







文章目录
正则表达式转NFA,NFA转DFA,DFA化简
正则表达式转NFA
三条规则:
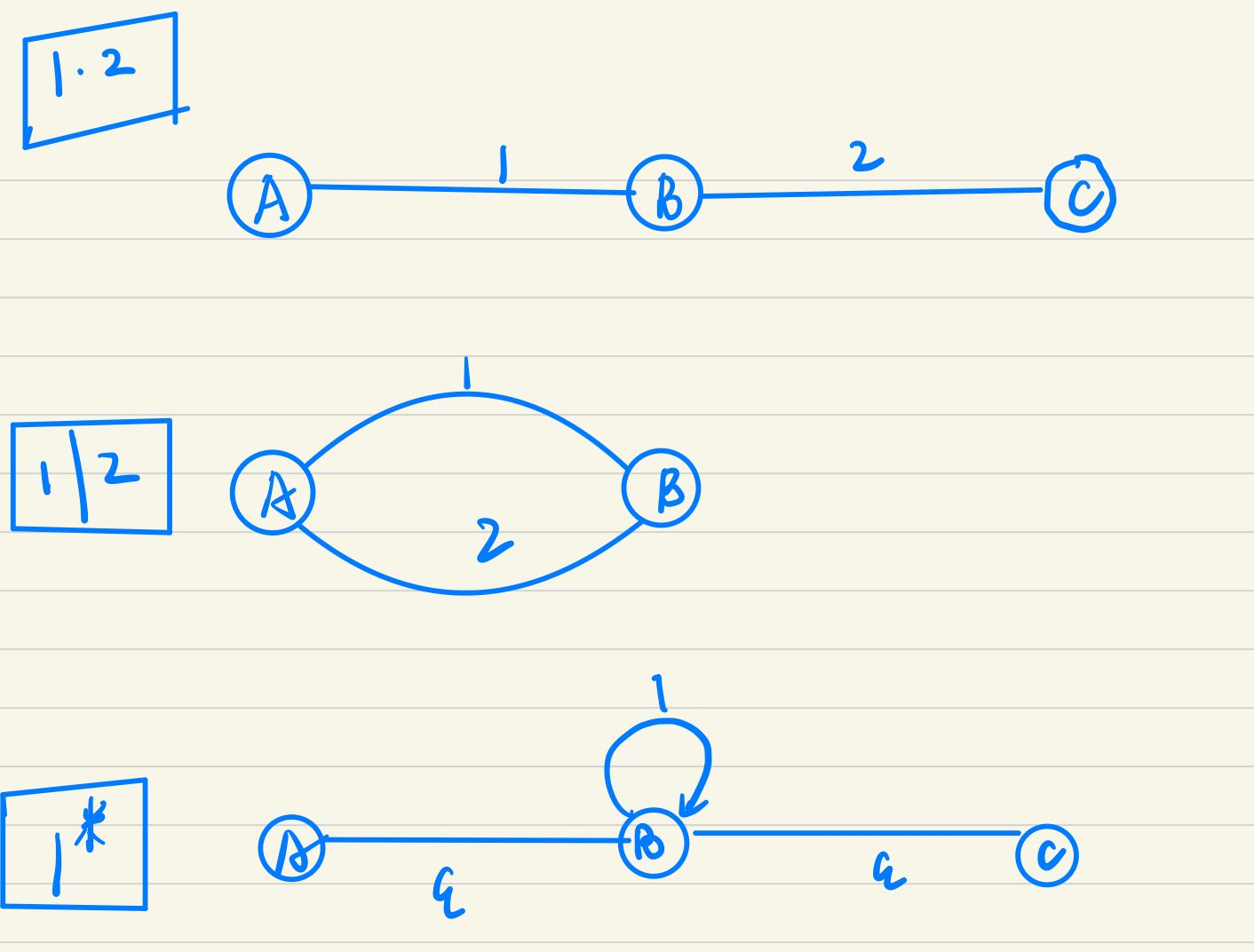
运算符优先级: ∗ > ⋅ > ∣ * > · > | ∗>⋅> ∣
举例子: 1 ( 101 0 ∗ ∣ 1 ( 010 ) ∗ 1 ) ∗ 0 1(1010^{*}|1(010)^{*}1)^{*}0 1(1010∗∣1(010)∗1)∗0
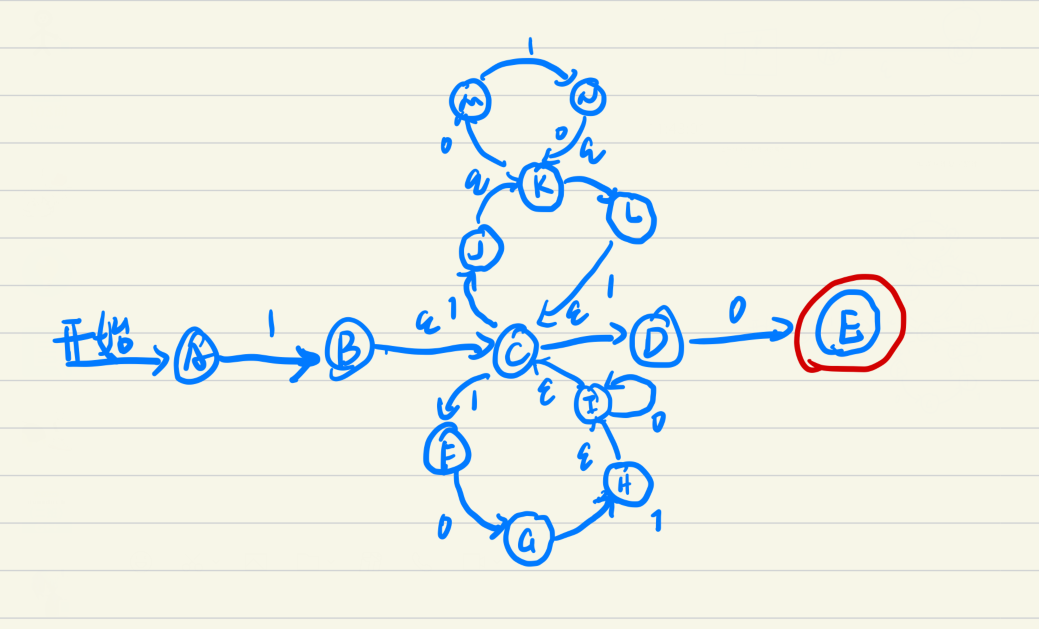
汤森构造法
由于作业里出现过,这里还是需要记录一下
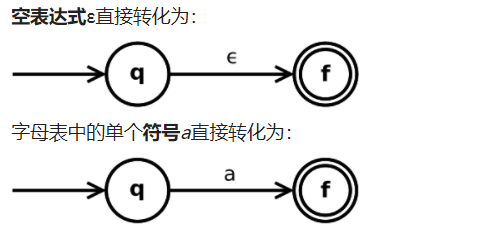
对于单个符号:
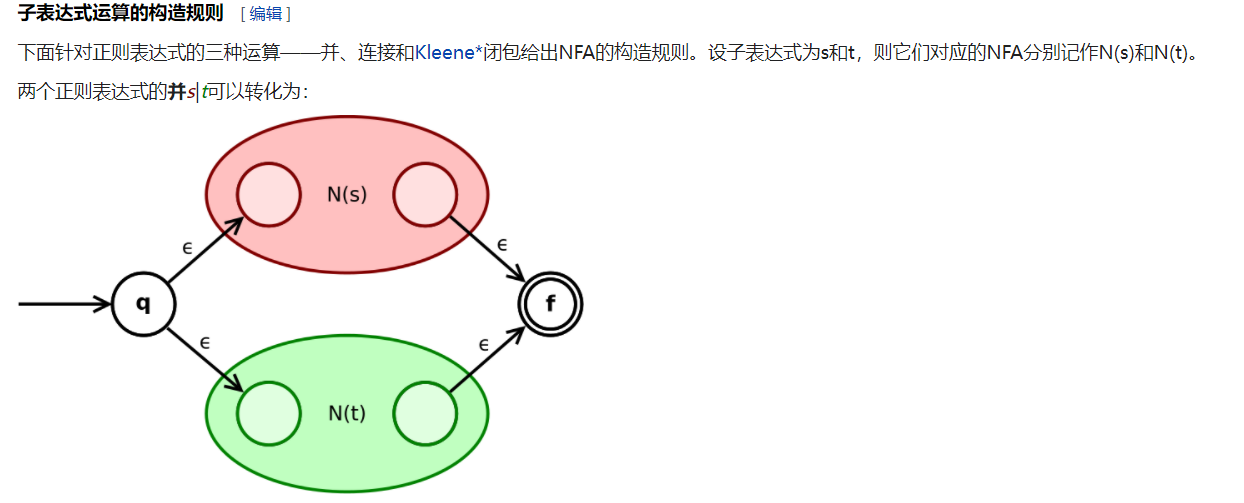
对于选择符号:
对于闭包符号:
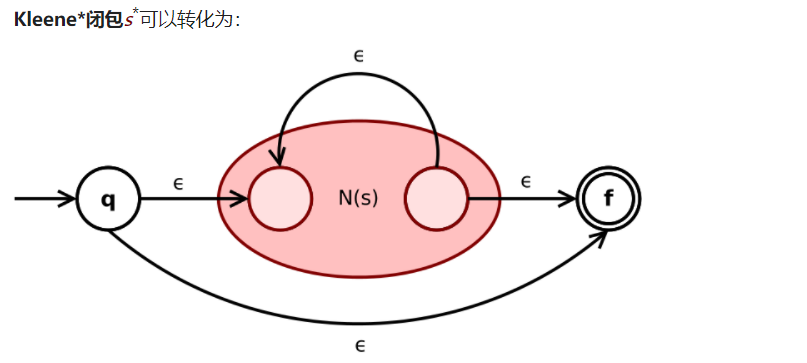
总的来说是先画里面的再画外面的。
一般题目没有说明的话可以直接用自己的构造方法。
NFA转DFA
建表,写出所有的终结符和 ϵ \epsilon ϵ。
对于第一个集合为从起点开始走任意多只能经过 ϵ \epsilon ϵ的节点并放入第一个集合中。
对于第一个集合中的所有节点分别考虑只走 a a a的能到达的节点,若走了 a a a之后再考虑可以走任意多的 ϵ \epsilon ϵ能到达的节点。
以此类推。将新出现的集合依次放到最左边作为开始状态,若该集合已经出现过就不要再放。直接表格不再扩张。
注意初始状态是有自身的节点编号的。
此时对新表进行重新表号,根据经过某终结符能到达的点作为边进行画DFA。



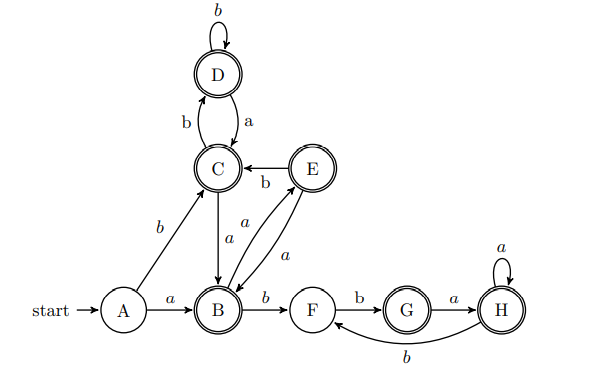
简化DFA
看集合内每个元素通过特定弧达到的元素组成的集合,如果形成的集合不在任何原有集合中的子集中,则一定是新出现的,可以单独划分。对于元素通过有向弧推导出来形成的集合的超集是同一个集合,则为一组。
先把原来的状态划分为终结状态和非终结状态。对于上面的大集合来说,如果集合内部含有终结状态,该集合就是终结集合。反之就是非终结集合。
所以将下面的状态划分为 1 , 2 , 3 1,2,3 1,2,3和 4 , 5 {4,5} 4,5
对于状态1来说:其能到达的集合为 2 , 3 2,3 2,3,为两个非终结状态
对于状态2来说:其能到达的集合为 4 4 4,为一个终结状态
对于状态3来说:其能到达的集合为5,为一个终结状态。
因此状态1划分为一组,状态2和3划分为一组。
即状态为 1 1 1和 2 , 3 2,3 2,3。
而对于终结状态, 4 4 4没有可到达的, 5 5 5也没有可到达的。因此两者仍然在一个状态集合里。
所以最后的集合为 1 1 1和 2 , 3 2,3 2,3和 4 , 5 4,5 4,5


例子2:

非终结状态: 1 , 2 1,2 1,2
终结状态: 3 , 4 , 5 3,4,5 3,4,5
其中 1 1 1到达为一个终结态一个非终结态, 2 2 2到达的就是一个终结态,因此划分为 1 1 1和 2 2 2
对于终结态 3 , 4 , 5 3,4,5 3,4,5,由于 3 3 3可以到达终结态 5 5 5,而 4 , 5 4,5 4,5都没有可到达的状态。因此划分为 3 3 3和 4 , 5 4,5 4,5。
由此最终为 1 1 1和 2 2 2和 3 3 3和 4 , 5 4,5 4,5。

EBNF
EBNF中
[]中的内容表示可以出现一次或0次
{}中的内容表示可以出现多次或0次

对于左递归的部分实际上就是至少取一次lexp。
所以最后一行为 l e x p − s e q − > l e x p { l e x p } lexp-seq->lexp \{lexp\} lexp−seq−>lexp{lexp}
Recursive-Descent(递归下降分析)
简而言之这就是lab1拥有了分析预测表之后干的事情
4.3 Given the grammar
statement→ assign-stmt|call-stmt|other
assign-stmt→identifier:=exp
call-stmt→identifier(exp-list)
[Solution]
First, convert the grammar into following forms:
statement→ identifier:=exp | identifier(exp-list)|other
Then, the pseudocode to parse this grammar:
Procedure statement
Begin
Case token of
identifer : match(identifer);
case token of
:= : match(:=);
exp;
(: match(();
exp-list;
match());
else error;
endcase
other: match(other);
else error;
endcase;
end statement
LL(1)
1.First集合
直接规则:如果
X
−
>
a
.
.
X->a..
X−>a..,则把
a
a
a加入到
F
i
r
s
t
(
X
)
First(X)
First(X)中,如果
X
−
>
ε
X->ε
X−>ε,则ε也加入到
F
i
r
s
t
(
X
)
First(X)
First(X)中。
间接规则:如果
X
−
>
Y
.
.
.
X->Y...
X−>Y...,则把
F
i
r
s
t
(
Y
)
First(Y)
First(Y)中所有非ε的元素加到
F
I
R
S
T
(
X
)
FIRST(X)
FIRST(X)中。
特别的,比如 X − > Y 1 Y 2 Y 3 Y 4 X->Y_{1}Y_{2}Y_{3}Y_{4} X−>Y1Y2Y3Y4,如果 Y 1 Y 2 Y 3 Y_{1}Y_{2}Y_{3} Y1Y2Y3都能推导出ε,则把中 F i r s t ( Y 1 ) , F i s r t ( Y 2 ) , F i r s t ( Y 3 ) , F i r s t ( Y 4 ) First(Y1),Fisrt(Y2),First(Y3),First(Y4) First(Y1),Fisrt(Y2),First(Y3),First(Y4)不含ε的元素都加入到 F i r s t ( X ) First(X) First(X)中。
如若 Y 1 Y 2 Y 3 Y 4 Y_{1}Y_{2}Y_{3}Y_{4} Y1Y2Y3Y4中均含有 ϵ {\epsilon} ϵ,则把 ϵ \epsilon ϵ给加到 F i r s t ( X ) First(X) First(X)中去。
2.FOLLOW集合
①对开始符号
S
S
S,置#于FOLLOW(S)中
②若有
A
−
>
α
B
β
A->αBβ
A−>αBβ(α可为空),则把
F
i
r
s
t
(
β
)
−
ε
First(β)-ε
First(β)−ε加入到FOLLOW(B)中
③若有
A
−
>
α
B
或
A
−
>
α
B
β
A->αB或A->αBβ
A−>αB或A−>αBβ,(α可以为空)且β能够推出ε,则把FOLLOW(A)加入到FOLLOW(B)中
以上的α和β都是字串。
B
B
B是非终结符。
3.判断是否是LL(1)文法
充分必要条件:
①对于文法中每一个非终结符A的产生式的候选首符两两不相交。
如 A − > α 1 ∣ α 2 ∣ α 3 ∣ . . . ∣ α n A->α_{1}|α_{2}|α_{3}|...|α_{n} A−>α1∣α2∣α3∣...∣αn,则 F i r s t ( α i ) ∩ F i r s t ( α j ) = ϕ First(α_{i})∩First(α_{j})=\phi First(αi)∩First(αj)=ϕ
②对于文法中的每个非终结符A,若它产生的某个候选首符包含 ϵ {\epsilon} ϵ,则要求 F i r s t ( A ) ∩ F O L L O W ( A ) = ϕ First(A)∩FOLLOW(A)=\phi First(A)∩FOLLOW(A)=ϕ
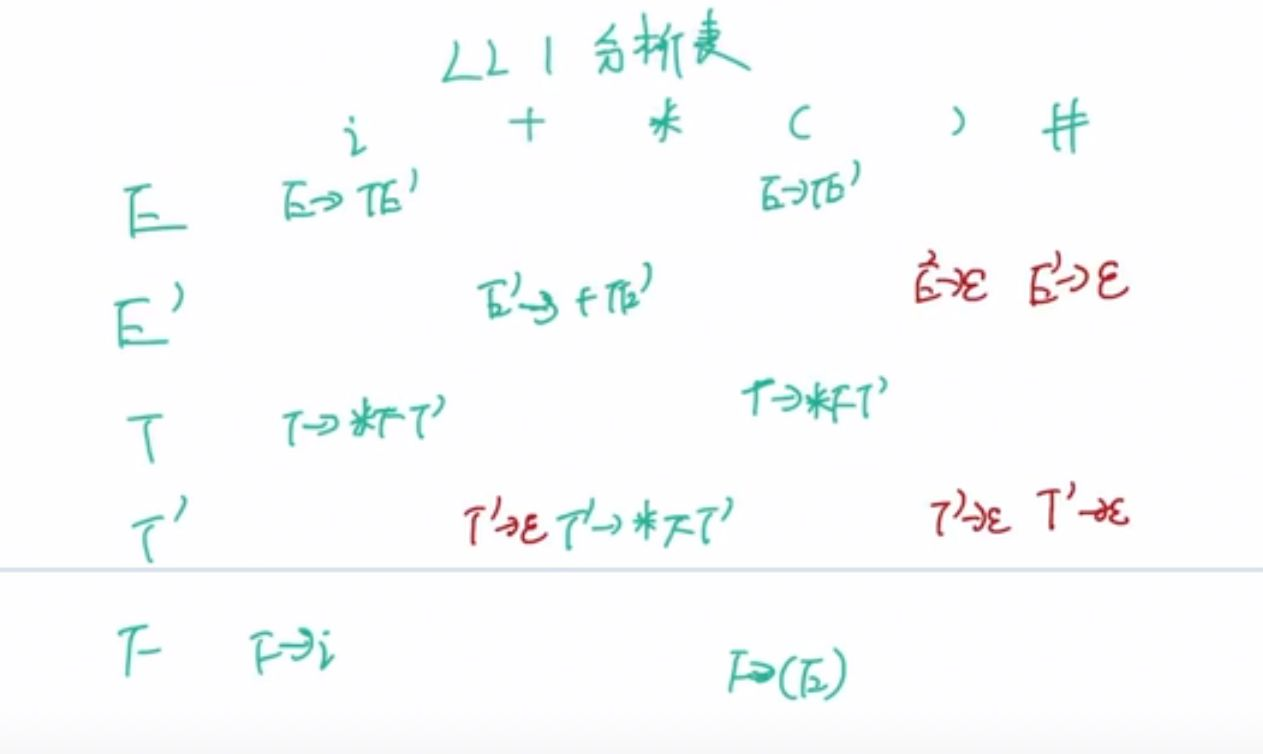
4.构建预测分析表
对于一张二维表来说:
①先不管First(A)中的 ϵ {\epsilon} ϵ,在对应的表项中依据First(A)写上该文法产生式。其中这里如果文法有分支人工去判写哪个分支(想必是看文法两个分支哪个select集里有对应的)。(其实还有再求一个select集的办法,但是我看课件上没有提及)
②再对First(A)中含有 ϵ \epsilon ϵ的进行考虑,看到其Follow(A)中的元素,在该表项填入 A − > ϵ A->{\epsilon} A−>ϵ
LR(0)及SLR(1)
1.LR(0)[直接写一行]
- 改造文法
- 所有项目
- 构建项目规范簇
- 项目规范簇DFA
- ACTION && GOTO(LR(0)分析表)
不存在:
- 既含移进项目又含归约项目
- 含有多个归约项目
例子一:
S->BB
B->aB|b
例子二:
S'->E
E->aA|bB
A->cA|d
B->cB|d
1.改造文法
对于开始符号多加一个文法推导到开始文法。
2.所有项目
列出每条文法的推导集合,写出推导集合的一步步的状态。
3.构建项目规范簇
这里要注意的是,对于同一个状态集合(
I
X
I_{X}
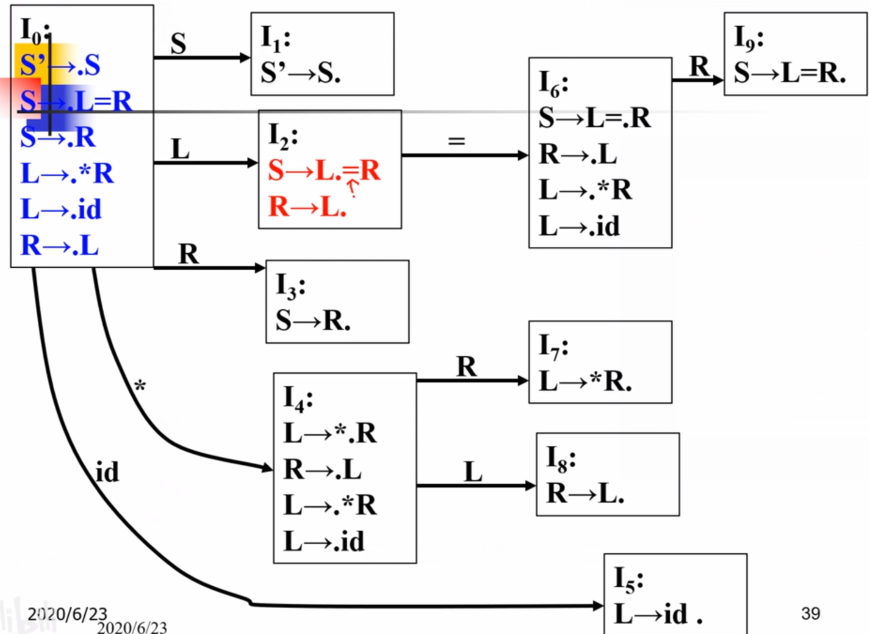
IX)里,其推导CLOUSRE闭包的时候判断**.** 后紧跟的是不是非终结符,如果是则要写出该非终结符能推导出的所有首状态文法。否则就不管。同时注意这里可以推导出自身(在LR(1)情况下可能会多出集合状态,在LR(0)中则可能形成自环状态)。
4.项目规范簇DFA
实际上这部分就是DFA状态之间的推导。对于当前状态能通过某个动作到另一状态,则该当前状态中所有能通过这个动作到达下一个**.**状态。
5.构造分析表
对于构造好的规范簇:
对于.在最后的且是最开始改造的文法,写acc
对于.在最后的且不是最开始改造的文法,对初始文法进行从0开始的标号,此时表中该行填的都是规约符号r[0-9]+
如果DFA上到其他集合是非终结符,则写到GOTO表里去。不然的话看当前状态是否为归约状态,不是则说明要推导到其他状态,是则说明要写成归约状态,归约的状态为该集合的状态。
6.匹配预测表
- 初始化:
s0
# a1a2...an#
- 在一般情况下,假设分析器的格局如下:
s0s1...sm
#X1...Xm aiai+1..an#
-
去表中查,如果此时sm和ai对应的操作是移进操作,就把输入缓冲区的压栈,把后继状态压入状态栈
-
状态就变成了: s0s1...smi #X1...Xmai ai+1...an#
-
-
去表中查,如果此时的sm和ai对应的是归约,那么就用第i个产生式归约。假设此时产生式为 A − > X ( m − ( k − 1 ) ) . . X m A->X_{(m-(k-1))}..X_{m} A−>X(m−(k−1))..Xm
-
状态就变成了: s0s1...sm-k //注意这里是产生式子多长就弹出多少个 #X1...Xm-k A aiai+1..an# //此时发现状态栈少一个元素,我们需要去GOTO表查,如果存在就把对应状态压入状态栈 //查Goto表 s0s1...sm-k i #X1...Xm-k A aiai+1...an#
-
-
如果查的是acc,那么就分析完成
-
剩下就是报错
举例:
注意这里要根据归约的长度弹出相应长度的状态栈,当状态栈此时长度不满足的时候要进行goto表的转移。
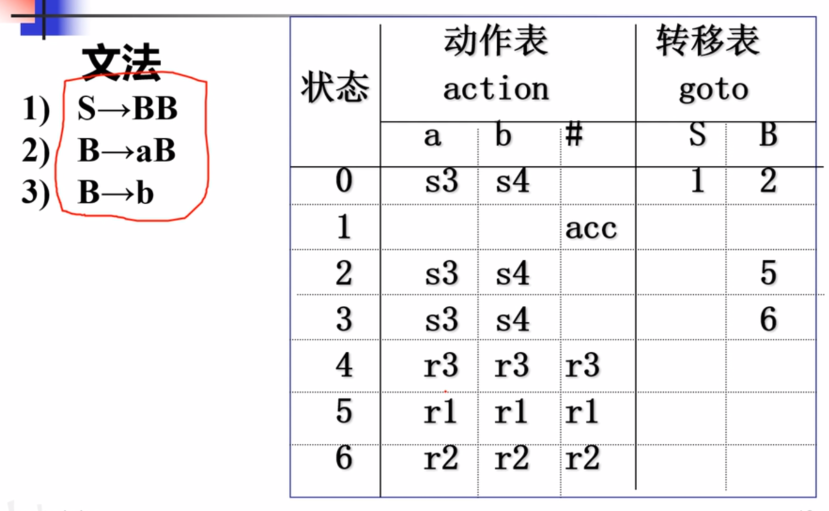

最后的r3,r3,r2,r1连起来的过程就是最右归约的过程。
而主要是找分析栈里的活前缀,每一个出现在分析栈里的都是活前缀。
来自分析栈的活前缀:不包含句柄右侧任意符号的规范句型的活前缀。
例如: i d + i d ∗ i d id+id*id id+id∗id的分析中
-
句型 $ E+id.*id$ 和 E + E ∗ . i d E+ E*.id E+E∗.id
-
第一个句型活前缀为 E + i d E+id E+id
-
第二个句型活前缀为: E + E ∗ E+E* E+E∗
-
右部某个位置标有圆点的产生式称为相应文法的LR(0)项目
移进项目:.后继符号为终结符a,b,c。
S
−
>
.
b
B
B
S->.bBB
S−>.bBB 对应si
待(归)约项目:.后继符号为非终结符。
S
−
>
b
.
B
B
S->b.BB
S−>b.BB,
S
−
>
b
B
.
B
S->bB.B
S−>bB.B
归约项目:.后继符号为空,eg:
S
−
>
A
.
S->A.
S−>A.,
S
−
>
a
.
S->a.
S−>a.
S
−
>
a
B
B
.
S->aBB.
S−>aBB. 对应ri
2.SLR(1)[FOLLOW集合]
题目没让消原来文法的左递归,就不要消。直接在含有递归的文法上求follow本身没有 ϵ \epsilon ϵ是可以不通过first直接求follow的
2.1 SLR(1)的做法
对于同一个集合,如果存在移进-归约冲突,能够解决冲突
移进:B->B.a
归约:B->Ba.
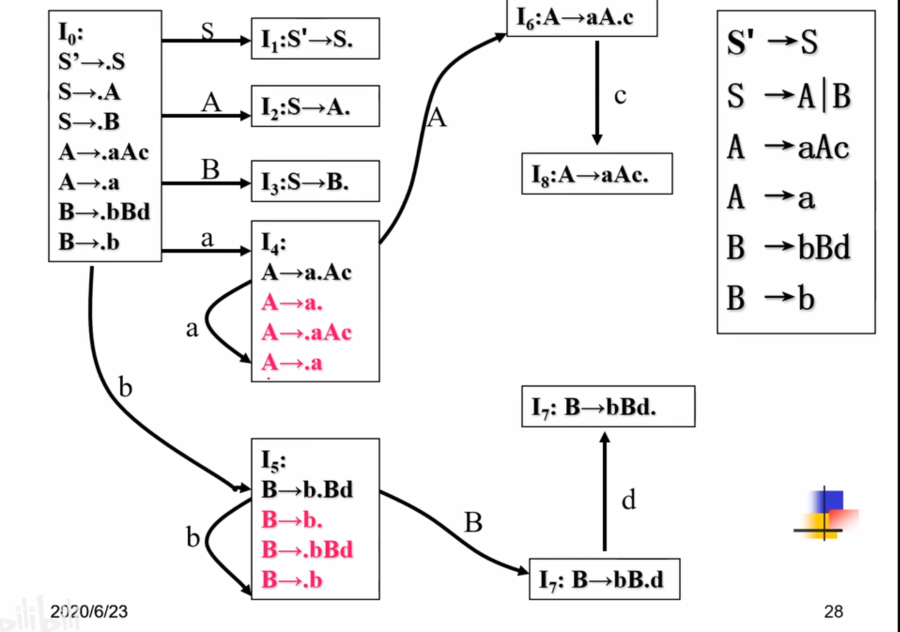
其中I4中既包含归约又包含移进。
按照刚才构造分析表的做法,对于A->a.我们要对该列都填上````r```

但是又包含移进项,比如A->.aAc,结合DFA应该写s4。
这样子就出现了类似用FIRST和FOLLOW写LL(1)预测分析表的时候一个格有两种做法,就有问题了。
原因在于我们一开始就是粗暴的把该列全部写上了归约项,但是实际上并不一定。
比如遇到了输入串的某一部分 A − > a A->a A−>a我们将其视为了句柄,不管后面的比如 A − > a A c A->aAc A−>aAc,不管A后面跟着什么东西都去归约了。
一个做法就是利用FOLLOW集合,看A的FOLLOW集合里面究竟有哪些终结符,排除一些不可能出现在A后面的终结符,可能出现在A后面的位置,那些对应的列才都写上归约。
也就是归约的时候往后看一格,这格是不是在A的follow集合里面,以此来判断是不是应该在对应的位置上写归约这个操作。
这种思路就叫做SLR(1)。
那么我们在之前的算法中做稍微的调整。之前全部列标上归约操作,现在我们看他是不是在FOLLOW里面,不在里面该列该格就不要写归约,在里面的写归约。
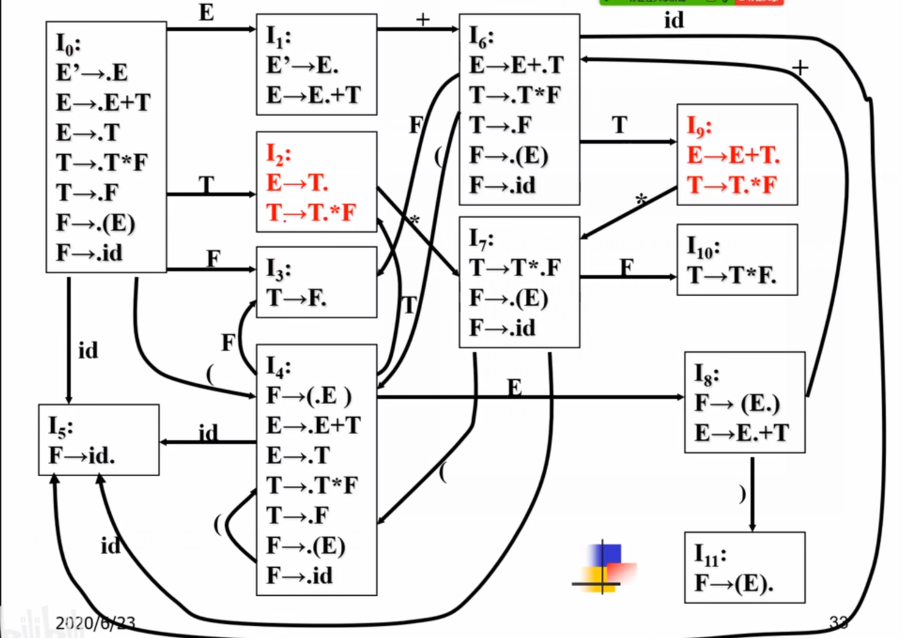
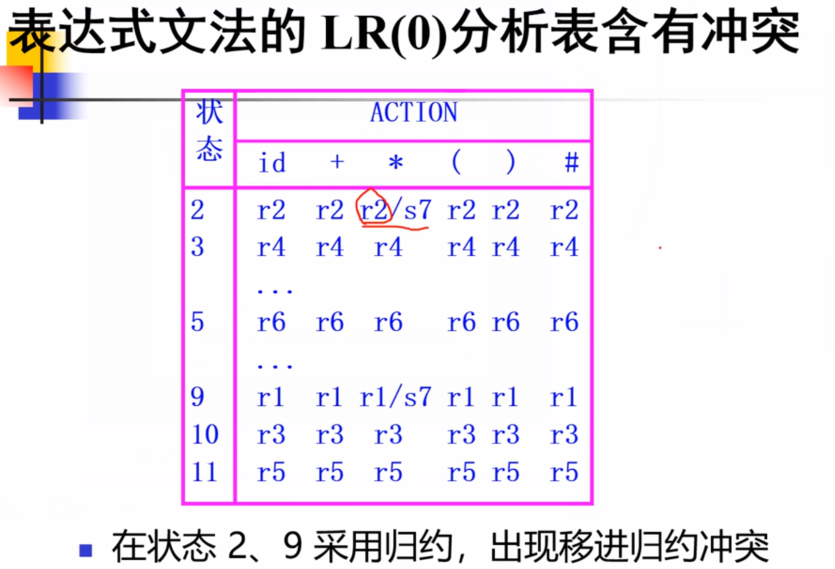
而调整之后:

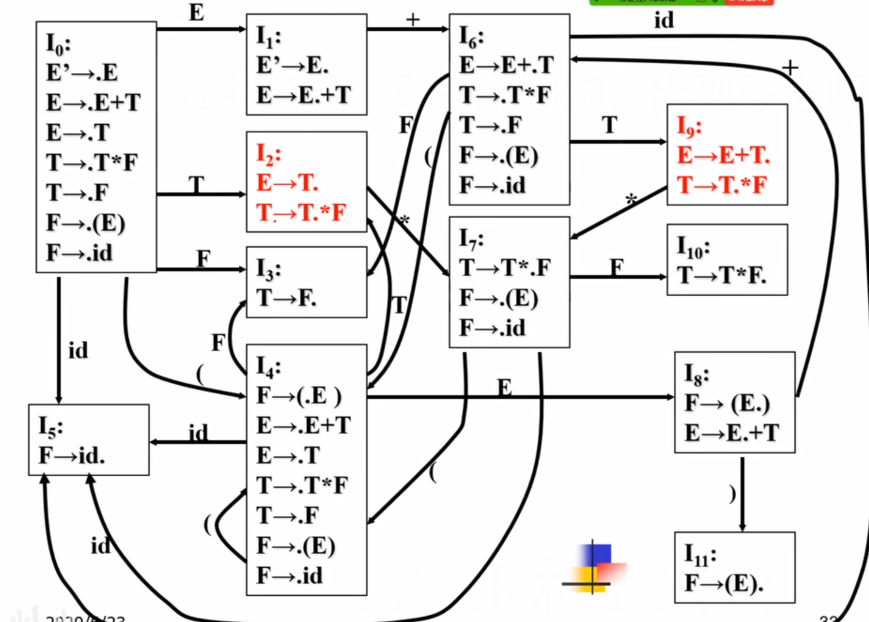
只在FOLLOW(E)里存在的终结符对应的格子写上归约。
T–>T*F.和E–>T.如果在同一个I x _{x} x里面,看Follow(T)和Follow(E)交集是否为空。不为空说明下面的表格里面肯定一项里面有两个做法,程序就不知道怎么走了。
2.2SLR(1)的匹配过程
和LR(0)匹配的过程是一样的。
2.3 SLR(1)的缺陷
如果下一个移进的符号恰好也在归约项目的FOLLOW里。
S − > L . = R S->L.=R S−>L.=R 和 R − > L . R->L. R−>L.
同一个格子里仍然会出现二义性的情况。说明FOLLOW优化还是能被卡掉的。(就像SPFA)需要更强的分析方法,LR(1)和LALR(1)。原因是只考了```FOLLOW``,没有考虑之前的上下文。
SLR文法分析过程可以解决归约-归约冲突,但是不一定能解决移进-归约冲突。
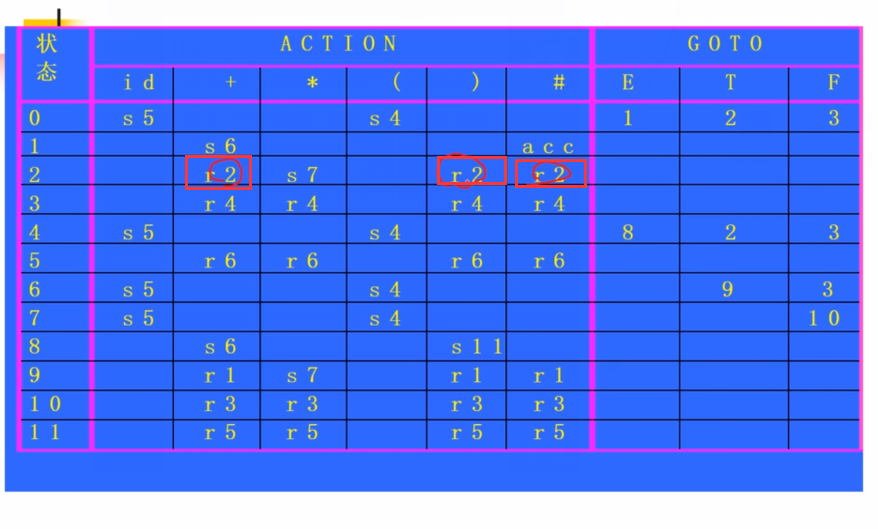
举例:
*不在FOLLOW(E) -->遇到乘号不该归约成E
+在FOLLOW(E) -->遇到+号归约成E
而我们没有考虑E之前的上下文。
S’-(*)-->αE,从开始符S’经过任意多步推导到αE这个状态的时候,+不可能跟在后面。在这种情况下+也不该规约成一个E
/*这里我也不太清楚*/
只要用对应的文法处理做法去做发现该文法没有二义性冲突,说明当前文法可以是该文法。
LR(1)[向前搜索符]
LR(1)的DFA构造
由于多了向前搜索符,所以LR(1)的DFA会在LR(0)的DFA的基础上多出状态,并且原来的连边会产生一定的变化。所以还是要需要重新画DFA的。
LR(1)分析表的构造
向前搜索符的 FIRST 集求法:
求法 FIRST(βa)
- β 表示由谁哪个非终结符推导的,这个非终结符的后面的剩余串
- a 表示它上一个状态中的向前搜索符。
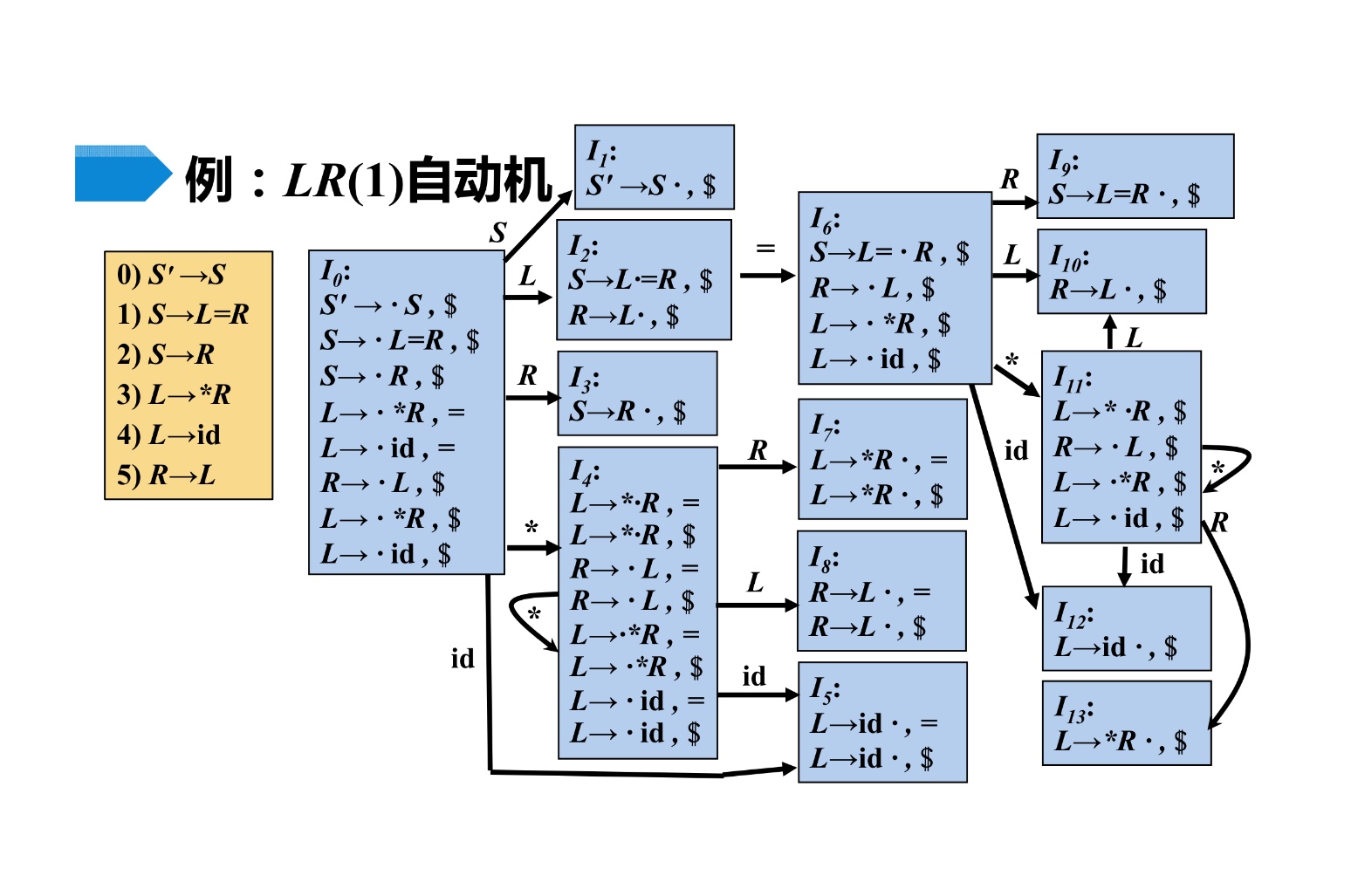
如下图:对于
I
0
I_{0}
I0
首先 $ S’ → .S, # $ 这个是固定的,就是第一个状态的核心项目
下面对 S 求向前所有符都没问题,都是 #
到了 L→.*R,这里,求向前搜索符,使用 FIRST(βa)
应该是求 FIRST(=R#) 所以就是 = 了。后面 $L->. *R ,$
,
是
由
该
式
子
的
上
一
项
,是由该式子的上一项
,是由该式子的上一项R->.L, $$推导出来的。
有两种做法,但是本质一样。
都是一个集合里面不断推导用原先的非终结符继续推导,然后向前搜索符由该式配合产出。该集合推完会有前导部分相同的式子,将他们的向前搜索符合并起来即可。这里大概率会碰到推导出当前 I x I_{x} Ix已经存在的前缀,但是搜索符不同。继续照着规则求下去总会求完。求完再把当前状态相同前缀的合并成一个有多个向前搜索符号的即可。
对于不同集合之前的向前搜索符是继承。
LALR(1)
LALR(1)的构建状态的做法和LR(1)是一样的。最后他把除向前搜索外的前缀一致的集合直接合并起来。然后把向前搜索符也合并,同时注意把到集合的有向边也合并起来。
这是一种推迟错误发生的做法。预测表上看不出差异,实际匹配的时候会碰到error。
Semantic analysis(语义分析)
没咋放例题…主要是书上的例题。然而期末考我没看懂题目考属性文法gg。















 3751
3751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









