







Alluxio1.1与hadoop2.7.3的整合
alluxio介绍
alluxio原名tachyon。
alluxio是一个高容错的分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享,类似spark和MapReduce。通过利用lineage信息,积极使用内存,alluxio的吞吐量要比HDFS高300多倍。alluxio都是在内存中处理缓存文件,并且让不同的Jobs/Queries以及框架都能以内存的速度来访问缓存文件。
特性:
- 类java的文件api
- 兼容性:实现Hadoop文件系统接口
- 可插入式的底层文件系统
- 内建Raw原生表的支持
- 基于Web的UI
- 提供命令行接口
alluxio架构
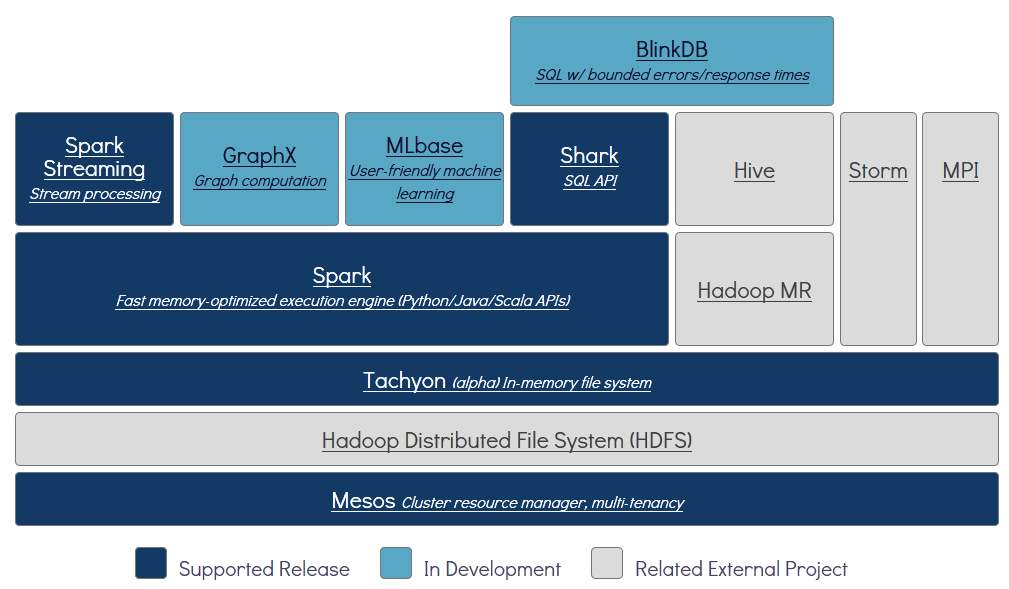

如何进行Alluxio和hadoop(hdfs)的整合搭建
简单的alluxio和hdfs整合是非常简单的。
1.搭建hadoop
这一步,我们不必多说,具体可以参考如何搭建hadoop
2.搭建alluxio
进入alluxio的conf目录,这里存放着alluxio的配置文件
- alluxio-env.sh ,该文件中添加 ALLUXIO_MASTER_HOSTNAME=master(你的master节点的域名),这是要告诉集群,这是你的alluxio-master节点。
- alluxio-site.properties ,该文件中添加 alluxio.underfs.address=hdfs://master:8020 ,这是要告诉集群,alluxio是以hdfs作为底层的文件系统,并且告知集群,hdfs的NameNode的ip和端口。并且告诉集群,alluxio要把hdfs的根目录整个映射到alluxio。
- core-site.xml, 这个只需要把你搭建好配置好的hadoop集群中etc/hadoop/core-site.xml拷贝至此即可,保持一致。
- workers, 该文件中就像hadoop里的slaves一样,添加从节点的域名或ip地址,即可启动从节点。
bin/alluxio format,进行初始化
- bin/alluxio-start.sh all,即可启动master和workers,这里需要注意的是,需要root权限。为了在自建用户下操作,我们可以在/etc/sudoers里,修改配置,简历sudo的免密码。
搭建成功
这样,简单的alluxio和hadoop hdfs的整合就完成了。
我们可以访问master:19999,即alluxio 的WebUI,我们可以看到文件系统与hdfs做了映射。由于在内存中,访问速度是不错的,甚至可以直接通过WebUI读取文件的内容。















 2277
2277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









