







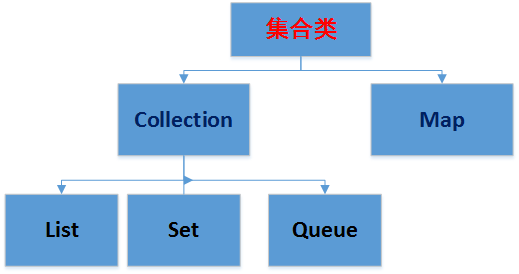
一、Java集合类综述
Java集合类(位于java.util包中)主要有两个接口Collection和Map派生出来,大致分为Set、List、Queue、Map四种体系。
注意:集合中只可以保存对象,不可以保存基本数据类型。
二、Collection
1. Collection和Iterator接口
1.1 Collection中的方法
boolean add(Object o):向集合中添加一个元素。
boolean addAll(Collection c):把集合c中所有元素添加到指定集合中。
void clear():清除集合中所有元素。
boolean remove(Object o):删除集合中指定元素o。
int size():返回集合中元素个数。
boolean contains(Object o):返回集合中是否包含指定元素o。
boolean containsAll(Collection c):返回集合中是否包含集合c中的所有元素。
boolean isEmpty():判断集合是否为空。
boolean retainAll(Collection c):返回两个集合是否有交集。
Object[] toArray():把集合转化为数组。
Iterator iterator():返回一个Iterator对象,用于遍历集合中的元素。
1.2 Iterator遍历数组
迭代器:集合取出元素的方式。
取出方式定义在 集合内部,可以直接访问集合中的元素。
Collection接口extends了Iterable接口,Iterable接口提供了 iterator()方法获取 Iterator类型对象,来遍历集合。
Iterator接口方法:
boolean hasNext():判断被迭代的集合中是否还有下一个元素。
Object next():返回集合中的下一个元素。
void remove():删除集合中上一次next方法返回的元素( 直接修改了集合)。
代码实现:
ArrayList al=new ArrayList();
al.add("java01");
al.add("java02");
al.add("java03");
Iterator it=al.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}2.List
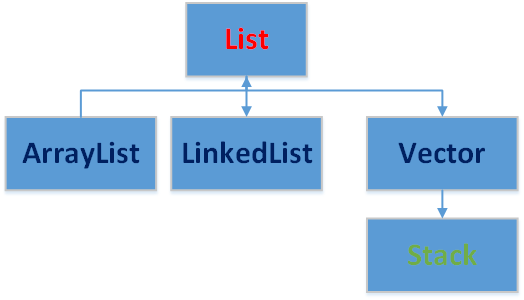
2.1 List介绍
元素是有序的,元素可以重复。因为该集合类有索引。
2.2 List特有方法
增:
add(int index , Object element)
addAll(int index , Collection c)
删:
remove(int index)
改:
set(int index,Object element)
查:
get(int index)
subList(int from , int to)
listIterator()
获取位置:
indexOf(Object obj)
lastIndexOf(Object obj)
……………………………..可爱的分割线………………………………………..
List集合类中特有的迭代器:ListIterator
ListIterator时Iterator的子接口,与Iterator相比,另外实现了增加、修改、反向遍历功能。
代码实现:
ArrayList<String> arrayList=new ArrayList<String>();
arrayList.add("zhao");
arrayList.add("gao");
arrayList.add("qiao");
ListIterator<String> li=arrayList.listIterator();
System.out.println("正向遍历:");
while(li.hasNext()){
//获取某个元素的值
Object obj=li.next();
System.out.println(obj);
if(obj.equals("qiao")){
//修改某个元素值
li.set("zhu");
}else if(obj.equals("gao")){
//删除某个元素
li.remove();
}
//增加某个元素
li.add("duan");
}
System.out.println("逆向遍历:");
while(li.hasPrevious()){
Object obj=li.previous();
System.out.println(obj);
}2.3 ArrayList
底层的数据结构为数组结构。线程不同步。’
去除Arraylist集合对象中重复元素的代码实现:
import java.util.ArrayList;
import java.util.Iterator;
class Person{
private String name;
private int age;
Person(String name,int age){
this.name=name;
this.age=age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
//实现部分(判断元素是否相同使用的是equals()方法)
public boolean equals(Object obj){
if(!(obj instanceof Person))
return false;
else{
Person p=(Person)obj;
return this.name.equals(p.name) && this.age==p.age;
}
}
}
public class ArrayListTest {
public static void main(String[] args) {
ArrayList<Person> al=new ArrayList<Person>();
al.add(new Person("zsw", 23));
al.add(new Person("gnf", 24));
al.add(new Person("gzb", 25));
al.add(new Person("lxg", 26));
al.add(new Person("gzb", 25));
al=singleElement(al);
Iterator<Person> li=al.iterator();
while(li.hasNext()){
Person p=li.next();
System.out.println(p.getName()+"....."+p.getAge());
}
}
public static ArrayList<Person> singleElement(ArrayList<Person> al){
ArrayList<Person> newAl=new ArrayList<Person>();
Iterator<Person> li=al.iterator();
while(li.hasNext()){
Object obj=li.next();
if(!newAl.contains(obj)){
newAl.add((Person)obj);
}
}
return newAl;
}
}2.4 LinkedList
底层的数据结构是链表结构。
同时实现了Deque接口,既可以当做栈也可以当做队列使用。
使用LinkedList模拟队列的代码实现:
import java.util.LinkedList;
class Duilie{
private LinkedList<String> ll;
Duilie(){
ll=new LinkedList<String>();
}
public void add(String str){
ll.addFirst(str);
}
public String get(){
return ll.removeLast();
}
public boolean isEmpty(){
return ll.isEmpty();
}
}
public class LinkedListTest {
public static void main(String[] args) {
Duilie d=new Duilie();
d.add("aa");
d.add("bb");
d.add("cc");
d.add("dd");
while(!d.isEmpty()){
System.out.println(d.get());
}
}
}2.5 Vector
底层数据结构是数组结构。线程同步。
枚举时Vector中特有的取出方式。
代码实现:
Vector<Integer> v=new Vector<Integer>();
v.add(new Integer(11));
v.add(new Integer(12));
v.add(new Integer(13));
Enumeration<Integer> e=v.elements();
while(e.hasMoreElements()){
System.out.println(e.nextElement());
}2.6 Stack
Vector的子类。
表示后进先出(LIFO)的对象堆栈。
方法:
push(Object obj):入栈。
pop():出栈。
peek():取栈顶元素。
empty():测试堆栈是否为空。
search(Object obj):返回对象在堆栈中位置。
2.7 List实现类性能分析
①数组作为底层的ArrayList在随机访问时效率高。
②链表作为底层的LinkedList插入、删除操作时效率高。
③遍历List集合元素,对于ArrayList、Vector使用随机访问方法(get)来遍历;对于LinkedList使用迭代器(Iterator)来遍历。
④多个线程同时访问List中元素,考虑使用Collections工具类将集合包装成线程安全的集合。
3.Set
3.1 Set介绍
元素是无序的,元素不可以重复
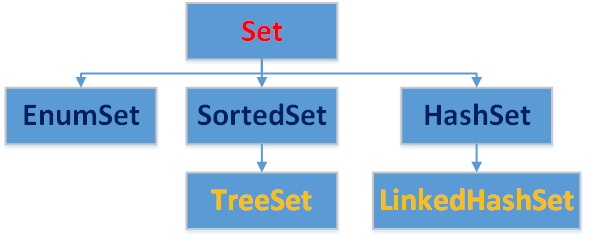
3.2 HashSet
底层数据结构是哈希表,线程是非同步的。
HashSet是如何保证元素唯一的??
通过两个方法:hashCode()和equals(Object obj)。
如果两个元素的hashCode()值相同,才会判断equals(Object obj)是否为true;
如果两个元素的hashCode()值不同,不会调用equals(Object obj)。
HashSet复写hashCode()和equals(Object obj)的代码实现:
import java.util.HashSet;
import java.util.Iterator;
class Person{
private int age;
private String name;
Person(String name,int age){
this.name=name;
this.age=age;
}
public int getAge() {
return age;
}
public String getName() {
return name;
}
public int hashCode(){//复写hashCode()方法
return this.name.hashCode()+age*19;
}
public boolean equals(Object obj){//复写equals()方法
if(!(obj instanceof Person))
return false;
else{
Person p=(Person)obj;
System.out.println(this.name+"."+p.name);
return p.name.equals(this.name)&&p.age==this.age;
}
}
}
public class HashSetTest {
public static void main(String[] args) {
HashSet<Person> hs=new HashSet<Person>();
hs.add(new Person("zsw", 23));
hs.add(new Person("zsw", 23));
hs.add(new Person("gzb", 26));
hs.add(new Person("cya", 18));
Iterator<Person> it=hs.iterator();
while(it.hasNext()){
Person p=it.next();
System.out.println(p.getAge()+"......"+p.getName());
}
}
}
重写hashCode()一般方法:
①把对象中每一个实例变量计算出一个int类型的hashCode值。
| 变量类型 | 计算方式 | 变量类型 | 计算方式 |
| boolean | hashCode=(f?0:1); | float | hashCode=Float.floatToIntBits(f); |
| 整形(byte,short,char,int) | hashCode=(int)f; | double | long l=DoubleToLongBits(f); hashCode=int(l^(l>>>32)); |
| long | hashCode=(int)(f^(f>>>32)); | 引用类型 | hashCode=f.hashCode(); |
②各个实例变量的hashCode值乘以一个质数后相加。
例:f1.hashCode()*31+int(f2)*19;
3.3 TreeSet
底层数据结构是二叉树,线程是非同步的。
可以对集合中的元素进行排序:
方法1:让元素自身具备比较性。
元素需要实现Comparable接口,覆盖compareTo()方法。这种方法称为元素的自然排序。
方法2:让集合自身具备比较性。
定义了比较器,将比较器作为参数传给TreeSet集合的构造函数。
定义一个类,实现Comparator接口,覆盖compare()方法。
代码实现:
import java.util.Comparator;
import java.util.Iterator;
import java.util.TreeSet;
//第一种方法:实现Comparable接口
class People implements Comparable{
private int age;
private String name;
public People(int age, String name) {
this.age = age;
this.name = name;
}
public int getAge() {
return age;
}
public String getName() {
return name;
}
public int compareTo(Object obj){
if(!(obj instanceof People))
throw new RuntimeException("不是人物类型对象");
else{
People p=(People)obj;
if(this.age>p.age)
return 1;
else if(this.age==p.age)
return this.name.compareTo(p.name);
else {
return -1;
}
}
}
}
//第二种方法:定义一个比较器实现Comparator接口
class MyCompare implements Comparator{
public int compare(Object obj1,Object obj2){
People p1=(People)obj1;
People p2=(People)obj2;
int num=new Integer(p1.getAge()).compareTo(new Integer(p2.getAge()));
if(num==0)
return p1.getName().compareTo(p2.getName());
return num;
}
}
public class TreeSetTest {
public static void main(String[] args){
TreeSet<People> ts=new TreeSet<People>(new MyCompare());
ts.add(new People(17,"zsw"));
ts.add(new People(14, "gzb"));
ts.add(new People(19, "cya"));
ts.add(new People(17, "zln"));
ts.add(new People(22, "qyf"));
Iterator<People> it=ts.iterator();
while(it.hasNext()){
People p=it.next();
System.out.println("main:"+p.getAge()+"....."+p.getName());
}
}
}
注意:当两种排序都存在时,以比较器为主。
3.4 LinkedHashSet
线程非同步。
与HashSet相同,也是根据元素的hashCode()值确定元素位置;同时使用链表维护元素次序。
遍历时,会按照元素的添加顺序来访问集合中元素。
代码实现:
package com.zsw.set;
import java.util.LinkedHashSet;
public class LinkedHashSetTest {
public static void main(String[] args){
LinkedHashSet<String> lhs=new LinkedHashSet<>();
lhs.add("zsw");
lhs.add("gzb");
lhs.add("qyf");
System.out.println(lhs);//输出[zsw,gzb,qyg]
lhs.remove("gzb");//移除一个元素
lhs.add("lxg");//插入一个新元素
System.out.println(lhs);//输出[zsw,qyf,lxg]
}
}
3.5 EnumSet
专门为枚举类设计的集合类,线程非同步。
集合元素有序,EnumSet以枚举值在Enum类中的定义顺序来决定集合元素的顺序。
不允许加入null元素。
代码实现
package com.zsw.set;
import java.util.Collection;
import java.util.EnumSet;
import java.util.HashSet;
enum Season{
SPRING,SUMMER,FALL,WINTER
}
public class EnumSetTest {
public static void main(String[] args) {
//allOf()函数创建包含指定枚举类所有枚举值的集合
EnumSet es1=EnumSet.allOf(Season.class);
//noneOf()函数创建一个指定枚举类的空集合
EnumSet es2=EnumSet.noneOf(Season.class);
//of()函数创建包含一个或者多个枚举值的EnumSet集合
EnumSet es3=EnumSet.of(Season.SUMMER,Season.WINTER);
//range(E from,E to)函数创建从from到to范围内所有枚举值的EnumSet集合
EnumSet es4=EnumSet.range(Season.SUMMER, Season.WINTER);
//complementOf(EnumSet s)返回s集合中所没有的枚举值的集合
EnumSet es5=EnumSet.complementOf(es4);
Collection c=new HashSet();
c.add(Season.SPRING);
c.add(Season.FALL);
//copyOf(Collection c)函数使用普通集合(集合中所有元素必须属于同一枚举类)创建EnumSet集合()
EnumSet es6=EnumSet.copyOf(c);
}
}3.6 Set实现类性能分析
①HashSet性能总比TreeSet好;因为TreeSet总需要额外的红黑树(二叉树)算法维护元素次序。
②当需要保持排序时,使用TreeSet.
③LinkedHashSet比HashSet稍微慢一点,因为链表维护的开销。
④EnumSet是Set实现类里性能最好的。
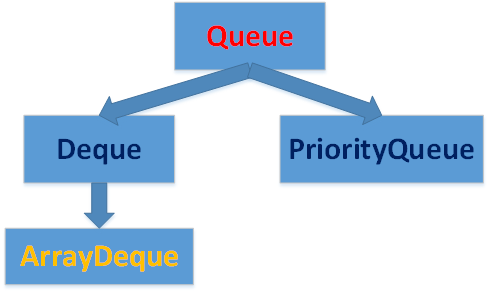
4.Queue
4.1 Queue介绍
Queue用于模拟“队列”,队列指”先进先出”(FIFO)的容器。
常见方法:
void add(Object e):将指定元素加入队列尾部
Object element():获取队列头部元素但不删除
boolean offer(Object e):将指定元素加入队列尾部。对于有容量限制队列效果好。
Object peek():获取队列头部元素但不删除。
Object poll():获取队列头部元素并删除。
Object remove():获取队列头部元素并删除。
4.2 PriorityQueue
PriorityQueue实现类保持队列元素的顺序按照队列元素的大小排序。
排序方法有两种:
自然排序:集合元素实现Comparable接口。
定制排序:队列传入Comparator比较器对象。
与TreeSet排序要求基本一致。
代码实现:
package com.zsw.queue;
import java.util.PriorityQueue;
public class PriorityQueueTest {
public static void main(String[] args) {
// TODO Auto-generated method stub
PriorityQueue pq=new PriorityQueue();
pq.offer(6);
pq.offer(3);
pq.offer(-1);
pq.offer(12);
//依次输出-1,3,6,12
System.out.println(pq.poll());
System.out.println(pq.poll());
System.out.println(pq.poll());
System.out.println(pq.poll());
}
}
4.3 Deque接口
代表一个双端队列,允许从两端操作队列的元素。
可以当做双端队列,也可以当做栈(推荐使用)使用。
4.4 ArrayDeque
Deque接口的实现类,底层数据结构是数组。
ArrayDeque作为”栈”代码展示:
package com.zsw.queue;
import java.util.ArrayDeque;
public class ArrayDequeTest {
public static void main(String[] args) {
ArrayDeque stack=new ArrayDeque();
stack.push("zsw");
stack.push("lxg");
stack.push("gzb");
stack.push("wrg");
System.out.println(stack.pop());
System.out.println(stack.pop());
System.out.println(stack.pop());
System.out.println(stack.pop());
}
}
三、Map
1. Map介绍
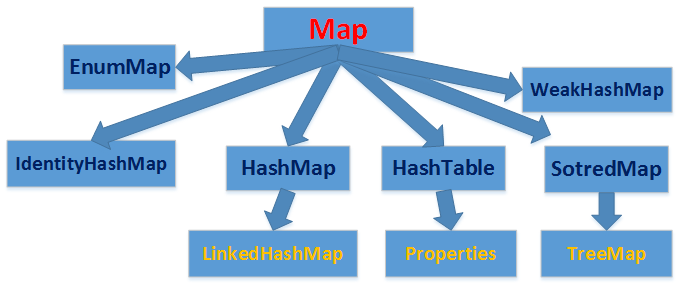
基本方法:
Object put(Object key,Object value):添加一个键值对。
void putAll(Map m):复制指定Map中的键值对。
boolean containsKey(Object key):判断集合中是否包含指定key。
boolean containsValue(Object value):判断集合中是否包含指定value。
Object get(Object key):返回指定key对应的value值。
Object remove(Object key):删除指定key所对应的键值对。
void clear():删除所有键值对。
Set keySet():返回Map集合中所有key组成的Set集合。
Set entrySet():返回Map集合中所有key-value组成的Set集合。
Collection values():返回Map集合中所有value组成的Collection。
int size():返回Map集合的键值对个数。
2. Map集合的取出方式
2.1 keySet()
将Map中所有键存入Set集合;Set集合迭代器迭代取出所有key,使用get(Object key)方法取出value。
代码实现
package com.zsw.quchu;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Set;
public class keySetTest {
public static void main(String[] args){
HashMap<String, String> hm=new HashMap<>();
hm.put("zsw", "23");
hm.put("lxg", "24");
hm.put("gzb", "25");
Set<String> s=hm.keySet();
Iterator<String> it=s.iterator();
while(it.hasNext()){
String name=it.next();
String age=hm.get(name);
System.out.println(name+"....."+age);
}
}
}
2.2 entrySet
将Map集合的映射关系存储到Set集合,Set集合的数据类型是Map.Entry;使用Map.Entry的getKey()和getValue()方法获取key和value。
代码实现
package com.zsw.quchu;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class entrySetTest {
public static void main(String[] args){
HashMap<String, Integer> hm=new HashMap<>();
hm.put("zsw", 23);
hm.put("gzb", 25);
hm.put("qyf", 24);
hm.put("xxx", 12);
Set<Map.Entry<String,Integer>> s=hm.entrySet();
Iterator<Map.Entry<String, Integer>> it=s.iterator();
while(it.hasNext()){
Map.Entry<String, Integer> me=it.next();
System.out.println(me.getKey()+"..."+me.getValue());
}
}
}
3. Map实现类
3.1 Hashtable
底层数据结构式哈希表,无序,线程同步。
key和value都不可以为null。
代码实现
package com.zsw.hashtable;
import java.util.Hashtable;
public class HashtableTest {
public static void main(String[] args) {
Hashtable ht=new Hashtable();
ht.put("zsw", "201511899");
ht.put("qyf", "201411777");
//key和value都不可以为null
//ht.put(null, null);
ht.put("lxg", "201411666");
System.out.println(ht);
}
}3.2 Properties
Hashtable的子类。
键值都是字符串。通常用来处理属性文件。
代码实现
package com.zsw.hashtable;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.util.Properties;
public class PropertiesTest {
public static void main(String[] args)throws Exception {
Properties prop=new Properties();
//load()从文件中加载键值对
prop.load(new FileInputStream("info.ini"));
//getProperty()获取指定属性值
System.out.println(prop.getProperty("zsw"));
//setProperty()设置键值对
prop.setProperty("gzb", "201311888");
//store()输出到指定文件
prop.store(new FileOutputStream("info.ini"), "my comment");
//list()列出属性值列表
prop.list(System.out);
}
}3.3 HashMap
底层数据结构是哈希表 ,无序,线程不同步。
key和value可以为null。
对于HashMap和Hashtable:
①用作key的对象必须实现hashCode()和equals()方法。
②判断两个value值相等的标准:equals()函数返回true。
3.4 LinkedHashMap
是HashMap的子类。
使用双向链表维护键值对的次序;迭代顺序与插入顺序一致。
代码实现
package com.zsw.hashmap;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Set;
public class LinkedHashMapTest {
public static void main(String[] args) {
LinkedHashMap<String, Integer> lhm=new LinkedHashMap<>();
lhm.put("zsw", 23);
lhm.put("qyf", 24);
lhm.put("lxg", 25);
lhm.put("zln", 24);
Set<String> s=lhm.keySet();
Iterator<String> it=s.iterator();
while(it.hasNext()){
String name=it.next();
System.out.println(name+"..."+lhm.get(name));
}
}
}
3.5 TreeSet
底层数据结构是二叉树(红黑树),有序,线程不同步。
两种排序方式:
与TreeSet两种排序方式类似。
代码实现
package com.zsw.treeset;
import java.util.*;
//定制排序
class StuNameComparator implements Comparator<Student>
{
public int compare(Student s1,Student s2)
{
int num=s1.getName().compareTo(s2.getName());
if(num==0)
return new Integer(s1.getAge()).compareTo(new Integer(s2.getAge()));
return num;
}
}
//自然排序
class Student implements Comparable<Student>
{
private String name;
private int age;
Student(String name,int age)
{
this.name = name;
this.age = age;
}
public int compareTo(Student s)
{
int num = new Integer(this.age).compareTo(new Integer(s.age));
if(num==0)
return this.name.compareTo(s.name);
return num;
}
public int hashCode()
{
return name.hashCode()+age*31;
}
public boolean equals(Object obj)
{
if(!(obj instanceof Student))
throw new ClassCastException("类型不匹配");
Student s = (Student)obj;
return this.name.equals(s.name) && this.age==s.age;
}
}
class TreeSetTest
{
public static void main(String[] args)
{
TreeMap<Student,String> tm = new TreeMap<Student,String>(new StuNameComparator());
tm.put(new Student("alisi0",21),"beijing");
tm.put(new Student("dlisi6",22),"shanghai");
tm.put(new Student("blisi5",23),"nanjing");
tm.put(new Student("elisi4",24),"wuhan");
Set<Map.Entry<Student,String>> entrySet = tm.entrySet();
Iterator<Map.Entry<Student,String>> iter = entrySet.iterator();
while(iter.hasNext())
{
Map.Entry<Student,String> me = iter.next();
Student stu = me.getKey();
String addr = me.getValue();
System.out.println(stu+"......"+addr);
}
}
}
3.6 WeakHashMap
WeakHashMap中每个key对象只持有对实际对象的弱引用,因此,当垃圾回收了该keys所对应的实际对象后,WeakHashMap会自动删除该key对应的键值对。
代码展示
package com.zsw.weakhashmap;
import java.util.WeakHashMap;
public class WeakHashMapTest {
public static void main(String[] args) {
WeakHashMap<String, String> whm=new WeakHashMap<>();
//两个key都是匿名字符串对象(没有其他引用)
whm.put(new String("China"), new String("Chinese"));
whm.put(new String("Japan"), new String("Japanese"));
//字符串对象
whm.put("America", "English");
//垃圾回收
System.gc();
System.runFinalization();
//只会输出{America=English}
System.out.println(whm);
}
}3.7 IdentityHashMap
实现机制与HashMap类似。
key和value允许为null。
当且仅当两个key严格相等时(key1==key2),才可以认为两个key相等。
代码实现
package com.zsw.identityhashmap;
import java.util.IdentityHashMap;
public class IdentityHashMapTest {
public static void main(String[] args) {
IdentityHashMap<String, Integer> ihm=new IdentityHashMap<>();
//这两个key不满足严格相等
ihm.put(new String("math"), 89);
ihm.put(new String("math"), 98);
//字符串常量在常量池只有一份,满足严格相等
ihm.put("java", 93);
ihm.put("java", 66);
//输出{math=89, java=66, math=98}
System.out.println(ihm);
}
}
3.8 EnumMap
所有key都必须是单个枚举类的枚举值。
内部以数组形式保存。
按照key自然顺序(枚举类中顺序)维护key-value顺序。
key不允许为null,value允许为null。
代码实现
package com.zsw.enummap;
import java.util.EnumMap;
import java.util.EnumSet;
enum Season{
SPRING,SUMMER,FALL,WINTER
}
public class EnumMapTest {
public static void main(String[] args) {
EnumMap<Season, String> em=new EnumMap<>(Season.class);
em.put(Season.SPRING, "chuntian");
em.put(Season.WINTER, "dongtian");
em.put(Season.SUMMER, "xiatian");
//自然顺序输出{SPRING=chuntian, SUMMER=xiatian, WINTER=dongtian}
System.out.println(em);
}
}3.8 性能分析
①Hashtable和HashMap比TreeSet要快,因为TreeSet使用红黑树。
②TreeSet的好处是有序。
③LinkedHashMap比HashMap慢一点,因为它需要链表保持键值对添加顺序。
③EnumSet性能最好。
四、Collections工具类
1.介绍
操作Set、List、Map等集合的工具类,都是静态方法。
2.排序
void reverse(List list):反转list集合中元素顺序。
void shuffle(List list):对list集合中元素随机排序。
void sort(List list):对list集合元素按照升序排序。
void sort(List list,Comparator c):根据比较器顺序对集合排序。
void swap(List list,int,int j):对list集合中i处和j处元素互换。
void rotate(List list,int distance):当distance为正数时,将list集合的后distance个元素移到前面;当distance为负数时,将list集合前distance个元素移到后面。
3. 查找替换
int binarySearch(List list,Object key):二分法搜索list集合中key的位置,必须list处于有序状态。
Object max(Collection coll):根据自然顺序返回最大元素。
Object min(Collection coll):根据自然顺序返回最小元素。
Object max(Collection coll,Comparator comp):按照比较器指定顺序返回最大元素。
Object min(Collection coll,Comparator comp):按照比较器指定顺序返回最大元素。
void fill(List list,Object obj):使用obj替换list中所有元素。
int frequenc(Collection coll,Object o):返回指定集合中指定元素出现次数。
boolean replaceAll(List list,Object new,Object old):使用新值替换指定集合所有旧值。
4.同步控制
Collections提供了了多个synchronizedXxx()方法,解决多线程并发访问的线程安全问题。
代码实现:
package com.zsw.collections;
import java.util.*;
public class CollectionsTest {
public static void main(String[] args) {
Collection c=Collections.synchronizedCollection(new ArrayList());
List list=Collections.synchronizedList(new ArrayList());
Set s=Collections.synchronizedSet(new HashSet());
Map m=Collections.synchronizedMap(new HashMap());
}
}
********************************end************************************















 1172
1172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









