开销。
-
查询优化:
- 编写高效的SQL查询是SQL优化的核心。合理使用JOIN、GROUP BY、WHERE等关键字,避免使用不必要的子查询,以及优化复杂的查询逻辑。
-
避免使用SELECT *::
- 尽量避免使用SELECT *,而是只选择需要的列,以减少数据传输和I/O开销。
-
表分区和索引:
- 对于关系型数据库,表分区和索引是优化性能的重要手段。合理地选择分区键和创建适当的索引可以提高查询效率。
-
使用合适的数据类型:
- 使用适当的数据类型来存储数据,避免使用过大或过小的数据类型,以减少存储和内存开销。
-
统计信息:
- 统计信息(Statistics)可以帮助数据库优化器选择合适的查询计划。确保统计信息是最新的,并定期更新它们。
-
连接类型:
- 对于连接操作,选择适当的连接类型(如INNER JOIN、LEFT JOIN等)可以减少不必要的数据集合和结果集的大小。
-
并行化查询:
- 对于大型查询,可以考虑并行化查询,将查询分解成多个子查询并同时执行,以减少查询时间。
总的来说,Hive优化和SQL优化都是优化大数据处理和关系型数据库查询性能的重要手段。在实践中,需要综合考虑数据量、查询复杂度、硬件资源等因素,采取合适的优化策略来提高系统性能。
7. 常见开窗函数
-
ROW_NUMBER():
- 作用:为结果集中的每一行分配一个唯一的整数值,通常用于对行进行编号。
- 使用方式:
ROW_NUMBER() OVER (PARTITION BY partition_column ORDER BY order_column),其中partition_column是可选的,用于定义分区,order_column是排序列。 - 使用场景:常用于排名、分组和数据分区。例如,获取每个分区中的前N行。
-
RANK() 和 DENSE_RANK():
- 作用:分别计算行在排序顺序中的排名(RANK)和稠密排名(DENSE_RANK)。
- 使用方式:
RANK() OVER (ORDER BY column)和DENSE_RANK() OVER (ORDER BY column)。 - 使用场景:用于排名和竞争分析。RANK分配相同的排名给相等的值,而DENSE_RANK跳过排名。
-
SUM()、AVG()、COUNT() 等聚合函数:
- 作用:允许您在窗口内执行聚合操作,例如求和、平均值和计数。
- 使用方式:
SUM(column) OVER (PARTITION BY partition_column ORDER BY order_column)。 - 使用场景:用于计算滑动平均、累积总数、百分比等。
-
LEAD() 和 LAG():
- 作用:用于访问窗口内某一行之前(LAG)或之后(LEAD)的行的值。
- 使用方式:
LAG(column, n) OVER (ORDER BY order_column)和LEAD(column, n) OVER (ORDER BY order_column),其中n表示偏移量。 - 使用场景:用于计算趋势、增长率、时间差等。
-
FIRST_VALUE() 和 LAST_VALUE():
- 作用:分别获取窗口内某列的第一个值和最后一个值。
- 使用方式:
FIRST_VALUE(column) OVER (ORDER BY order_column)和LAST_VALUE(column) OVER (ORDER BY order_column)。 - 使用场景:用于查找首尾值或执行首尾计算。
-
NTILE():
- 作用:将结果集分成n个近似相等的部分,并为每个部分分配一个整数值。
- 使用方式:
NTILE(n) OVER (ORDER BY order_column),其中n是分区数。 - 使用场景:用于数据分布分析、百分位数计算等。
-
PERCENT_RANK():
- 作用:计算每一行在排序中的相对排名百分比。
- 使用方式:
PERCENT_RANK() OVER (ORDER BY order_column)。 - 使用场景:用于百分位数计算和百分比排名。
8. 小文件过多问题解决
问题原因:
-
分区和桶的不合理使用:当在Hive中创建分区表时,如果分区过于细粒度,或者使用了大量的桶(buckets),就可能导致每个分区或桶生成大量小文件。这是因为Hive会为每个分区和桶创建一个文件或目录。
-
小文件合并:在Hive中执行INSERT操作时,数据通常会被追加到已有文件中,而不是合并成更大的文件。这可能导致小文件的积累。
-
动态分区:当使用动态分区插入数据时,如果数据分布不均匀,可能会导致某些分区包含大量小文件,而其他分区可能包含较少文件。
解决方法:
-
合理设置分区和桶:在设计表时,考虑使用适当的分区和桶策略,避免创建过多的分区或桶。分区应该根据查询和过滤的需求来定义,而不是过于细化。
-
使用INSERT OVERWRITE:为了避免小文件的积累,可以考虑使用INSERT OVERWRITE操作,它将数据覆盖到目标表中,以减少小文件的数量。
-
数据压缩和列式存储:使用压缩和列式存储格式(如ORC或Parquet)可以减小文件大小,从而减少小文件的数量。
-
定期执行合并操作:定期执行合并(Consolidation)操作,将小文件合并成更大的文件。这可以通过Hive的合并操作或使用Hadoop的工具(如Hadoop的合并命令)来完成。
-
调整Hive配置参数:可以通过调整Hive的一些配置参数来控制小文件合并策略。例如,可以调整
hive.merge.mapredfiles和hive.merge.mapfiles等参数来配置小文件的合并行为。 -
使用分区限制:可以设置分区的最大文件数限制,当一个分区中的文件数量达到限制时,停止插入新数据,从而防止小文件过多。
-
定期清理过时数据:定期清理不再需要的数据,以减少小文件的数量。
解决小文件过多问题对于Hive性能和存储管理非常重要,因为小文件会增加文件系统的管理开销、增加元数据的负担,并且可能导致查询性能下降。因此,在设计和维护Hive表时,需要综合考虑数据分区、文件合并和存储格式等因素,以避免小文件问题。
9. sortby orderby区别
SORT BY:
-
功能:
SORT BY用于对查询结果在分区内排序。它将结果集划分成不同的分区,并对每个分区内的数据进行排序。SORT BY通常用于分布式数据处理,以提高查询性能,并允许在后续的查询中更快地访问数据。
-
优点:
- 提高查询性能:通过在分区内排序,
SORT BY可以加速后续查询,特别是在涉及分组和聚合操作时。 - 分区内排序:它适用于需要按特定列排序的查询,但不需要全局排序的情况。
- 提高查询性能:通过在分区内排序,
-
缺点:
- 不保证全局排序:
SORT BY不保证结果的全局排序,因此不适用于需要整个结果集有序的查询。
- 不保证全局排序:
-
使用场景:
- 适用于需要分区内排序,但不需要全局排序的查询。
- 常用于性能敏感的查询,以提高查询速度。
ORDER BY:
-
功能:
ORDER BY用于对查询结果的整个结果集进行排序,保证返回的结果是全局有序的。ORDER BY通常用于关系型数据库或需要整个结果集有序的分布式系统。
-
优点:
- 全局排序:
ORDER BY保证了结果集的全局排序,无论数据在物理存储上如何分布。
- 全局排序:
-
缺点:
- 性能开销:全局排序可能需要较大的性能开销,特别是对于大数据集。
- 不适用于分布式数据处理:在分布式环境下,
ORDER BY可能不如SORT BY高效。
-
使用场景:
- 适用于需要返回全局有序结果的查询,例如需要按某列对结果排序的报表查询。
- 常用于关系型数据库中,或者在特定场景下需要全局排序的Hive查询。
区别:
- 主要区别在于全局排序。
SORT BY用于分区内排序,不保证全局排序,而ORDER BY用于全局排序,保证结果的全局有序性。 SORT BY适用于分布式数据处理环境,可以提高查询性能,但不保证全局排序。ORDER BY适用于关系型数据库或需要全局有序结果的场景。SORT BY通常比ORDER BY更高效,但牺牲了全局排序的保证。
在选择使用 SORT BY 还是 ORDER BY 时,需要根据查询需求和性能要求进行权衡。如果只需要分区内排序或性能敏感查询,可以选择 SORT BY。如果需要全局排序或结果集有序性对查询非常重要,应使用 ORDER BY。
Spark
1.提交流程
-
编写Spark应用程序: 首先,开发人员需要编写Spark应用程序,通常使用Scala、Java、Python或R编程语言。这个应用程序通常包括了数据处理逻辑,例如数据加载、转换、计算和存储等。
-
打包应用程序: 开发人员需要将应用程序打包成一个可执行的JAR文件或Python脚本,以便能够在Spark集群上运行。这个打包过程通常包括将应用程序的所有依赖项打包到一个单独的文件中。
-
创建SparkSession: 在应用程序中,需要创建一个
SparkSession对象。SparkSession是与Spark集群通信的入口点,它负责协调应用程序的执行和管理与集群的连接。 -
配置Spark集群参数: 在
SparkSession中,可以配置一些Spark集群的参数,例如内存分配、执行模式(本地模式、集群模式)、并行度等。这些配置将影响应用程序在集群上的执行方式。 -
提交应用程序: 一旦应用程序准备好并配置完成,可以使用不同的方式提交它,包括以下几种方法:
-
交互式Shell:可以通过启动Spark的交互式Shell(如
spark-shell或pyspark)来提交Spark应用程序,并在Shell中执行代码片段。 -
spark-submit脚本:这是最常用的方式。开发人员可以使用
spark-submit命令行工具来提交应用程序。这个工具接受应用程序的JAR文件、Python脚本或其他支持的应用程序类型作为参数,并将其提交到Spark集群。 -
集成开发环境(IDE):某些IDE(如IntelliJ IDEA、Eclipse等)提供了集成的Spark支持,可以直接从IDE中提交Spark应用程序。
-
-
集群分配资源: 一旦应用程序被提交,Spark集群会分配资源给该应用程序。这包括分配执行器(Executor)节点、内存和CPU核心等资源。
-
应用程序执行: Spark应用程序开始在集群上执行。每个执行器节点会启动一个或多个任务,这些任务并行处理数据。Spark通过调度任务以及数据分区和Shuffle操作来实现高效的数据处理。
-
监控和调试: 在应用程序执行期间,可以使用Spark的监控工具和日志来监视应用程序的进展和性能。如果应用程序出现问题,可以使用日志和调试工具进行故障排除。
-
应用程序完成: 一旦应用程序完成所有任务,它会生成结果或将结果写入外部存储。然后,Spark会清理分配的资源并结束应用程序。
-
查看结果: 最后,开发人员可以查看应用程序生成的结果,这些结果可以存储在文件系统、数据库或其他外部存储中,具体取决于应用程序的要求。
2. spark与flink的区别
Spark:
Apache Spark是一个开源的通用分布式计算框架,旨在高效地处理大规模数据。它提供了丰富的API和库,支持批处理、交互式查询、流处理和机器学习等多种数据处理工作负载。
优点:
-
通用性:Spark是一个通用的数据处理框架,可以用于各种工作负载,包括批处理、实时流处理、图处理和机器学习。
-
性能:Spark的内存计算模型可以加速数据处理,特别适合迭代式算法和复杂的数据处理任务。
-
生态系统:Spark拥有广泛的生态系统,包括Spark SQL、MLlib(机器学习库)、GraphX(图处理库)等高级库,可以扩展其功能。
-
易用性:Spark支持多种编程语言(Scala、Java、Python和R),并提供易于使用的API,降低了学习曲线。
缺点:
-
处理延迟:对于流式数据处理,Spark通常采用微批处理模型,导致一定的处理延迟。
-
资源管理:Spark需要依赖外部资源管理器(如YARN或Mesos),这可能引入一些复杂性。
Flink:
Apache Flink是一个流处理和批处理的分布式数据处理引擎。它专注于实时数据流处理,支持事件时间处理和精确一次处理语义。
优点:
-
低延迟:Flink是一个真正的流处理框架,支持低延迟的实时数据处理,适合需要快速响应的应用程序。
-
事件时间处理:Flink内置了强大的事件时间处理支持,可以处理带有事件时间的数据,适用于复杂的窗口操作和事件时间分析。
-
精确一次处理:Flink支持精确一次处理语义,确保数据处理的准确性,即使在发生故障时也不会丢失数据。
-
状态管理:Flink提供了强大的状态管理机制,支持有状态的应用程序,如会话窗口和迭代算法。
缺点:
-
生态系统相对较小:相对于Spark,Flink的生态系统规模相对较小,但不断增长。
-
学习曲线:Flink的一些概念,如事件时间处理和状态管理,对新手来说可能需要一些时间来理解和掌握。
使用场景:
Spark 适用于:
- 批处理任务,尤其是需要高性能的批处理。
- 交互式查询和数据探索。
- 机器学习和图处理任务。
- 需要通用数据处理框架来处理多种工作负载的场景。
Flink 适用于:
- 实时数据处理,特别是需要低延迟和高吞吐量的场景。
- 事件时间处理非常重要的流处理应用,如实时数据分析和监控。
- 有状态应用程序,如会话窗口和复杂的迭代算法。
- 需要精确一次处理语义的数据管道。
区别:
-
处理模型:Spark主要基于批处理模型,而Flink是一个真正的流处理框架,可以实现低延迟的实时数据处理。
-
延迟:Spark通常具有较高的处理延迟,而Flink专注于降低延迟。
-
事件时间处理:Flink在事件时间处理方面表现出色,适用于需要考虑事件发生时间的应用程序,而Spark Streaming的事件时间处理相对较弱。
-
状态管理:Flink提供了强大的状态管理机制,可以用于处理有状态的应用程序,而Spark的有状态处理相对较弱。
3. rdd序列化
在Apache Spark中,RDD(Resilient Distributed Dataset)是一种分布式数据结构,用于表示分布式数据集。RDD是Spark的核心抽象,它可以在分布式计算中进行高效地并行处理。当数据从一个节点传递到另一个节点时,需要对RDD的元素进行序列化和反序列化,以便在网络上传输。这是因为不同节点可能使用不同的编程语言和类加载器,因此需要将数据序列化为一种通用格式。
以下是有关Spark中的RDD序列化的重要信息:
-
默认序列化: Spark使用Java对象序列化(Java Object Serialization)作为默认的RDD序列化机制。这意味着当您创建RDD并在集群节点之间传递数据时,Spark会将数据转换为Java序列化格式。
-
Kryo序列化: 尽管Java对象序列化是默认的序列化方法,但Spark也支持Kryo序列化,它比Java序列化更高效,可以显著提高性能。Kryo是一个快速的二进制对象图形序列化库,它比Java序列化更紧凑,速度更快。
-
自定义类的序列化: 如果您在Spark应用程序中使用自定义类,这些类必须实现
Serializable接口(对于Java序列化)或进行适当的配置以支持Kryo序列化。通常,您需要注册自定义类以便Spark能够正确序列化和反序列化它们。 -
避免序列化问题: 序列化问题可能导致性能下降或应用程序崩溃。为了避免这些问题,应避免在RDD中引用大型对象,而是将其传递给计算函数,以便在任务内部进行序列化。
-
Kryo注册: 如果您选择使用Kryo序列化,通常需要注册您的自定义类以便Kryo能够正确地序列化和反序列化它们。这可以通过Spark配置中的
spark.kryo.register属性完成。 -
序列化性能调整: 您可以在Spark配置中调整序列化设置,以便根据应用程序的需求选择性能或兼容性。例如,可以设置
spark.serializer属性来选择使用Java序列化还是Kryo序列化。
总之,在Spark中,RDD的序列化是重要的,因为它影响到分布式计算的性能和稳定性。您可以选择使用默认的Java对象序列化或更高性能的Kryo序列化,同时需要注意正确配置和管理自定义类的序列化以确保应用程序的顺利运行。
4. 持久化
在Apache Spark中,持久化(Persistence)是一种将RDD(Resilient Distributed Dataset)或DataFrame缓存到内存中,以便在之后的操作中重复使用的技术。持久化可以显著提高Spark应用程序的性能,因为它可以避免在每次需要RDD时重新计算它们。下面是有关Spark中持久化的详细信息:
持久化的步骤:
-
创建RDD或DataFrame: 首先,您需要创建一个RDD或DataFrame,这可以是从外部数据源加载的数据,也可以是通过Spark转换操作生成的数据集。
-
调用
persist()或cache()方法: 要将RDD或DataFrame持久化到内存中,您需要在它上面调用persist()或cache()方法。这两者都可以将数据缓存到内存中,以便后续重复使用。 -
指定持久化级别:
persist()和cache()方法还可以接受一个可选的持久化级别参数,用于指定持久化的策略。常见的持久化级别包括:MEMORY_ONLY:将数据存储在内存中。MEMORY_ONLY_SER:将数据以序列化的形式存储在内存中,通常比MEMORY_ONLY更节省空间。DISK_ONLY:将数据存储在磁盘上,以释放内存。- 其他级别包括
MEMORY_ONLY_2、MEMORY_ONLY_SER_2等,它们可以复制数据以提高容错性。
-
触发持久化: Spark的持久化是懒惰的,也就是说,它不会立即执行,而是在遇到一个触发操作(如
count()、collect()等)时才会将数据持久化到内存中。 -
使用持久化数据: 一旦数据被持久化,您可以在后续的Spark操作中重复使用它,而不必重新计算。这可以显著提高性能,特别是对于迭代算法和复杂的数据处理工作负载。
持久化的使用场景:
-
迭代算法:在迭代算法中,持久化可以避免重复计算相同的数据,加速算法收敛速度。
-
交互式查询:对于交互式查询,持久化可以在多个查询之间共享相同的中间结果,减少查询响应时间。
-
复杂的数据处理流水线:当您有一个复杂的数据处理流水线时,可以将中间结果持久化以减少计算成本。
持久化的注意事项:
-
持久化需要消耗内存或磁盘空间,因此需要在内存和性能之间做出权衡。选择适当的持久化级别是重要的。
-
持久化的数据会在内存中占用空间,如果不再需要,可以使用
unpersist()方法将其从内存中释放。 -
持久化是一种容错机制,如果某个节点上的持久化数据丢失,Spark可以根据RDD的血统重新计算它。
总之,Spark中的持久化是一种重要的性能优化技术,可以通过缓存中间结果来减少计算成本,特别是在迭代算法和复杂数据处理工作负载中。持久化级别和数据释放的策略应根据具体的应用场景来选择。
5. 依赖关系
在Apache Spark中,依赖关系(Dependencies)用于描述RDD(Resilient Distributed Dataset)之间的血统关系,即一个RDD是如何从另一个RDD派生而来的。
窄依赖(Narrow Dependency):
- 窄依赖发生在转换操作(如
map、filter、union等)中,其中每个父分区仅生成一个子分区。 - 窄依赖是高效的,因为它不需要进行数据重洗或数据移动,每个子分区可以直接依赖于一个父分区。
- 在窄依赖中,每个子分区只依赖于一个父分区,没有数据重洗或数据移动操作。
优点:
- 高效:窄依赖是高效的,因为它不需要进行数据重洗或网络传输。
- 并行度高:每个子分区可以直接依赖于一个父分区,因此并行度较高,任务可以并行执行。
使用场景:
- 转换操作:窄依赖适用于转换操作,如
map、filter、union等,这些操作生成的子分区与父分区一一对应。
宽依赖(Wide Dependency):
- 宽依赖发生在转换操作中,其中每个父分区可能生成多个子分区,这意味着数据需要重新洗牌(Shuffle)或移动。
- 宽依赖通常是比较昂贵的操作,因为它需要跨多个节点进行数据重洗和网络传输。
- 宽依赖的示例包括
groupByKey、reduceByKey、join等需要数据重洗的操作。
优点:
- 灵活性:宽依赖允许在父分区和子分区之间进行多对多的关系,提供了更大的灵活性。
缺点:
- 昂贵:宽依赖通常是比较昂贵的操作,因为它需要跨多个节点进行数据重洗和网络传输。
- 性能下降:数据重洗和移动会导致性能下降,特别是在大规模数据处理中。
使用场景:
- 聚合操作:宽依赖适用于聚合操作,如
groupByKey、reduceByKey、join等,这些操作需要将具有相同键的数据进行合并或关联,可能会生成多个子分区。
区别:
-
数据重洗:窄依赖不需要数据重洗,而宽依赖通常需要将数据重新组织和移动,这是它们之间的主要区别。
-
性能:窄依赖通常更高效,因为它们避免了昂贵的数据重洗和移动操作。宽依赖可能导致性能下降。
-
并行度:窄依赖具有较高的并行度,因为每个子分区可以直接依赖于一个父分区,而宽依赖的并行度较低。
-
使用场景:窄依赖适用于一对一的映射关系,例如基本的转换操作。宽依赖适用于需要跨多个分区进行数据合并、关联或聚合的操作。
6. 任务划分
在Apache Spark中,任务划分(Task Scheduling)是指将作业(Job)划分为一系列可执行的任务(Task)的过程。任务划分是分布式计算框架中的一个关键步骤,它将作业分解成小任务,然后将这些任务分配给集群中的执行器节点来并行执行。以下是有关Spark中任务划分的详细信息:
任务划分的过程:
-
作业划分: 一个Spark应用程序通常由多个作业组成。每个作业由一个或多个RDD转换操作组成,这些操作构成一个有向无环图(DAG)。
-
阶段划分: 每个作业被划分为若干个阶段(Stage)。一个阶段是一个DAG的一部分,其中所有的转换操作可以并行执行,而不需要等待前一个阶段的结果。
-
任务生成: 在每个阶段内,Spark将作业划分为一组具体的任务。每个任务负责处理RDD分区中的一部分数据。这些任务是作业的最小执行单位。
-
任务调度: 任务调度器将生成的任务分配给可用的执行器节点。任务调度可以基于数据本地性(Data Locality)来优化任务分配,以尽量减少数据传输和网络开销。
-
任务执行: 执行器节点接收任务并执行它们。每个任务都在独立的JVM进程中执行,以确保隔离性和容错性。
任务划分的优点:
-
并行性:任务划分允许多个任务在集群中并行执行,从而提高了计算速度和性能。
-
数据本地性:任务调度器可以优化任务分配,使得任务尽可能地在存储数据的节点上执行,减少了数据传输的开销。
-
容错性:任务划分和执行是容错的,如果某个任务失败,Spark可以重新调度该任务,或者在发生故障的节点上重新执行任务。
任务划分的使用场景:
任务划分是在Spark集群中并行执行作业的关键步骤,适用于各种Spark应用程序,包括批处理、交互式查询和流处理。任务划分允许Spark有效地利用集群中的多个节点来处理大规模数据,并提供了高性能和可伸缩性。
总结:
任务划分是Apache Spark中分布式计算的核心概念之一,它允许Spark应用程序将作业分解为可执行的任务,并在集群中并行执行这些任务。这个过程是Spark能够高效处理大规模数据并提供性能优势的关键之一。
7. 累加器
在Apache Spark中,累加器(Accumulator)是一种分布式变量,用于在并行计算中进行聚合操作。它们通常用于在分布式计算中对全局变量进行累积操作,如计数或总和。累加器是只写变量,每个任务都可以向累加器添加一个值,但只有驱动程序(Driver)可以读取其最终累积值。以下是有关Spark中累加器的详细信息:
累加器的特点:
-
分布式:累加器可以在分布式集群上的多个任务中进行操作,每个任务可以独立地将其值添加到累加器中。
-
只写:累加器是只写变量,任务可以将值添加到累加器中,但不能读取其值。只有驱动程序可以读取累积值。
-
容错性:累加器是容错的,即使在任务失败和重试的情况下,它们的值也能够正确地累积。
累加器的使用场景:
累加器通常用于以下情况:
-
计数器:累加器可用于计数操作,例如统计某个事件发生的次数。
-
总和:累加器可用于计算总和,例如对某个指标的累积。
-
日志记录:累加器可用于记录任务或作业中的特定事件,如错误计数或警告计数。
累加器的示例:
以下是一个使用累加器的示例,用于计算RDD中包含特定值的元素数量:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.util.AccumulatorV2;
public class AccumulatorExample {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("AccumulatorExample").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
// 创建一个自定义累加器并初始化为0
final AccumulatorV2<Integer, Integer> accumulator = new AccumulatorV2<Integer, Integer>() {
private int sum = 0;
@Override
public boolean isZero() {
return sum == 0;
}
@Override
public AccumulatorV2<Integer, Integer> copy() {
AccumulatorExample acc = new AccumulatorExample();
acc.sum = this.sum;
return acc;
}
@Override
public void reset() {
sum = 0;
}
@Override
public void add(Integer value) {
if (value == 1) { // 检查元素是否等于特定值
sum += 1;
}
}
@Override
public void merge(AccumulatorV2<Integer, Integer> other) {
if (other != null) {
sum += other.value();
}
}
@Override
public Integer value() {
return sum;
}
};
sc.sc().register(accumulator, "targetValueAccumulator"); // 注册累加器
JavaRDD<String> rdd = sc.parallelize(Arrays.asList("target_value", "other_value", "target_value", "another_value"));
// 使用累加器进行计数操作
rdd.foreach(value -> accumulator.add(value.equals("target_value") ? 1 : 0));
// 累加器的值只能在驱动程序中读取
System.out.println("Accumulator value: " + accumulator.value());
sc.close();
}
}在这个Java示例中,我们首先创建一个自定义的AccumulatorV2,然后在RDD上使用它来计算包含特定值的元素数量。最后,我们通过accumulator.value()方法在驱动程序中获取累加器的值。
总之,累加器是Spark中的一种强大的工具,用于在分布式计算中进行全局聚合操作。它们对于计数、总和和日志记录等任务非常有用,可以帮助开发人员更容易地了解和监控Spark作业的执行。
8. 广播变量
在Apache Spark中,广播变量(Broadcast Variables)是一种分布式共享的不可变变量,用于高效地将大数据结构或只读数据广播到集群中的所有工作节点,以便在并行计算中被多个任务共享。广播变量可以帮助减少数据传输的开销,提高Spark应用程序的性能。以下是有关Spark中广播变量的详细信息:
广播变量的特点:
-
不可变性:广播变量一旦创建就不可更改。它们是只读的,不能在任务中修改。
-
高效共享:广播变量将数据缓存在工作节点的内存中,以便多个任务可以高效地共享相同的数据,而无需重复传输。
-
分布式共享:广播变量在集群中的所有节点之间共享,可用于跨任务、跨节点访问相同的数据。
广播变量的使用场景:
广播变量通常用于以下情况:
-
小数据集广播:当需要在Spark任务之间共享小型数据集时,如配置信息、字典、映射表等。
-
减少数据传输开销:当涉及大型数据结构时,广播变量可以帮助减少网络传输的开销,提高性能。
-
不可变数据:广播变量通常包含不可变(immutable)的数据,因为它们在创建后不能被修改。
创建和使用广播变量:
在Spark中,要创建和使用广播变量,可以按照以下步骤:
-
创建要广播的数据,通常是一个不可变数据结构,例如一个集合、字典或配置对象。
-
使用
SparkContext的broadcast()方法将数据转换为广播变量。例如:
Broadcast<List<String>> broadcastVar = sparkContext.broadcast(Arrays.asList("value1", "value2"));
3.在任务中使用广播变量的值。广播变量可以在任务内部访问,而不需要从驱动程序传输数据。
broadcastVar.value().forEach(value -> {
// 在任务中使用广播变量的值
System.out.println(value);
});
示例:
以下是一个示例,演示了如何在Spark中创建和使用广播变量:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.broadcast.Broadcast;
import java.util.Arrays;
import java.util.List;
public class BroadcastVariableExample {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("BroadcastVariableExample").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<String> data = Arrays.asList("value1", "value2", "value3");
Broadcast<List<String>> broadcastVar = sc.broadcast(data);
sc.parallelize(Arrays.asList(1, 2, 3)).foreach(value -> {
List<String> broadcastValue = broadcastVar.value();
broadcastValue.forEach(item -> System.out.println(item + " " + value));
});
sc.close();
}
}在这个示例中,我们创建了一个广播变量broadcastVar,并在Spark任务中使用它来访问共享的数据。这样,无论在集群中的哪个节点上执行任务,都可以访问相同的数据,而无需重复传输。这可以显著提高性能,特别是在涉及大型数据结构时。
9. shuffle
在Apache Spark中,Shuffle(洗牌)是指重新分配和重新组织数据的过程,通常发生在Spark作业的某些转换操作中,如groupByKey、reduceByKey、join等需要根据键重新分区或重新排列数据的操作中。Shuffle是Spark中的一个关键操作,它会导致数据在集群中的节点之间移动,因此在性能优化中需要特别关注。以下是有关Spark中Shuffle的详细信息:
Shuffle的过程:
-
数据分区:在转换操作中,数据根据某个键或条件进行分区,这会将数据集划分为多个分区。每个分区包含一组具有相同键的数据。
-
数据移动:在Shuffle过程中,数据需要从计算节点传输到不同的节点,以便将相同键的数据汇总到一起。这可能涉及网络传输,因此是计算开销较高的操作。
-
数据重洗:Shuffle过程还可能涉及数据的重新组织,以确保数据按键分组。这可能包括将数据进行排序、合并或重新分区。
-
写入磁盘:在Shuffle期间,中间数据通常会被写入磁盘,以便在需要时进行持久化和容错处理。
Shuffle的优点:
-
数据重组:Shuffle允许对数据进行重新组织,以满足特定操作的需求,如聚合、连接和分组操作。
-
并行性:Shuffle过程可以并行执行,以便高效处理大规模数据。
-
数据本地性:Shuffle操作通常会尽量在数据所在的节点上执行,以减少数据传输开销。
Shuffle的缺点:
-
性能开销:Shuffle是计算密集型和开销较高的操作,可能导致作业的性能下降。
-
数据传输:Shuffle涉及数据在节点之间的传输,可能引发网络瓶颈,特别是在大规模集群上。
使用场景:
-
Reduce操作:Shuffle常用于执行Reduce操作,其中相同键的数据被汇总到一起。例如,通过
reduceByKey操作,可以将具有相同键的数据进行聚合。 -
Group操作:在进行分组操作时,Shuffle也是必需的。通过
groupByKey操作,可以将具有相同键的数据分组在一起,以便进行进一步的分析或计算。 -
Join操作:在进行连接操作时,Shuffle通常是必要的,因为它需要将具有相同连接键的数据从不同的数据集中移动和合并在一起。
-
排序操作:在进行排序操作时,Shuffle可以用于重新分区数据以进行排序。例如,通过
sortByKey操作,可以对键值对RDD进行排序。 -
聚合操作:聚合操作通常涉及Shuffle,例如使用
aggregateByKey或combineByKey进行数据聚合。 -
数据去重:如果要从数据中删除重复项,Shuffle可能需要用于将数据重新组织以查找和删除重复项。
-
数据合并:当需要将多个数据集合并在一起时,Shuffle可以用于合并数据,例如通过
union操作。 -
数据重分区:有时候,需要将数据重新分区以实现负载均衡或满足特定计算需求。Shuffle可以用于这些情况。
Shuffle的性能优化:
为了最小化Shuffle的性能开销,可以考虑以下优化策略:
-
合理的分区数量:通过设置适当的分区数量,可以减少Shuffle的数据传输开销。分区数量不足可能导致不均衡的任务,而分区数量过多可能会导致任务之间的竞争。
-
宽依赖优化:尽量减少宽依赖(Wide Dependency),因为它们通常会触发Shuffle操作。例如,使用
reduceByKey代替groupByKey来降低Shuffle的开销。 -
使用广播变量:对于小数据集,可以使用广播变量来避免Shuffle操作。
-
数据本地性:通过优化数据本地性,尽量在存储数据的节点上执行任务,减少数据传输。
总之,Shuffle是Spark中的一个重要概念,用于重新组织和重分区数据,以支持各种数据处理操作。了解Shuffle的过程和性能优化策略对于编写高效的Spark应用程序至关重要。在设计Spark作业时,需要权衡数据重组的需求和性能开销,以实现最佳的执行性能。
10. 数据倾斜
在Apache Spark中,数据倾斜(Data Skew)是指在分布式计算过程中,部分数据分区包含了远远多于其他分区的数据量,导致某些任务的执行速度明显慢于其他任务。数据倾斜可能会导致Spark应用程序的性能下降,因为某些任务需要更长的时间来完成,从而影响整个作业的完成时间。数据倾斜通常出现在以下情况下:
-
不均匀的键分布:在进行分组、连接或聚合等需要基于键的操作时,如果键的分布不均匀,某些键可能会具有远远多于其他键的数据项,导致数据倾斜。
-
原始数据分布不均匀:原始数据分布不均匀,可能导致在进行数据转换操作时出现数据倾斜。例如,在某些数据分区中有大量的异常值或重复数据。
-
数据倾斜问题的解决策略:
-
增加分区数:增加RDD的分区数可以减少每个分区的数据量,从而减轻数据倾斜的问题。可以使用
repartition()或coalesce()等操作来增加或减少分区数。 -
合理选择数据分区策略:在进行分区操作时,可以考虑采用合理的分区策略,以使数据均匀分布。例如,使用
repartition时,可以指定合适的分区键,以确保数据均匀分布在各个分区中。 -
使用累加器进行统计:在遇到数据倾斜问题时,可以使用累加器来统计数据的分布情况,以便识别倾斜的键或分区。
-
使用Spark的一些特定操作:Spark提供了一些特定的操作来处理数据倾斜问题,如
reduceByKey的combineByKey参数,可以用于合并具有相同键的数据项,减少Shuffle开销。 -
使用自定义分区器:在需要自定义分区逻辑时,可以实现自定义分区器,以确保数据分布均匀。
-
过滤掉倾斜数据:在某些情况下,可以选择丢弃或过滤掉倾斜数据,以便继续作业。这通常需要业务逻辑的支持。
-
使用外部存储:对于极端数据倾斜的情况,可以考虑将倾斜的数据存储在外部存储中,然后进行处理,以减轻内存和计算资源的压力。
-
11. 调优
Apache Spark的性能调优是确保Spark应用程序在大规模数据处理时获得高性能和可伸缩性的关键步骤之一。下面是一些Spark性能调优的详细方法和策略:
-
了解作业和数据:
-
分析作业:首先,分析你的Spark作业,了解其结构和性能瓶颈。使用Spark的Web UI、监控工具和日志来获取关于作业执行的信息。
-
理解数据分布:了解数据的分布情况,包括键的分布、数据倾斜等,以便更好地选择数据分区策略和操作。
-
-
合理设置资源:
-
内存分配:通过调整
spark.driver.memory和spark.executor.memory来合理配置内存。确保不过度分配内存,以避免频繁的垃圾回收。 -
CPU核心和线程数:根据集群规模和硬件配置,调整
spark.executor.cores和spark.cores.max,以合理分配CPU资源。
-
-
数据存储和持久化:
-
使用内存和磁盘存储级别:根据数据访问模式选择适当的存储级别(Memory-Only、Memory-and-Disk、Disk-Only等)。
-
持久化中间结果:在多次使用相同数据时,考虑使用
persist()或cache()持久化中间结果,以避免重复计算。
-
-
调整并行度:
-
设置分区数:通过
repartition()或coalesce()来调整RDD的分区数,以匹配集群大小和任务并行度。 -
避免宽依赖:尽量避免使用宽依赖操作,如
groupByKey,而使用窄依赖操作,如reduceByKey,以减少Shuffle开销。
-
-
数据倾斜处理:
-
使用自定义分区器:在需要时使用自定义分区器来处理数据倾斜问题,以确保数据均匀分布。
-
过滤或处理倾斜数据:在极端情况下,可以选择过滤或特殊处理倾斜的数据,以减轻性能影响。
-
-
动态分配资源:
- 启用动态资源分配:通过设置
spark.dynamicAllocation.enabled为true,启用动态资源分配,根据任务需求动态分配资源。
- 启用动态资源分配:通过设置
-
并行度控制:
-
控制并发任务数:根据硬件资源,控制同时运行的任务数量,以避免资源竞争。
-
队列和调度器:使用Spark的任务调度器或与其他调度器(如YARN)集成,以管理任务的并发执行。
-
-
广播变量:
- 使用广播变量:对于小型数据集,使用广播变量来共享数据,以避免数据重复传输。
-
数据本地性:
- 优化数据本地性:通过选择合适的数据存储和分区策略,优化数据本地性,减少数据传输开销。
-
监控和调试:
-
监控作业:使用Spark的Web UI、监控工具和日志来监控作业的执行情况,及时发现问题。
-
调试工具:使用Spark的调试工具来识别性能瓶颈,如使用
spark-submit的--conf spark.eventLog.enabled=true启用事件日志。
-
-
版本和配置:
-
使用最新版本:确保使用Spark的最新版本,因为每个新版本通常都包含性能和优化改进。
-
配置调整:根据集群和作业的需求,调整Spark的配置参数,以达到最佳性能。
-
-
容错性和检查点:
-
启用检查点:在长时间运行的作业中,启用检查点来定期保存RDD的中间结果,以减小作业失败后的恢复成本。
-
容错机制:了解Spark的容错机制,如血统图(Lineage)和Checkpoint,以确保作业在失败后能够正确恢复。
-
-
资源管理器:
- 集成资源管理器:根据集群的资源管理器(如YARN、Mesos等)集成Spark,以更好地管理资源。
这些是一些常见的Spark性能调优策略和方法。在实际应用中,性能调优通常需要根据具体的应用和集群情况进行定制化。最佳的调优策略通常需要深入了解作业和数据,以更好地满足性能需求。
12. Rdd、DataFrame、DataSet之间的区别
在Apache Spark中,RDD(Resilient Distributed Dataset)、DataFrame和DataSet是三种不同的数据抽象,用于表示和处理分布式数据集。它们各自有不同的特点、优缺点和适用场景,下面分别介绍它们:
-
RDD(Resilient Distributed Dataset):
-
什么是RDD:RDD是Spark中最早引入的数据抽象,它代表一个分布式的、不可变的数据集。RDD可以容错、可并行处理,并且具有弹性(resilient)的特性,即在节点故障时能够自动恢复。
-
作用:RDD提供了一种通用的数据操作接口,允许开发人员在分布式环境中执行各种数据操作,如转换、过滤、聚合等。
-
优缺点:
- 优点:灵活,适用于各种数据处理场景,可以通过编程控制数据操作。
- 缺点:编程复杂度较高,需要手动管理数据结构和序列化/反序列化。
-
使用场景:RDD适用于需要精细控制数据处理流程的复杂数据处理任务,以及需要低级别的定制性操作的场景。
-
-
DataFrame:
-
什么是DataFrame:DataFrame是Spark中的一种数据抽象,它是一个以列为基础的分布式数据集,类似于传统数据库表或Excel表格。DataFrame具有模式(Schema),可以包含不同类型的数据列。
-
作用:DataFrame提供了高度优化的数据查询和处理接口,支持SQL查询、数据过滤、聚合、连接等操作。
-
优缺点:
- 优点:支持高度优化的查询和处理,易于使用,具有SQL和DataFrame API。
- 缺点:不如RDD灵活,不适用于一些需要精细控制的操作。
-
使用场景:DataFrame适用于需要进行高效数据查询和处理的数据分析任务,以及需要使用SQL查询的场景。
-
-
DataSet:
-
什么是DataSet:DataSet是Spark 1.6版本引入的,它是RDD和DataFrame的结合体,具有RDD的强类型(类型安全)特性和DataFrame的高级查询功能。
-
作用:DataSet既支持编程方式的数据处理,也支持SQL查询,同时提供了强类型的数据抽象,允许编译时类型检查。
-
优缺点:
- 优点:既有强类型的数据操作,又支持高级查询,具有类型安全和性能优化。
- 缺点:相对于DataFrame,DataSet的API较复杂,需要更多的类型定义。
-
使用场景:DataSet适用于需要类型安全、高性能和高级查询功能的数据处理任务。
-
区别和选择:
- RDD是最基础的抽象,提供了最大的灵活性,但需要开发人员手动管理数据和序列化/反序列化。
- DataFrame提供了高度优化的查询和处理,适用于数据分析和SQL查询。
- DataSet是RDD和DataFrame的结合,提供了强类型和高级查询功能,适用于需要类型安全和高性能的任务。
选择哪种数据抽象取决于任务的性质和要求。一般而言:
- 如果需要进行复杂的数据处理,需要精细控制每个操作步骤,可以选择使用RDD。
- 如果主要进行数据分析和SQL查询,可以选择使用DataFrame。
- 如果需要兼顾性能和类型安全,可以选择使用DataSet。
在实际开发中,Spark的高级API和SQL功能通常足以满足大多数需求,因此大多数任务可以使用DataFrame或DataSet。然而,对于一些特殊情况,如需要自定义数据操作或复杂计算逻辑的任务,可能需要使用RDD。
Kafka
1. 架构
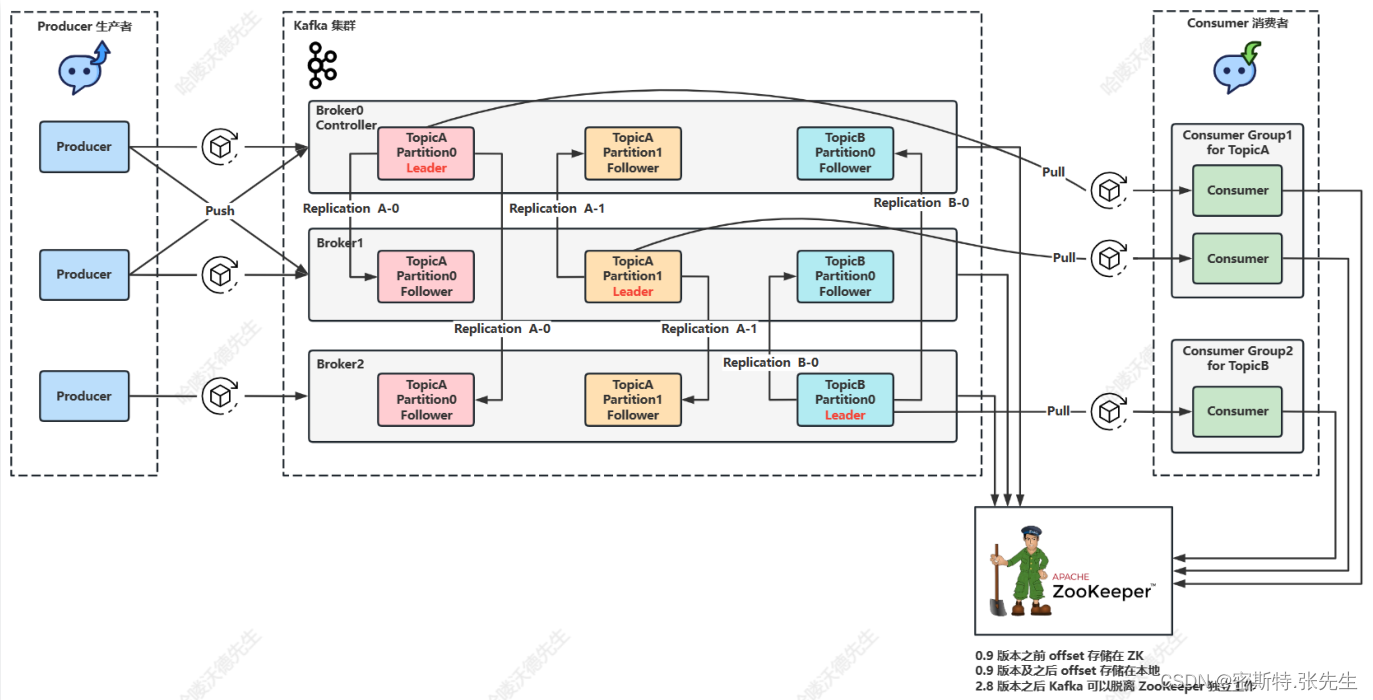
Kafka是一种分布式流数据平台,用于高效地传输、存储和处理数据流。它的架构设计旨在处理大规模的数据流,并提供高可用性和可扩展性。下面是Kafka的详细架构解释:
1. 主题(Topics): Kafka中的数据流被组织成主题。主题是数据的逻辑通道,用于将相关的消息分组在一起。每个主题都可以分成多个分区。
2. 分区(Partitions): 主题可以被分成多个分区,每个分区都是一个有序的、不可变的消息序列。分区允许Kafka水平扩展,每个分区可以分布在不同的服务器上。分区中的每个消息都有一个唯一的偏移量(offset),用于标识消息在分区中的位置。
3. 生产者(Producers): 生产者是将消息发布到Kafka主题的应用程序或系统。生产者负责将消息发送到指定主题的一个或多个分区。消息可以是文本、二进制数据或任何其他格式。
4. 消费者(Consumers): 消费者是从Kafka主题订阅并处理消息的应用程序或系统。消费者可以订阅一个或多个主题,并从指定主题的一个或多个分区读取消息。
5. 消费者组(Consumer Groups): 消费者可以组成消费者组。每个消费者组中的消费者共享订阅的主题,但每个分区只能由消费者组中的一个消费者处理。这允许在Kafka中实现水平扩展和负载均衡。
6. 副本(Replicas): Kafka使用数据的副本来提供高可用性。每个分区可以配置多个副本,其中一个是主副本(Leader),其余的是从副本(Followers)。主副本负责写入数据,而从副本用于备份数据和提供故障转移。如果主副本失败,一个从副本会被选举为新的主副本。
7. Broker: Kafka集群由多个Kafka Broker组成,每个Broker是一个独立的Kafka服务器实例。每个Broker可以托管多个分区和副本,并负责消息的存储和传输。Kafka Broker之间可以协作以确保数据的可用性和可靠性。
8. ZooKeeper: 在Kafka的早期版本中,ZooKeeper用于协调和管理Kafka集群的元数据。从Kafka 2.8.0版本开始,Kafka引入了KRaft协议,用于替代ZooKeeper,以简化Kafka的运维和部署。
9. 生产者确认(Producer Acknowledgments): 生产者可以配置确认机制,以确保消息已经被成功写入Kafka分区。这包括“全部”确认(all),意味着所有副本都已经确认接收消息,以及“分区”确认(partition),意味着只需主副本确认接收消息。
10. 数据保留策略(Data Retention Policies): Kafka允许配置数据保留策略,以控制消息在主题中的保留时间。消息可以根据时间或大小进行保留,过期的消息将自动删除。
11. 消息压缩(Message Compression): Kafka支持对消息进行压缩,以减少网络传输和存储开销。
总的来说,Kafka的架构是分布式的、高可用的,并且具有良好的可扩展性。它可以处理大规模的数据流,适用于各种应用场景,如日志收集、实时数据分析和事件驱动的应用程序。通过合理的配置和部署,Kafka可以提供高吞吐量、低延迟和高度可靠的数据传输和处理。
2. 分区分配策略
Kafka的分区分配策略用于将消费者组中的消费者分配给订阅的主题的分区,以实现负载均衡和高可用性。Kafka支持不同的分区分配策略,每种策略都有不同的用例和权衡考虑。以下是一些常见的分区分配策略:
1. 轮询策略(Round Robin): 这是最简单的策略,消费者依次从主题的分区列表中获取分区。每个消费者在每个轮询中获取一个分区,然后处理该分区的消息。这个策略非常简单,但可能导致不均衡,因为分区的大小和消息处理速度可能不同。
2. 范围策略(Range Assignment): 在这个策略中,每个消费者被分配一个或多个连续的分区范围。这意味着每个消费者将负责处理一系列连续的分区,可以更好地实现负载均衡,因为消费者之间分区数的差异较小。
3. 最小负载策略(Least Loaded): 这个策略会将分区分配给当前负载最轻的消费者。它需要监视每个消费者的负载情况,然后选择负载最轻的消费者来分配分区。这种策略可以实现较好的负载均衡,但需要额外的管理开销。
4. 定制策略(Custom Assignment): 如果上述策略无法满足特定需求,可以实现自定义的分区分配策略。这可以根据应用程序的需求来灵活地分配分区,但需要编写自定义代码来实现。
5. Sticky策略: 这是一种改进的轮询策略,它尝试在每个消费者和分区之间维护一种“粘性”的关系,以确保相同的消费者在不同轮询之间继续处理相同的分区。这有助于降低消息重新排序的风险,但可能会导致不均衡。
6. 固定分区策略(Fixed Partition Assignment): 这个策略允许消费者明确指定要处理的分区。这对于需要特定分区的应用程序很有用,但需要手动管理分区的分配。
需要注意的是,分区分配策略的选择取决于特定应用程序的需求和性能目标。通常情况下,范围策略和最小负载策略被认为是较好的选择,因为它们可以实现较好的负载均衡。但是,不同的应用场景可能需要不同的策略,因此需要根据具体情况进行选择或实现自定义策略。在Kafka的消费者API中,可以通过配置partition.assignment.strategy属性来指定所需的策略。
3. 数据不丢失 ACK机制 精确一次消费

Kafka的ACK(Acknowledgment)机制是用于确保生产者(Producer)发送的消息被成功写入Kafka分区并复制到指定数量的副本的一种机制。这个机制涉及到消息的可靠性传递,以防止数据丢失。Kafka的ACK机制包括以下几个重要概念和部分:
1. 消息发送: 生产者将消息发送到Kafka主题中的一个或多个分区。每个分区可以配置为有多个副本。
2. ISR(In-Sync Replicas): ISR是指那些在主副本(Leader Replica)和生产者之间保持同步的分区副本。只有ISR中的副本才能参与ACK机制。
3. Min ISR配置: 生产者在发送消息时可以配置一个参数min.insync.replicas,它指定了消息必须写入的最小ISR数目。生产者会等待消息被写入足够多的ISR副本后才会认为消息已成功发送。
4. ACK级别: 在Kafka中,有三个主要的ACK级别:
acks=0:生产者发送消息后不会等待任何ACK,将消息立即视为已发送成功。这是最低的可靠性级别,可能会导致消息丢失。acks=1:生产者发送消息后会等待主副本的ACK。一旦主副本确认接收消息,生产者就会认为消息已成功发送,但不会等待其他副本的ACK。这提供了一定程度的可靠性,但仍然可能导致消息丢失。acks=all:生产者发送消息后会等待ISR中的所有副本都确认接收消息的ACK。只有在所有ISR副本都成功接收消息时,生产者才会认为消息已成功发送。这提供了最高级别的可靠性,但需要更多的时间和资源。
5. 消息确认: 当生产者发送一条消息并等待ACK时,如果消息成功写入足够多的ISR副本,Kafka会返回一个ACK给生产者,表示消息已经成功写入。如果ACK没有在超时时间内收到,生产者可以选择重试发送消息。
6. 消息重试: 如果生产者未收到ACK或收到了错误的ACK,它可以选择重试消息的发送。这可以确保消息最终被成功写入Kafka。
7. 可靠性权衡: 选择ACK级别涉及到可靠性和性能的权衡。acks=all提供最高的可靠性,但可能会导致较高的延迟,而acks=0提供了最低的延迟,但可靠性较低。在实际应用中,需要根据业务需求来选择适当的ACK级别。
总的来说,Kafka的ACK机制允许生产者在消息被成功写入ISR副本后才确认消息的发送,从而提供了一定程度的消息可靠性。这种可靠性可以根据应用程序的需求进行配置,以权衡可靠性和性能。
4. 数据不重复
Kafka 是一个分布式流数据平台,设计用于可靠地发布和订阅数据流。在 Kafka 中,确保数据不重复是非常重要的,这是通过以下方式实现的:
-
分区和副本:Kafka 主题被分成多个分区,每个分区可以有多个副本。数据被分区存储,而不同的副本会分布在不同的 Kafka 服务器上。这有助于数据的冗余存储和容错性,确保即使某个服务器故障,数据仍然可用。
-
消息发布确认:生产者在将消息发布到 Kafka 主题时可以选择等待生产者接收到确认消息。这意味着只有当 Kafka 成功接收并复制了消息到至少一个副本时,生产者才会收到确认。如果生产者没有收到确认,它可以选择重新发布消息,从而确保消息不会丢失。
-
消息偏移量(Offset):Kafka 使用消息偏移量来唯一标识每个消息。消费者跟踪它们消费的消息的偏移量,这有助于确保消费者不会重复消费相同的消息。Kafka 会为每个消费者维护一个偏移量,并在消费者提交消息偏移量时进行管理。
-
消费者组:Kafka 允许多个消费者协作来消费相同的主题。这些消费者可以组成一个消费者组,而每个分区只能由一个消费者组中的一个消费者消费。这确保了每条消息只会被消费者组中的一个消费者处理,从而避免了重复消费。
-
消息保留策略:Kafka 允许配置消息在主题中的保留时间。一旦消息过期,它将被自动删除,以确保不会无限制地积累数据。
总之,Kafka 通过分区、副本、确认机制、偏移量管理、消费者组和消息保留策略等多种机制来确保数据在传输和消费过程中不会出现重复或丢失的问题。这些机制使得 Kafka 成为一个可靠的流数据处理平台,适用于各种实时数据处理和消息传递应用场景。
5. 幂等性
在Kafka中,幂等性是一种特性,它确保相同的消息不会被重复写入或处理,即使生产者重试发送消息或者网络出现问题。这个特性对于保证数据的一致性和可靠性非常重要。以下是关于Kafka中幂等性的一些要点:
-
生产者的幂等性:Kafka生产者可以配置为产生幂等性的消息,这意味着无论发送多少次相同的消息,Kafka都将确保只有一次副本被写入分区。生产者通过为每个消息分配一个唯一的序列号(称为生产者消息ID)来实现幂等性。当消息被发送到Kafka时,Kafka会使用这个消息ID来检查是否已经接收过相同的消息,如果已经接收过,则不会重复写入。
-
幂等性保证:Kafka的幂等性是通过生产者端来实现的,而不是Kafka服务器端。生产者会在消息上附加一个幂等性标记,然后Kafka服务器在写入消息之前会检查这个标记。如果消息已经被写入,Kafka会返回成功响应,但不会将消息再次写入,从而实现幂等性。
-
幂等性语义:Kafka的幂等性不仅仅是为了防止消息的重复写入,还涵盖了消息的顺序性。即使在生产者发送的消息中出现了重试或乱序的情况,Kafka也能够确保消息按照相同的顺序和完整性被写入分区。
-
幂等性配置:为了启用生产者的幂等性,需要设置
enable.idempotence配置为true。此外,还需要为每个消息分配一个唯一的生产者消息ID。这个消息ID可以由开发人员自行生成,也可以由Kafka自动生成。 -
注意事项:虽然Kafka的幂等性可以确保消息不会被重复写入,但仍然需要注意消息的传递和处理可能会失败。因此,生产者应该实施适当的重试策略,以确保消息最终被成功写入。
总之,Kafka中的幂等性是一种重要的特性,它有助于确保消息在发送和写入过程中不会被重复处理,从而提高了数据的一致性和可靠性。这对于构建可靠的分布式应用程序和数据流处理系统非常重要。
6. 事务性
在Kafka中的事务性是指能够确保一组消息要么全部成功写入,要么全部失败,同时还能保持消息的顺序性。这个特性对于需要强一致性和可靠性的应用非常重要,特别是在金融、电子商务等领域。以下是关于Kafka中事务性的一些要点:
-
事务性生产者:Kafka引入了事务性生产者,通过配置事务性生产者,可以确保一组相关的消息要么全部成功写入Kafka,要么全部失败。这使得在生产者端能够实现原子性操作。
-
事务性主题:在Kafka中,可以创建支持事务的主题。只有在事务性主题上的消息才能参与到事务中。这确保了只有那些需要原子性保证的消息才会被包含在事务中。
-
事务性保证:Kafka的事务性保证包括ACID(原子性、一致性、隔离性、持久性)属性。事务性生产者可以开启一个事务,将一组消息发送到Kafka主题,然后要么将它们全部写入,要么全部丢弃,不会出现部分写入的情况。Kafka服务器会追踪事务中的消息,确保它们按照预期的方式写入分区。
-
事务性确认:事务性生产者在事务完成时会收到确认,这意味着所有包含在该事务中的消息都已经被成功写入或全部失败。如果事务失败,那么所有在该事务中的消息都将被回滚,不会写入Kafka。
-
顺序性:Kafka能够确保在事务中的消息按照它们的顺序写入分区。这意味着即使在并发环境下,事务性消息也会按照预期的顺序写入和读取。
-
事务性消费者:除了事务性生产者,Kafka还支持事务性消费者,这使得在消费消息时能够与生产事务性消息相匹配,确保在消费方也能实现一致性。
总之,Kafka中的事务性能够确保一组消息的原子性和一致性,使得在复杂的分布式系统中能够构建可靠的数据流处理应用。这对于需要高度可靠性和数据一致性的应用场景非常重要,如金融交易处理和订单管理系统。
7. 高吞吐的本质
Kafka 之所以能够实现高吞吐量,其本质在于其设计和架构的一些关键特性,以及合理的配置和优化。以下是 Kafka 中实现高吞吐量的本质因素:
-
分布式架构:Kafka 是一个分布式系统,它的架构允许数据分布在多个节点上。分区和副本的概念使得 Kafka 能够水平扩展,允许数据并行处理。这允许 Kafka 处理大量数据并实现高吞吐。
-
分区:Kafka 主题被分成多个分区,每个分区都可以独立地处理消息。这允许多个消费者同时处理不同分区的消息,从而提高了吞吐量。此外,分区还允许 Kafka 在多个节点上分布数据,以防止单点故障。
-
副本:Kafka 允许为每个分区创建多个副本,这提高了数据的可用性和容错性。副本可以分布在不同的节点上,使得即使某个节点故障,数据仍然可用。副本的复制也有助于提高读取吞吐量,因为多个消费者可以同时读取不同副本的数据。
-
持久性存储:Kafka 的消息是持久性存储的,它们被写入磁盘并保留一段时间(可以根据配置进行调整)。这允许消费者按需回放消息,即使它们在生产时已经离线或消费时发生故障。
-
批量处理:Kafka 支持批量生产和消费消息。生产者可以将多个消息打包成一个批次一次性发送,而消费者可以批量拉取和处理消息。这减少了网络开销和处理开销,有助于提高吞吐量。
-
零拷贝技术:Kafka 使用零拷贝技术,允许数据在内存之间传输而无需复制到用户空间。这减少了数据传输的开销,提高了性能。
-
并发处理:Kafka 的多线程设计允许多个生产者和消费者并行处理消息。它使用了多线程来处理网络请求、磁盘 I/O 和数据复制等操作,从而充分利用了多核处理器的性能。
-
缓存:Kafka 使用缓存来存储热门数据,例如最近使用的消息和索引信息。这减少了对磁盘的访问,提高了读取吞吐量。
总之,Kafka 的高吞吐量本质在于其分布式、持久性、并发、批处理、缓存等多种设计和优化策略的综合应用。这些特性使得 Kafka 成为处理大规模数据流和构建实时数据处理应用的强大工具。同时,合理的配置和集群规模的调整也是实现高吞吐量的关键。
8. 为什么快(零拷贝、页缓存)
Kafka之所以快速的一个关键因素是其有效利用了零拷贝和页缓存技术:
-
零拷贝技术:
-
减少数据复制:零拷贝技术允许数据在内核空间和用户空间之间传递,而无需进行额外的数据复制操作。在传统的I/O操作中,数据通常需要从应用程序缓冲区复制到内核缓冲区,然后再传输到目标缓冲区。这会导致额外的CPU和内存开销。Kafka使用零拷贝技术,使得数据可以直接从一个位置传输到另一个位置,减少了数据复制,降低了CPU负载。
-
提高网络吞吐量:在网络传输中,零拷贝技术允许数据直接从内核缓冲区发送到网络接口,而不需要中间的用户空间缓冲区。这可以显著提高网络吞吐量,降低了网络传输的延迟。
-
文件读写优化:Kafka使用零拷贝技术来读取和写入数据文件。这意味着当Kafka生产者将消息写入磁盘时,数据可以直接从生产者的内存传输到磁盘,而无需中间的数据复制步骤。同样,消费者可以从磁盘读取数据,然后通过零拷贝技术将数据传递到消费者的内存中,提高了磁盘I/O的效率。
-
-
页缓存技术:
-
内存中的数据缓存:Kafka利用操作系统的页缓存来缓存磁盘上的数据,包括消息日志文件。这使得 Kafka 能够快速地读取以及写入数据,因为数据通常可以从内存中读取,而无需进行磁盘访问。页缓存减少了对慢速磁盘的依赖,提高了读取和写入操作的速度。
-
加速重复数据访问:页缓存允许 Kafka 在读取时缓存已经访问过的数据页,因此如果相同的数据再次被读取,Kafka可以直接从内存中获取,而无需再次从磁盘加载,从而提高了读取吞吐量。
-
减少磁盘I/O开销:由于页缓存的存在,Kafka减少了需要进行的磁盘I/O操作,这减少了磁盘的访问延迟,提高了数据的读取和写入性能。
-
综上所述,Kafka之所以快速主要是因为它有效地利用了零拷贝技术和页缓存技术。零拷贝减少了数据复制和网络传输的开销,而页缓存允许 Kafka 在内存中缓存和高效地访问数据,降低了磁盘I/O延迟。这些技术共同作用使得 Kafka 成为一个高性能的分布式消息传递系统,适用于处理大规模的实时数据流。















 3627
3627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









